
第 20 章:系统架构与工程实践
“算法只是冰山一角,工程才是水面下的巨兽。”
恭喜你,你已经掌握了无监督学习的所有核心算法。
但在实际工作中,写出算法代码可能只占 10% 的时间。
剩下的 90% 时间,你在处理:数据管道、异常恢复、性能优化、成本控制。
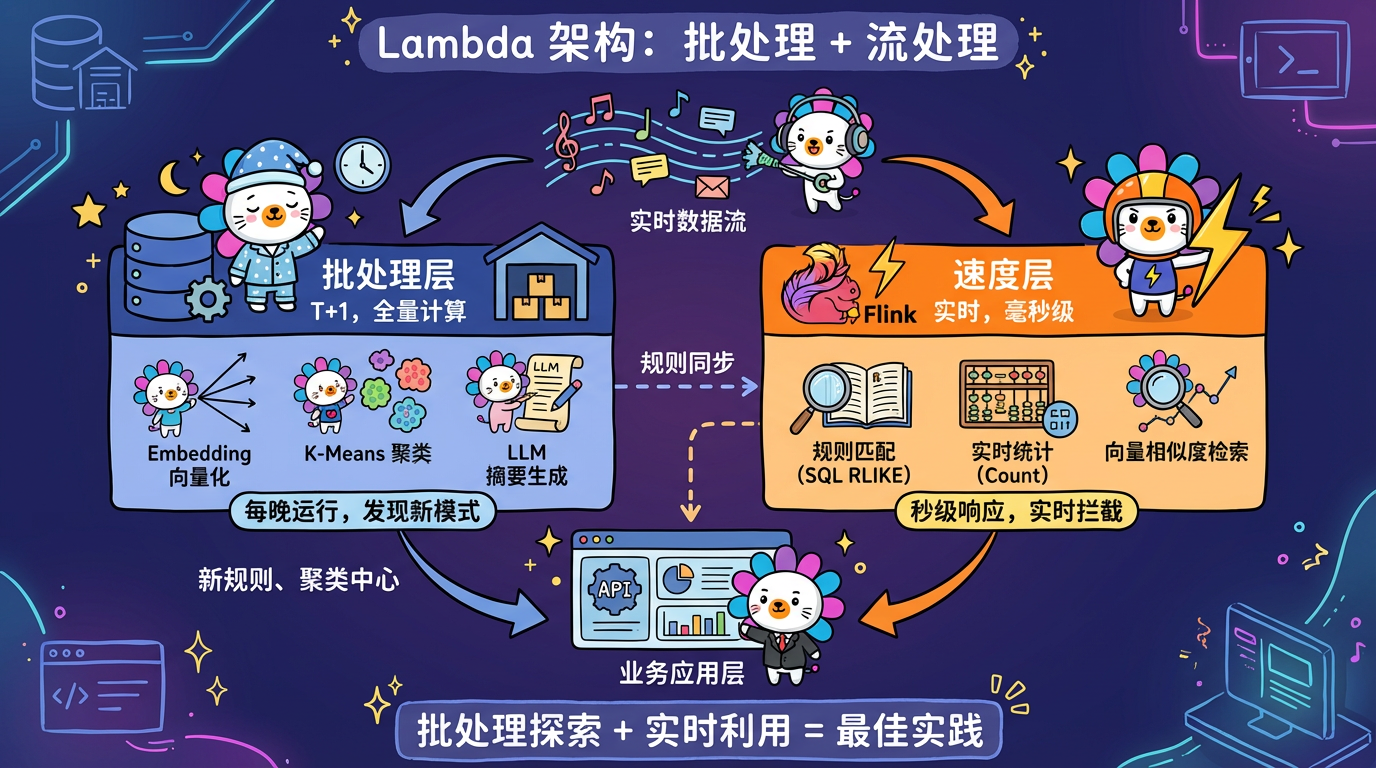
本章将以一个典型的文本分析系统为例,剖析工业级数据挖掘系统的架构设计。
1. 核心概念:批处理 vs 流处理
1.1 批处理 (Batch Processing)
* 模式:T+1。每天凌晨把昨天的数据全量跑一遍。
* 适用:Embedding, KMeans, LLM 总结。这些算法很重,没法实时跑。
* 常见选择:文本分析系统通常采用批处理。因为”风险挖
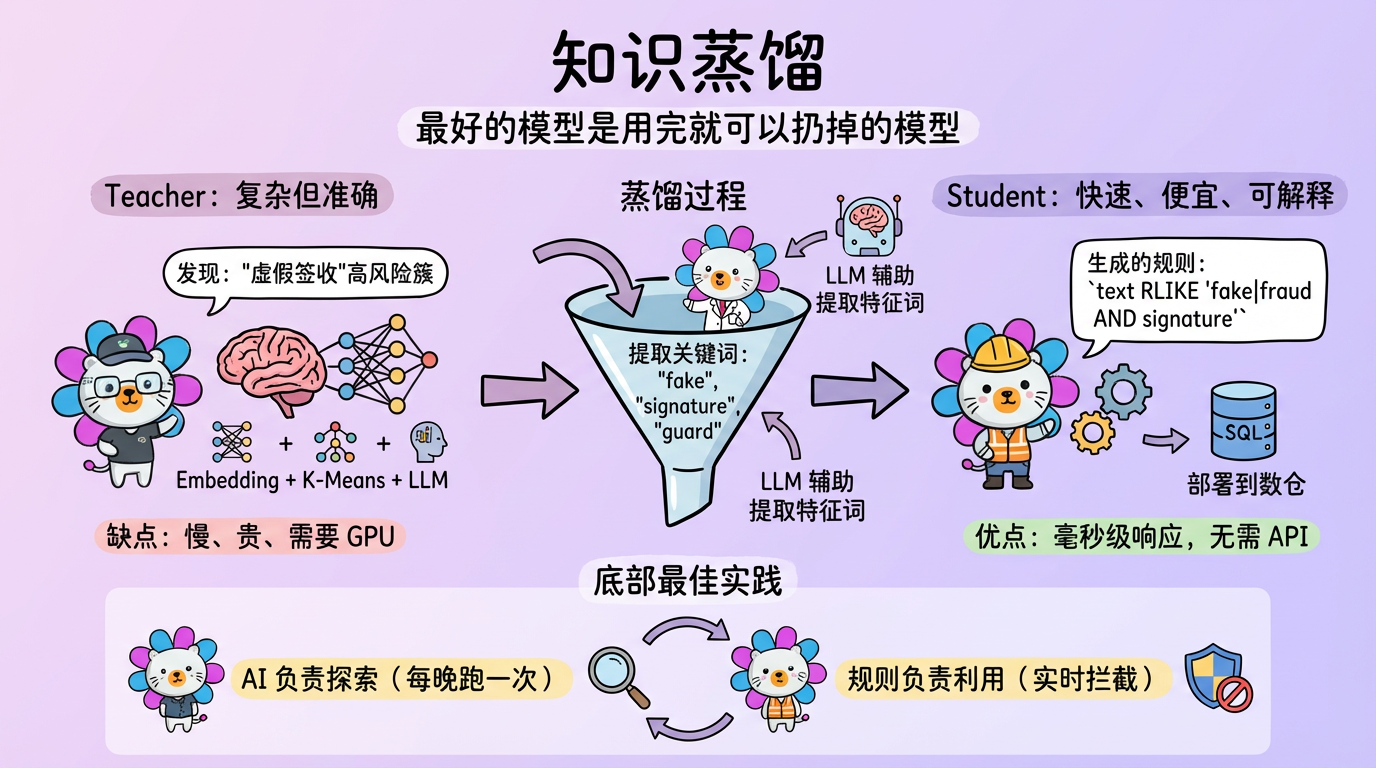
第 19 章:从模型到规则:知识蒸馏
“最好的模型,是用完了就可以扔掉的模型。”
在 Python 里跑完聚类和 LLM 之后,我们得到了深刻的洞察。
但 Python 脚本难以处理亿级的实时数据流。
我们需要把 Python/AI 学到的知识,转移到更轻量级、更高效的系统(如 SQL 引擎、规则引擎)中去。
这一过程被称为 知识蒸馏 (Knowledge Distillation),或者更具体地说,规则提取 (Rule Extraction)。
1. 核心概念:Model-to-Rule
1.1 为什么需要规则?
1. 性能:SQL RLIKE 比 Embedding 快一万倍。
2. 成本:不需要调 API,不需
第 18 章:大语言模型在数据分析中的应用
“以前我们教机器学数学,现在我们教机器读课文。”
在传统的无监督学习流程中,最大的痛点是“结果不可读”。
* 聚类结果:Cluster_42。
* 异常结果:Anomaly_Score = 98.5。
* 业务人员:???
在大模型 (LLM) 时代,我们有了一种全新的范式:使用 LLM 作为这一流程的“解释层” (Interpretation Layer)。
1. 核心概念:LLM 的三种角色
在数据分析链路中,LLM 可以扮演三种角色:
1.1 摘要员 (Summarizer)
这是最基础的用法。
* 输入:Cluster 42 中的 50 条工单文本。
* Pr
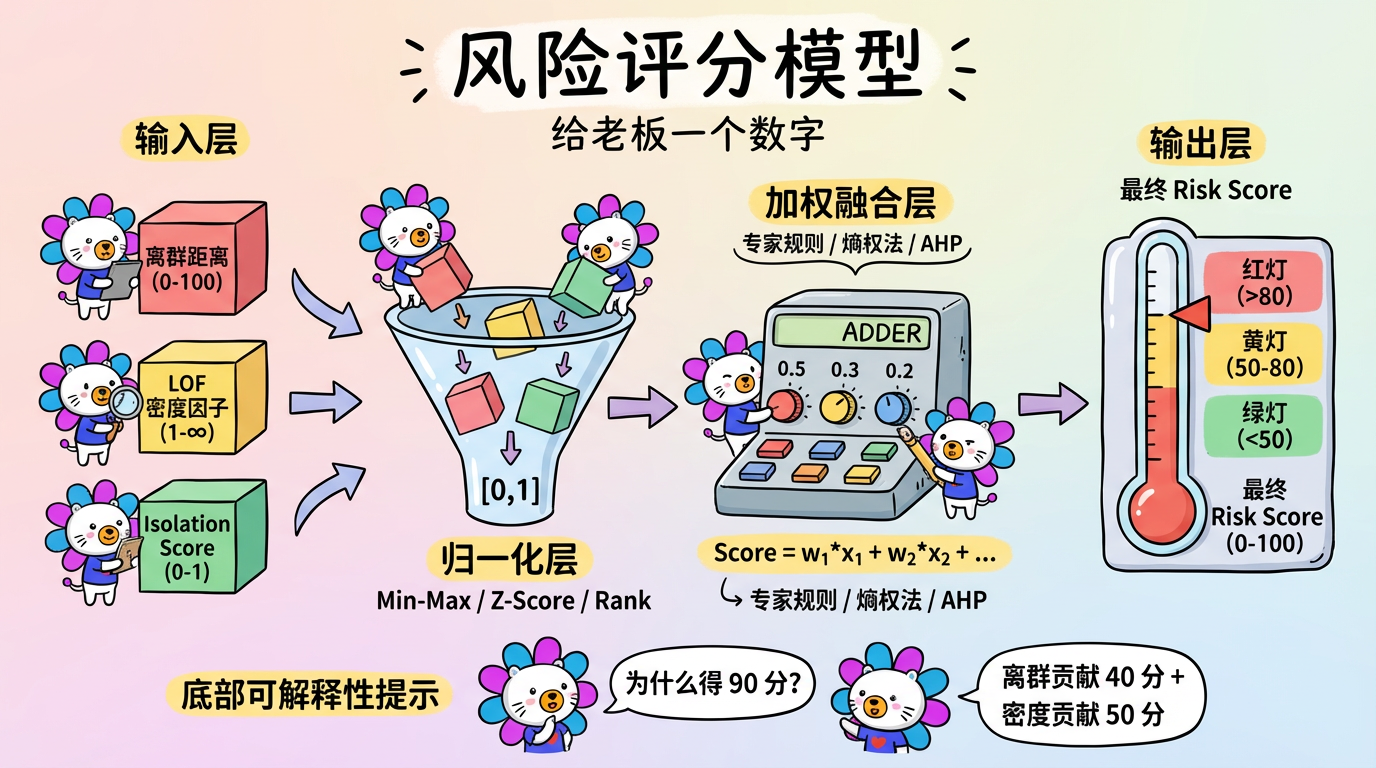
第 17 章:风险评分模型设计
“给我一个数字,我就能撬动地球。—— 前提是这个数字已经归一化了。”
在前面的章节中,我们学习了各式各样的异常检测算法,它们会吐出各种数字:
* K-Means:离群距离 (Distance)。单位可能是米、元、或者抽象的欧氏距离。
* LOF:局部离群因子 (Factor)。通常大于 1,没有上限。
* Isolation Forest:异常概率/分数 (Score)。通常在 0 到 1 之间。
但老板和业务方不想看这些天书。他们只想知道:
“这个用户的风险是 85 分(高危),还是 20 分(安全)?”
这就需要我们构建一个 风险评分模型 (Risk Scoring Mode
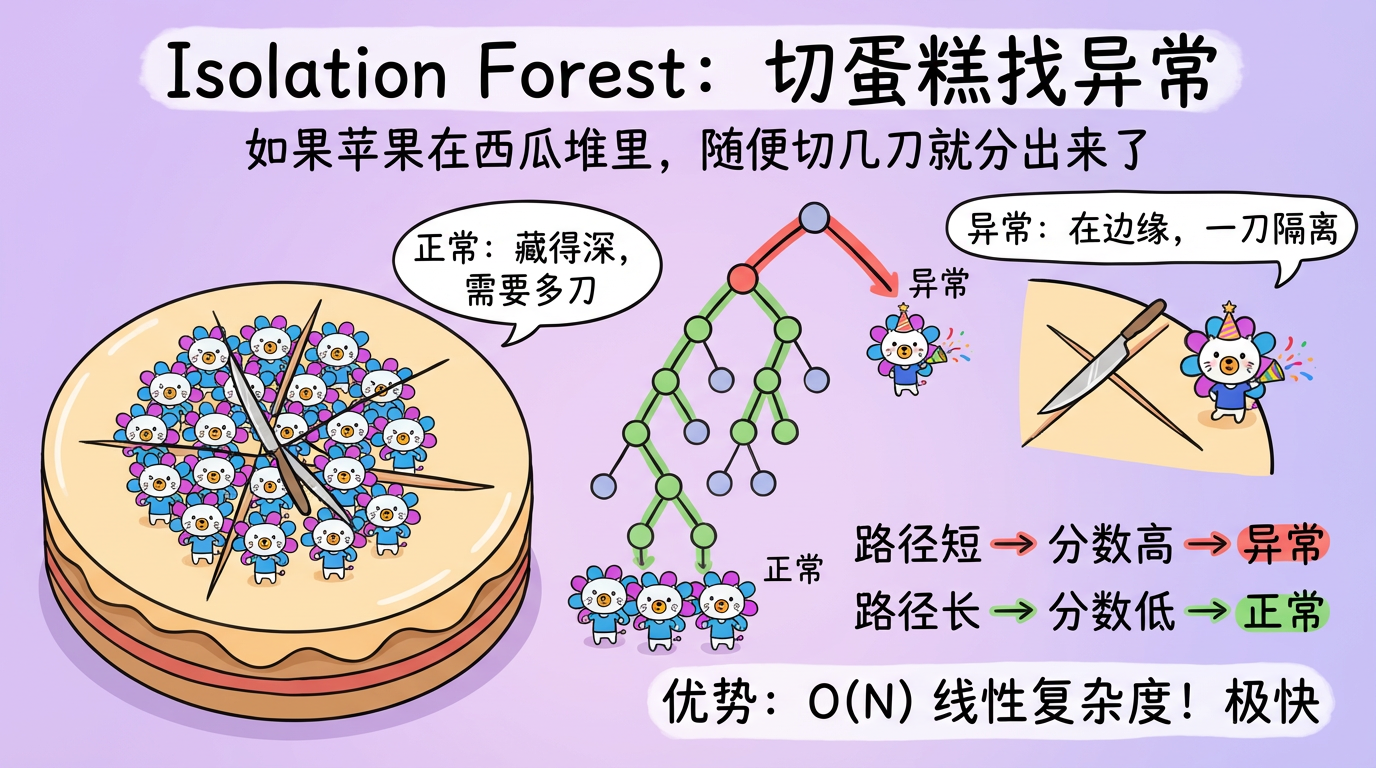
第 16 章:模型驱动异常检测
“如果你想把一个苹果从一堆西瓜里分出来,你不需要描述苹果长什么样,你只需要切几刀。”
前两章我们讨论了基于统计(Z-Score)和距离(KNN, LOF)的异常检测。
但在大数据时代,它们都有一个致命伤:慢。
计算距离矩阵是 $O(N^2)$ 的复杂度。如果你有 100 万条数据,计算量就是 $10^{12}$ 次。即使是现在的超算也得跑很久。
本章我们将介绍基于模型的方法,特别是工业界的神器——隔离森林 (Isolation Forest)。它不计算距离,而是通过“随机切割”来快速锁定异常。它的复杂度是 $O(N)$,线性的!
(图注:左图:正常点深埋在中心,需要切很多刀才能分离。右
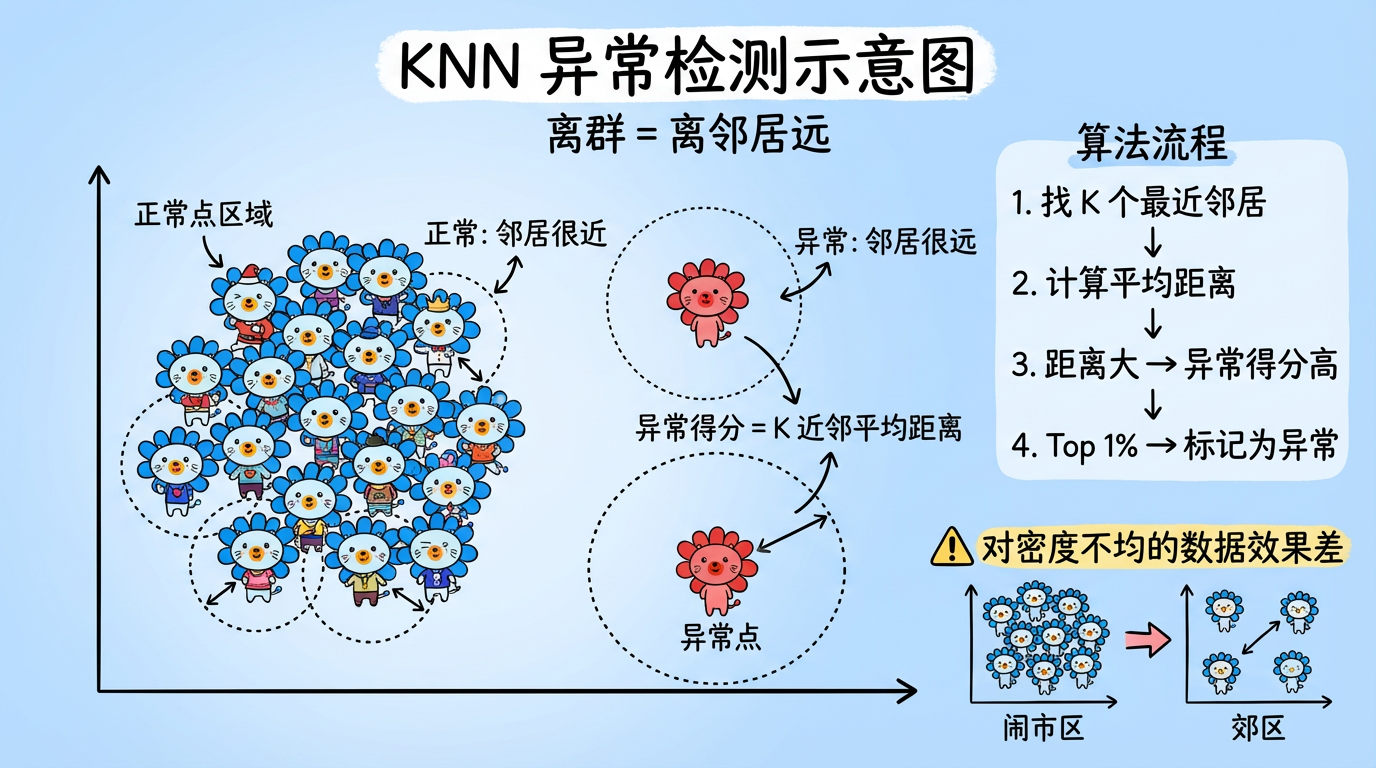
第 15 章:基于距离与密度的异常检测
“离群并不意味着你是错的,只意味着你是孤独的。”
上一章的统计方法(Z-Score)假设数据服从某种分布(如正态分布)。但在现实世界中,数据的形状可能千奇百怪(如双螺旋、甜甜圈、不规则的多簇)。
这时候,任何假设分布的模型都会失效。我们需要回归几何直觉:
异常点就是那些离大家都远的点。
本章将介绍两类不依赖分布假设的算法:KNN(看距离)和 LOF(看密度)。
1. KNN 异常检测:简单的力量
KNN (K-Nearest Neighbors) 不仅可以做分类,也可以做异常检测。
它的逻辑非常朴素:如果你的 K 个最近邻居都离你很远,那你就是异常点。
(图注:正常点 A 的邻
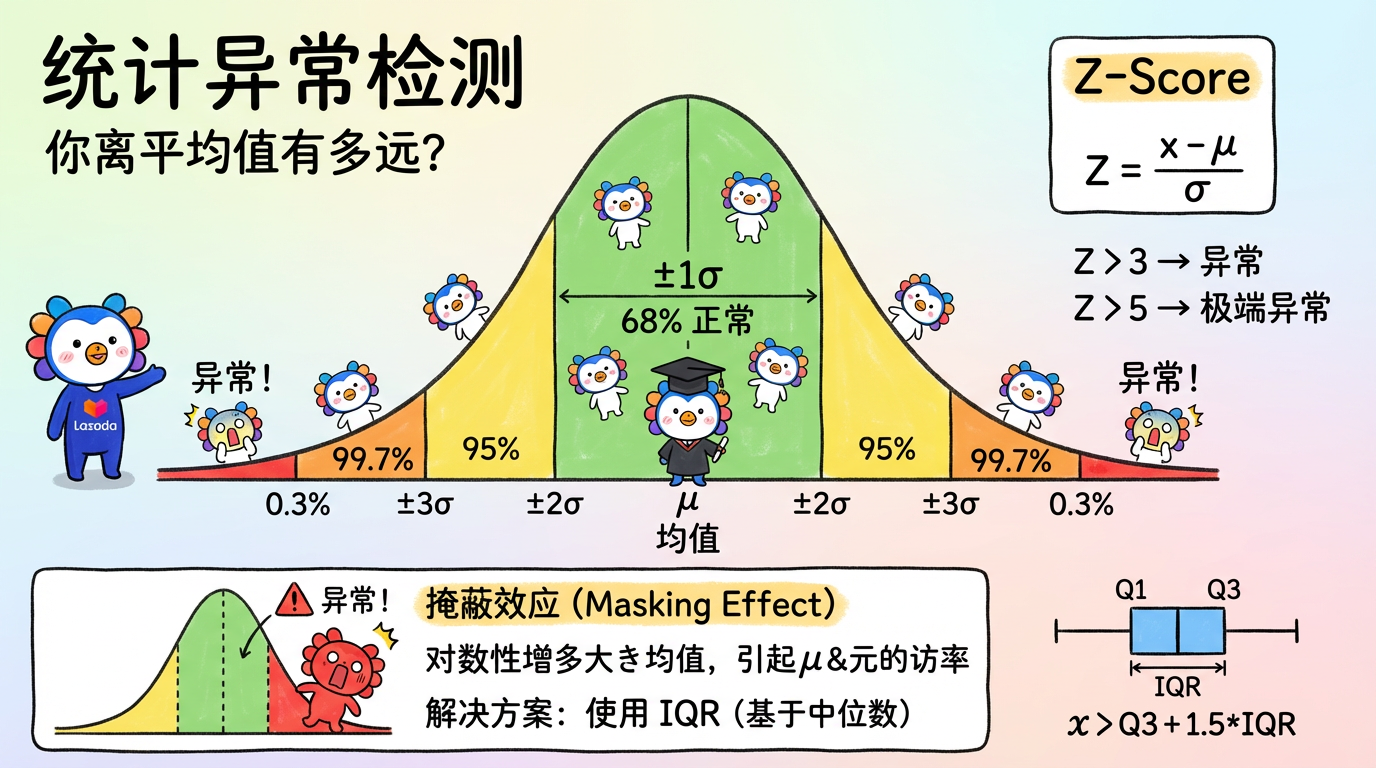
第 14 章:统计异常检测
“虽然每片雪花都是独一无二的,但有些雪花实在是太独特了。”
在文本分析项目中,我们的目标不仅是聚类(发现常态),更是风险挖掘。
什么是风险?风险通常意味着“异常”。
* 大部分工单都在说“快递慢”(常态)。
* 突然有一条工单说“快递员在门口放火”(异常)。
如何用数学定义“异常”?最古老也最经久不衰的方法是统计学。
统计学告诉我们:“正常”就是大多数,“异常”就是极少数。
(图注:在正态分布中,落在 3σ 之外的区域就是异常区。)
1. 核心概念:你离平均值有多远?
1.1 正态分布假设 (The Normal Assumption)
统计方法的核心假设是:正常数据服从
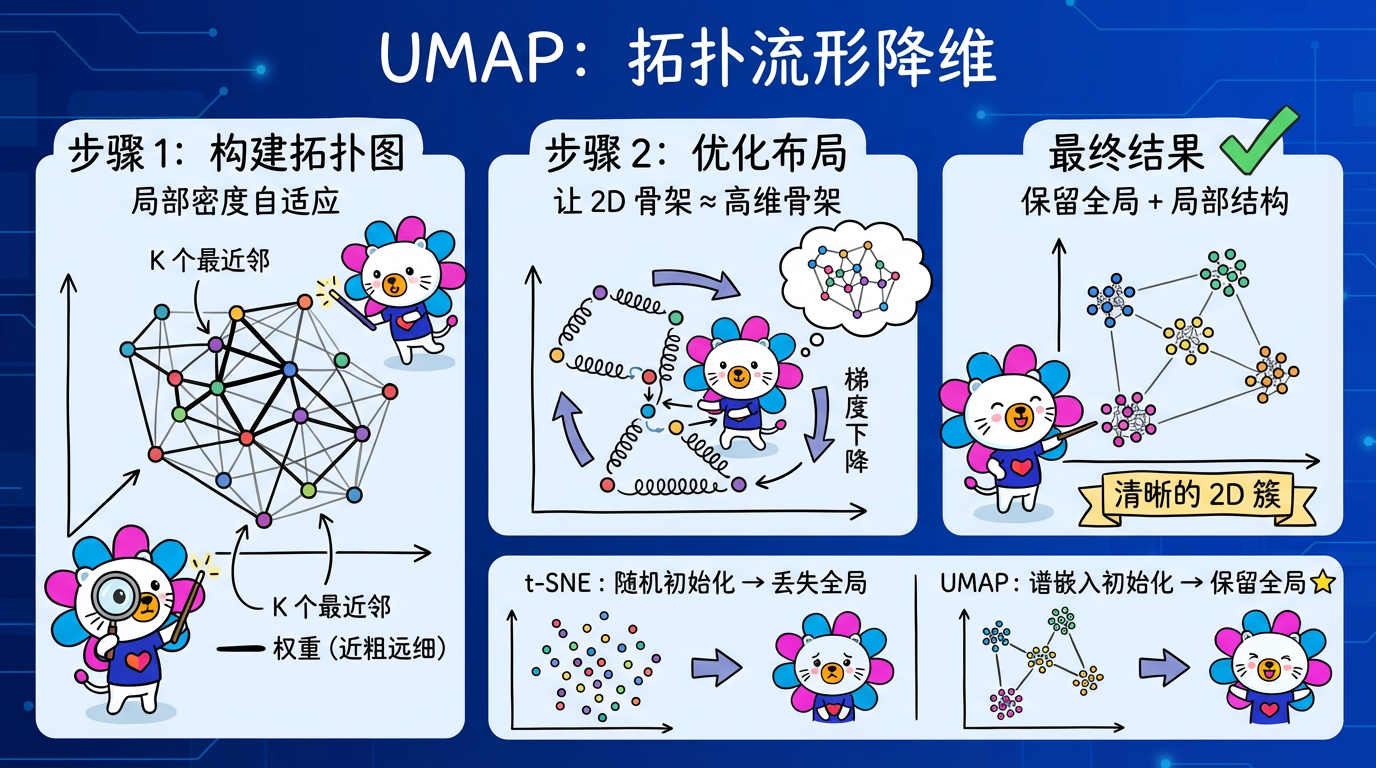
第 13 章:UMAP原理与实践
“数学家在咖啡杯和甜甜圈之间看到了同伦,UMAP 在高维数据和二维流形之间看到了同构。”
t-SNE 统治了数据可视化界很多年,直到 2018 年 McInnes 等人提出了 UMAP。
UMAP (Uniform Manifold Approximation and Projection) 建立在深奥的代数拓扑和黎曼几何理论之上,但它的效果却是立竿见影的:
它比 t-SNE 快得多,且保留了更多的全局结构。
在实际的文本分析项目中(如 BERT/OpenAI Embedding),UMAP 已经逐渐成为首选的降维引擎,正是看中了它在速度和结构保持上的平衡能力。
(图注:UMAP 像搭
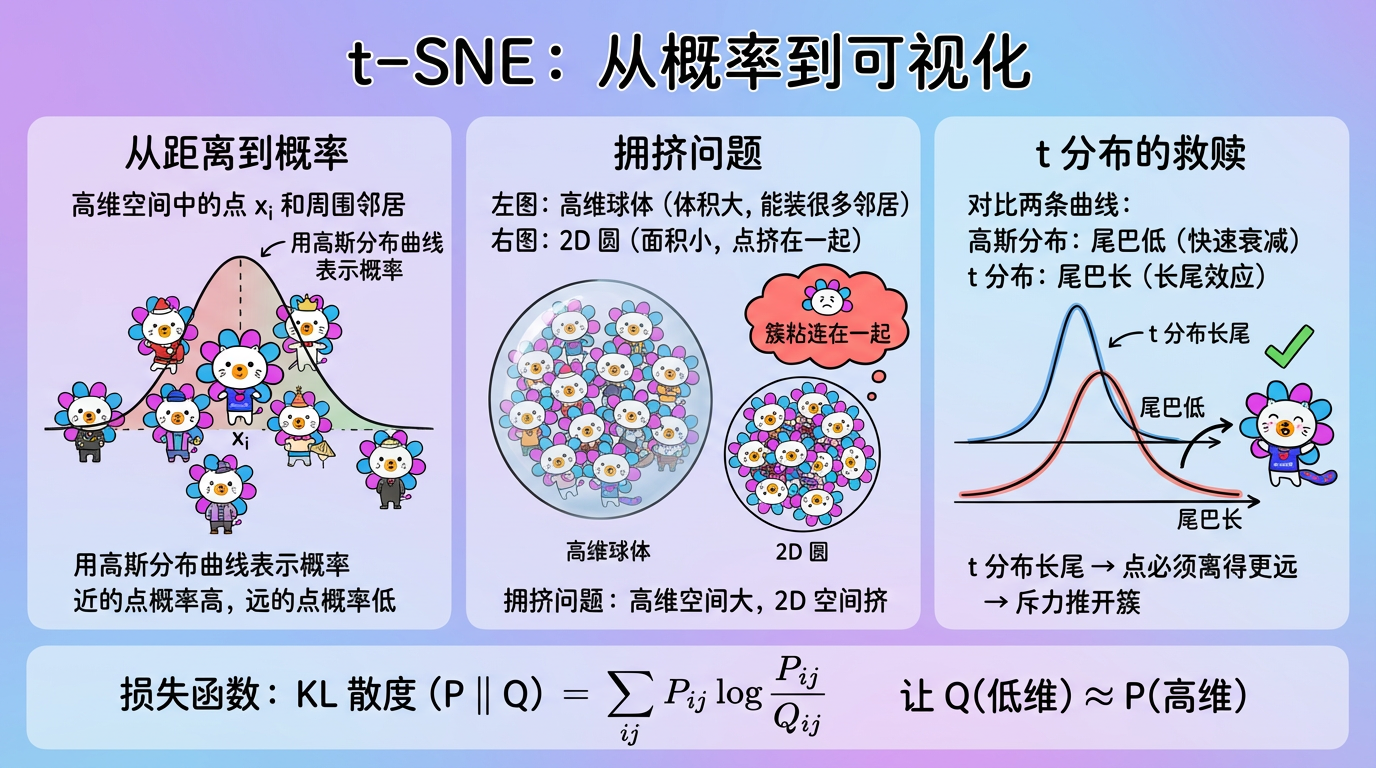
第 12 章:t-SNE深度解析
“在数据可视化的世界里,t-SNE 就是那个把乱麻理顺的魔术师。”
如果你在 Kaggle 上看过别人的 Kernel,你一定见过那种把 MNIST 手写数字完美分成 10 堆彩色小岛的图。
这种令人惊叹的“分堆”效果,90% 都是 t-SNE (t-分布随机邻域嵌入) 的功劳。
它不是在做数学投影(像 PCA 那些线性代数游戏),而是在做概率匹配。它强迫低维空间中的点,必须模仿高维空间中的社交关系。
本章我们将深入这个稍微有点复杂的算法内部,掰开揉碎了讲讲它是如何利用“学生 t 分布”来解决拥挤问题的。
(图注:上图是高维空间,下图是低维空间。t-SNE 通过梯度下降,不断移动下图中

第 11 章:非线性降维基础
“地球是圆的,但地图是平的。把球面画成平面的过程,就是流形学习。”
PCA 假设数据分布在一个平坦的超平面上。但现实世界的数据往往是卷曲的、扭曲的。
经典的例子是 “瑞士卷” (Swiss Roll) 数据集。数据像一块卷起来的地毯。
如果你直接用 PCA 从侧面压扁它(线性投影),原本相隔很远的两层会叠在一起,红色的点和蓝色的点就混淆了。这就叫投影混叠。
我们需要把这个卷小心翼翼地展开,就像把地毯铺平一样。这叫 流形学习 (Manifold Learning)。
1. 核心概念:流形假设 (Manifold Hypothesis)
流形学习基于一个大胆的假设:
虽然数据看起来维数



