


“如果你想把一个苹果从一堆西瓜里分出来,你不需要描述苹果长什么样,你只需要切几刀。”
前两章我们讨论了基于统计(Z-Score)和距离(KNN, LOF)的异常检测。
但在大数据时代,它们都有一个致命伤:慢。
计算距离矩阵是 $O(N^2)$ 的复杂度。如果你有 100 万条数据,计算量就是 $10^{12}$ 次。即使是现在的超算也得跑很久。
本章我们将介绍基于模型的方法,特别是工业界的神器——隔离森林 (Isolation Forest)。它不计算距离,而是通过“随机切割”来快速锁定异常。它的复杂度是 $O(N)$,线性的!
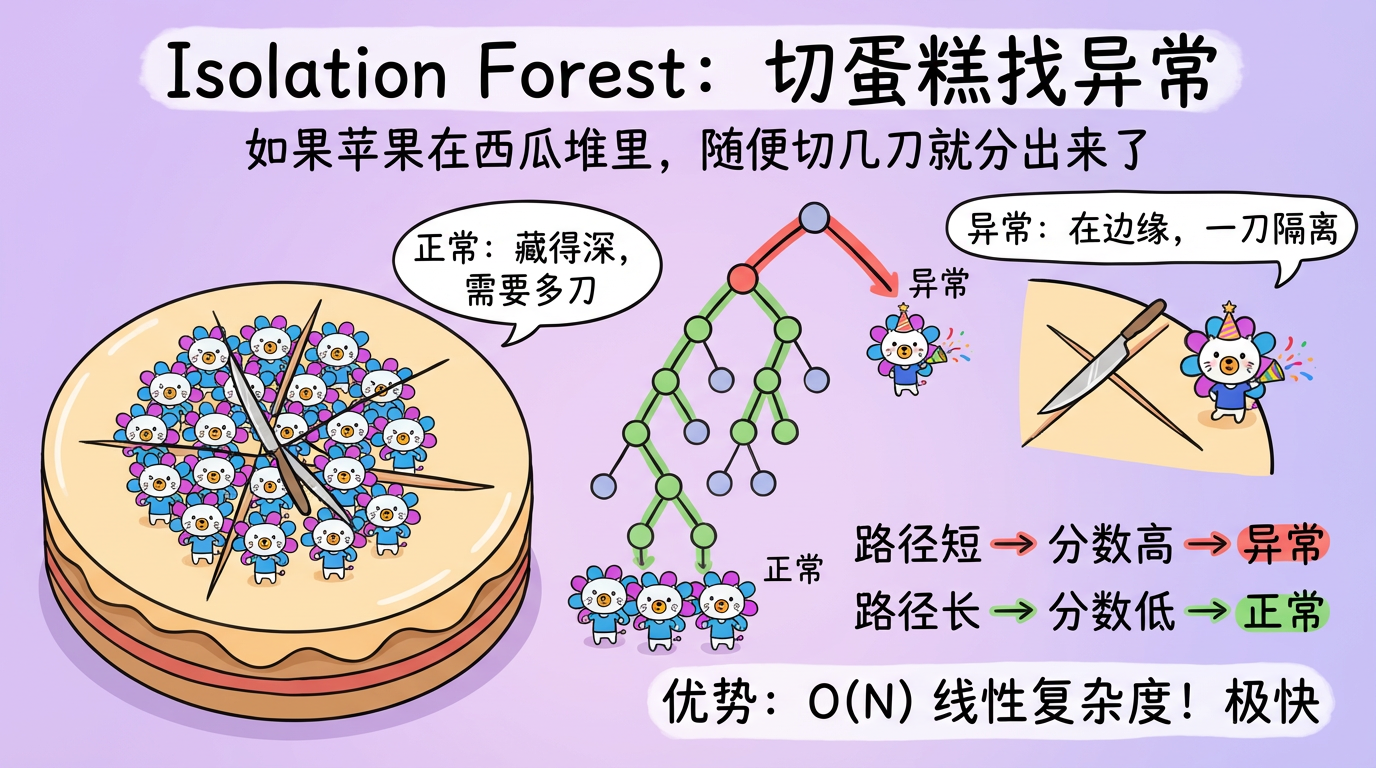
(图注:左图:正常点深埋在中心,需要切很多刀才能分离。右图:异常点在边缘,切一两刀就分离了。)
1. 核心概念:Isolation Forest (孤立森林)
1.1 异常的两个特性
Isolation Forest 基于两个极其简单的假设,这两个假设是异常点自带的“原罪”:
- 稀少 (Few):异常点很少。
- 独特 (Different):异常点的值域与正常点差异很大。
基于这两个特性,如果我们随机切割数据空间,异常点会很容易被切出去。
1.2 随机树的构建 (iTree)
想象你在玩切蛋糕游戏:
- 随机选择一个特征(比如“金额”)。
- 在该特征的最大值和最小值之间,随机选一个切分点。
- 一刀切下去,数据被分为两半。
- 重复上述过程,直到每个点都被单独切出来(成为叶子节点)。
关键洞察:
- 正常点:它们挤在蛋糕中心最密集的地方。你需要切很多很多刀(树很深),才能把它们一个个分开。
- 异常点:它们离群索居在蛋糕边缘。你随便切两刀(树很浅),它就被孤立 (Isolated) 了。
结论:路径长度 (Path Length) 越短,越可能是异常点。
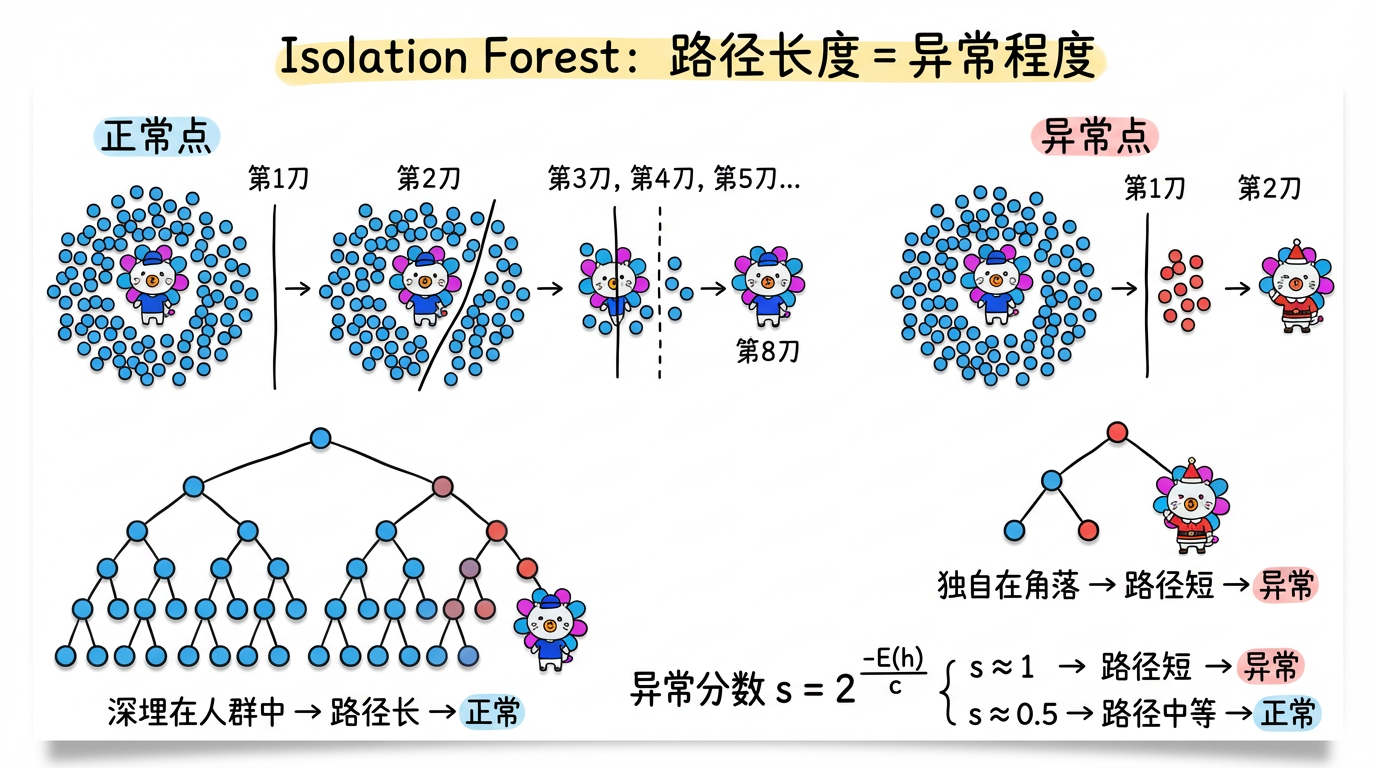
(图注:正常点深埋中心需要 8 刀,异常点在边缘只需 2 刀。路径长度 = 异常程度的倒数。)
1.3 异常分数 (Anomaly Score)
一棵树可能误判,所以我们要种一片森林(比如 100 棵树)。
对于每个样本 $x$,计算它在 100 棵树中的平均路径长度 $E(h(x))$。然后归一化为分数 $s$:
$$ s(x, n) = 2^{-\frac{E(h(x))}{c(n)}} $$
- $s \approx 1$:路径极短 $\rightarrow$ 几乎肯定是异常。
- $s \approx 0.5$:路径不长不短 $\rightarrow$ 正常(和大家都一样)。
- $s \approx 0$:路径极长 $\rightarrow$ 最安全的核心数据。
2. 另一种思路:One-Class SVM (单类支持向量机)
如果你只有正常数据(比如只有良品图片),想检测次品,这是一个单分类 (One-Class Classification) 问题。
One-Class SVM 的思路是:
- 把所有正常数据映射到高维特征空间(使用核函数 Kernel Trick)。
- 在这个高维空间里,找一个最小的超球体 (Hypersphere),把正常数据紧紧包住。
- 这个超球体就是边界。
- 测试时:如果新数据落在球里面,就是正常;落在球外面,就是异常。
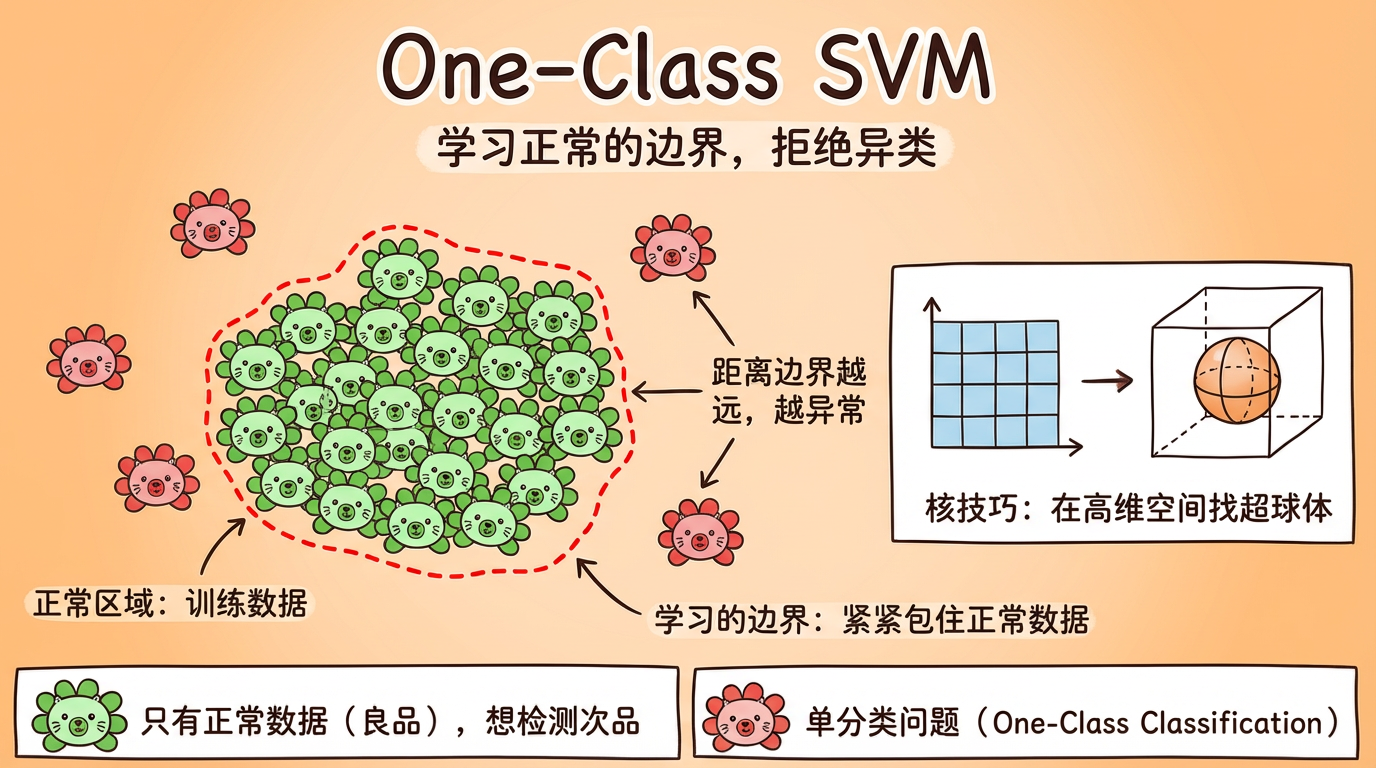
(图注:One-Class SVM 试图画一个圈,把所有白点(正常)圈进去。红点(异常)自然就被排除在外了。)
3. 技术对比:模型驱动全家桶
| 算法 | 核心思想 | 复杂度 | 优点 | 缺点 |
|---|---|---|---|---|
| Isolation Forest | 随机切割,看路径长短 | $O(N)$ (线性!) | 极快,适合海量高维数据,鲁棒性强 | 对局部异常点(Local Anomaly)不敏感 |
| One-Class SVM | 寻找最大间隔边界 | $O(N^2)$ ~ $O(N^3)$ | 理论严谨,适合小样本、非线性边界 | 慢,对参数 $\nu$ 极其敏感 |
| Elliptic Envelope | 拟合鲁棒高斯分布 | $O(N^3)$ | 对正态分布数据极准 | 不适合非正态分布 |
| Autoencoder | 重构误差 | 依赖网络 | 适合图像/序列等非结构化数据 | 黑盒,训练难,容易过拟合 |
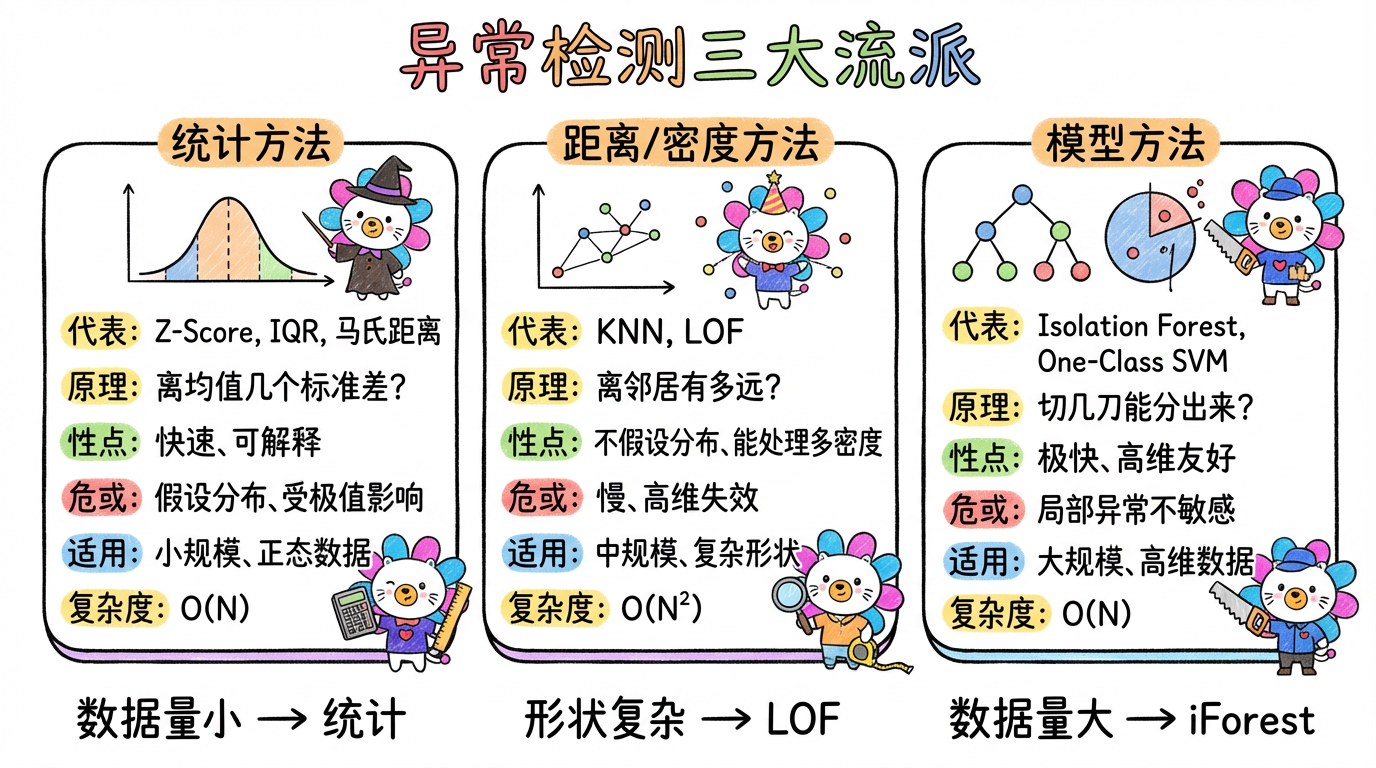
(图注:统计方法适合小数据,距离/密度适合复杂形状,模型方法适合大规模高维数据。)
4. 代码实战:Isolation Forest
在工业界,Isolation Forest 是处理大数据的绝对首选。它不仅快,而且不需要太多调参。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
# 1. 生成数据:一堆正常点,几个离群点
rng = np.random.RandomState(42)
X = 0.3 * rng.randn(100, 2)
X_train = np.r_[X + 2, X - 2] # 两个正常的簇
X_outliers = rng.uniform(low=-4, high=4, size=(20, 2)) # 均匀分布的噪声
X = np.r_[X_train, X_outliers]
# 2. 训练 iForest
# contamination: 预计异常比例。这决定了阈值。
# 如果设为 'auto',它会自动定一个阈值(通常在 0.5 左右)。
clf = IsolationForest(n_estimators=100, contamination=0.1, random_state=42)
clf.fit(X)
# 3. 预测
y_pred = clf.predict(X)
# 1: 正常
# -1: 异常
# 获取异常分数 (负数表示越异常)
scores = clf.decision_function(X)
# 4. 绘图
plt.figure(figsize=(10, 6))
# 画正常点
plt.scatter(X[y_pred == 1, 0], X[y_pred == 1, 1], c='white', edgecolors='k', label='Normal')
# 画异常点
plt.scatter(X[y_pred == -1, 0], X[y_pred == -1, 1], c='red', label='Outlier')
plt.title("Isolation Forest Detection")
plt.legend()
plt.show()5. 实践要点
- 子采样 (Sub-sampling):这是 iForest 的精髓,也是它快的原因。
- 不要用全量数据建树! 如果你有 100 万数据,每棵树只需要随机采样 256 或 512 个样本就足够了。
- 为什么? 因为异常检测不需要看清全局,只需要看清边缘。采样太密,反而会导致 Masking Effect(正常点太密,把异常点包围了,导致切不开)。
- sklearn 默认
max_samples='auto'会自动限制为 256。
- 高维优势:iForest 在高维数据上表现出奇地好。因为它每次只随机选一个特征切割,这天然地避开了距离计算的维度灾难。
- 参数 contamination:这个参数决定了阈值。如果你不知道有多少异常,可以先把
decision_function的得分分布图画出来,找那个长尾的拐点。
下一章预告
我们现在有了各种异常分数:
- 统计学的 Z-Score。
- 基于密度的 LOF Score。
- 基于模型的 Isolation Score。
每个分数的量纲都不一样(有的 0-1,有的 0-100,有的负无穷到正无穷)。
如何把这些分数融合起来,给老板一个最终的、可解释的 Risk Score (0-100)?
这不仅是数学问题,更是业务模型设计的问题。



