



核心观点:多模态(Multimodal)不是简单的”拼凑”,而是真正的”融合”。通过对齐文本空间和图像空间,AI 终于打破了感官的次元壁。
1. 引言:百闻不如一见
人类获取信息 80% 靠视觉。
如果 AI 只能读文字,它就是个瞎子博学士。
GPT-4o 的震撼之处,不仅在于它能说话,在于它能看懂你的视频,听懂你的语气。
要做到这一点,核心难题是:如何把”图像的像素”和”文本的语义”映射到同一个数学空间里?
2. 核心概念:CLIP (对齐大师)
2.1 文本与图像的罗塞塔石碑
OpenAI 发布的 CLIP (Contrastive Language-Image Pre-training) 是多模态领域的里程碑。
它不干别的,就干一件事:判断这张图和这句话是不是一对。
它爬取了互联网上 4 亿对 (图片, 文本) 数据。
通过对比学习 (Contrastive Learning):
- 拉近:匹配的图文,向量距离拉近。
- 推远:不匹配的图文,向量距离推远。
结果是:它学会了图像和文本的通用语言。
💡 比喻:想象一个外交官。
左边是讲”像素语”的图像国,右边是讲”文本语”的文字国。
以前两国鸡同鸭讲。
CLIP 编写了一本双语词典。你给它一张”狗”的照片,它能在词典里瞬间找到单词”Dog”。
3. 技术解析:ViT (Vision Transformer)
3.1 抛弃 CNN
在 Transformer 统治 NLP 之后,Google 团队想:能不能用 Transformer 处理图像?
于是诞生了 ViT (Vision Transformer)。
3.2 图像分块 (Patchify)
Transformer 只能吃序列(Sequence)。图片是 2D 的。
ViT 的做法是:把图片切成小方块(Patch)。
比如一张 224x224 的图,切成 16x16 的小块。这就变成了 196 个小块。
这 196 个小块,就相当于 NLP 里的 196 个单词(Token)。
然后直接扔进 Transformer。
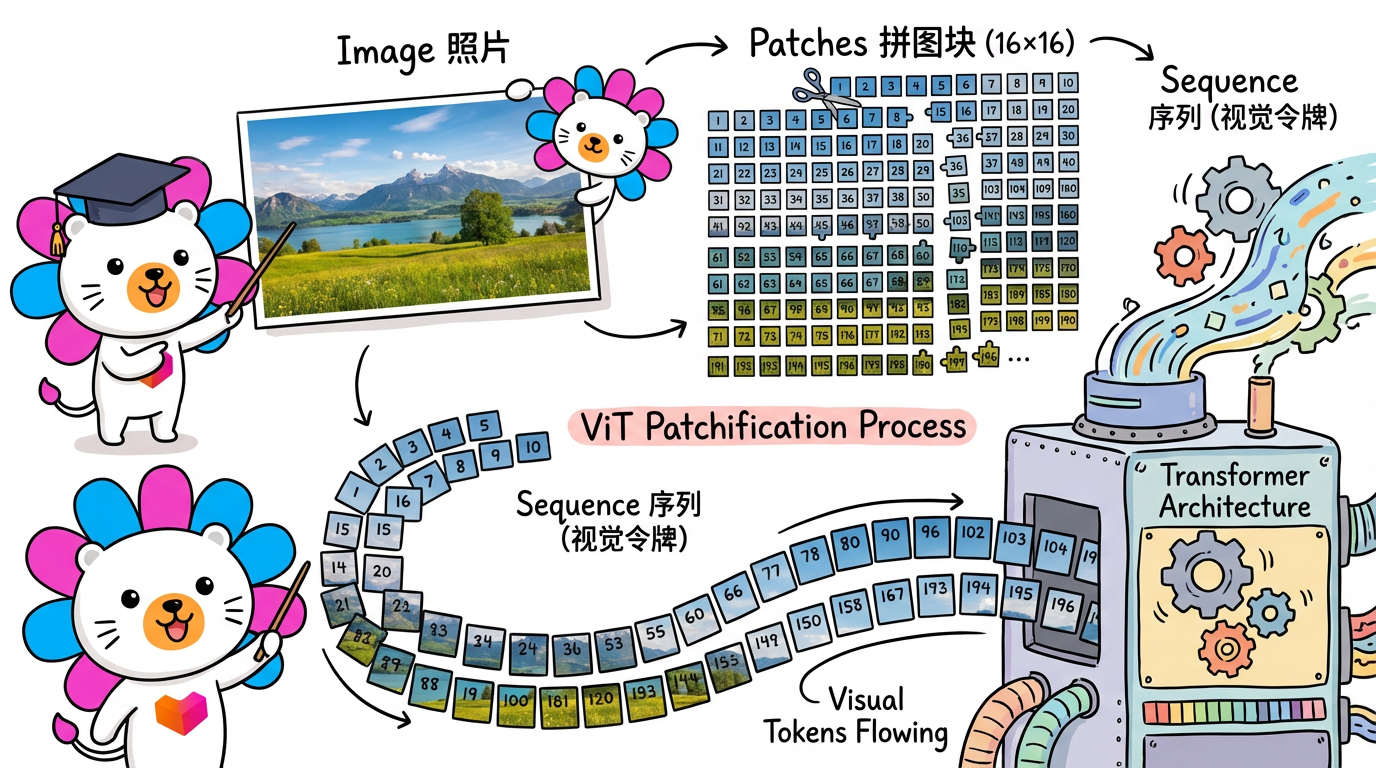
结果证明:只要数据量够大,ViT 完爆传统的 CNN。
4. 工业实战:多模态应用
4.1 LLaVA (Large Language-and-Vision Assistant)
目前的开源多模态模型(LMM),主流架构大多参考 LLaVA。
LLaVA = LLM + CLIP ViT + Projector
- Vision Encoder: 用 CLIP/ViT 把图片变成向量。
- Projector: 一个简单的线性层,把图片向量”翻译”成 LLM 能懂的 Embedding 维度。
- LLM: 接收(图片向量 + 用户文本),像处理纯文本一样生成回答。
4.2 推理成本
多模态推理很贵。
因为一张图片切分后,往往会产生 576 个甚至更多的 Token(相当于几百个单词)。
如果你发一张高清图,对于模型来说,可能相当于读了一篇小短文。
工程师建议:在构建应用时,如果不需要看清细节(如发票识别),可以适当压缩图片分辨率,节省 Token。
5. 总结与展望
- 本章总结:
- CLIP 解决了”图文对齐”的问题。
- ViT 证明了 Transformer 架构的普适性(万物皆 Token)。
- 多模态模型本质上是给 LLM 装上了眼睛(Visual Encoder)。
- 全书结语:
从 Scaling Law 的物理法则,到 RAG 的知识外挂,再到 Agent 的手眼通天。
大模型技术栈还在以天为单位迭代。
但这本指南中的第一性原理——压缩、向量、概率、对齐——将是你穿越周期的罗盘。
保持好奇,Keep Building.


