



核心观点:如果通用大模型是”大学毕业生”,微调(Fine-tuning)就是”岗前培训”。LoRA 技术的出现,让原本需要几百万美元的微调成本,降低到了几百块人民币。
1. 引言:通才 vs 专才
GPT-4 什么都懂,但在写你们公司的”内部公文格式”时,可能总是写不对。
Prompt 工程可以解决一部分问题,但当规则太复杂、或者需要学习大量私有知识(Domain Knowledge)时,Prompt 就塞不下了。
这时你需要 SFT (Supervised Fine-Tuning,有监督微调)。
你要给模型看 1000 份完美的内部公文,让它内化这种风格。
2. 核心概念:LoRA (低秩适配)
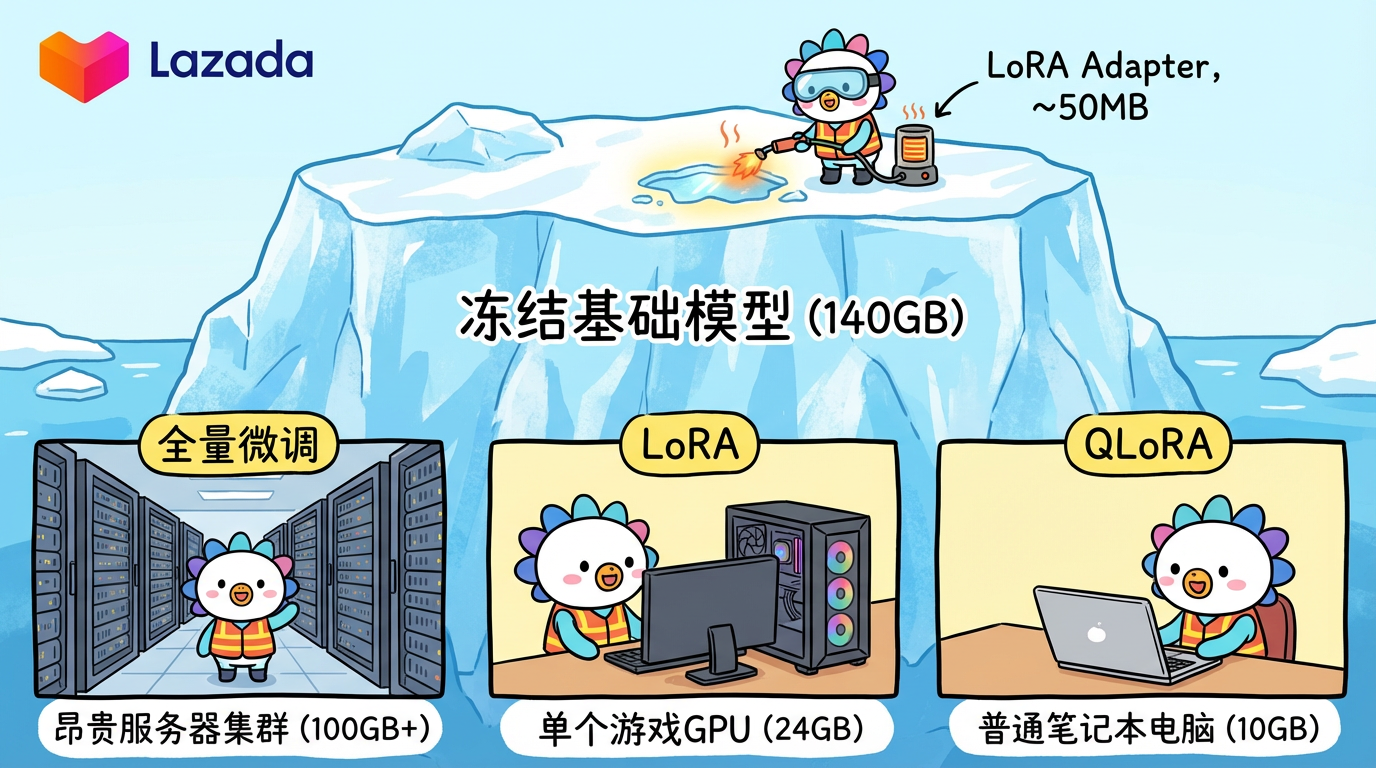
2.1 全量微调太贵了
一个 70B 的模型,权重有 140GB。
如果你要微调它,以前需要更新这 140GB 里的每一个参数。这就需要巨大的显存和算力(Full Fine-tuning)。
2.2 LoRA:四两拨千斤
微软提出的 LoRA (Low-Rank Adaptation) 发现:
改动模型并不需要改动所有参数。我们只需要在原模型旁边,外挂两个非常小的矩阵(A 和 B)。
训练时,冻结原模型,只训练这两个小矩阵。
推理时,把小矩阵的输出加到原模型上。
💡 比喻:想象模型是一个训练有素的特种兵(原始权重)。
- 全量微调:把他回炉重造,从基因层面改造他。成本极高,而且容易把他练废了(Catastrophic Forgetting,灾难性遗忘)。
- LoRA:给他戴一副特殊的”功夫眼镜”(LoRA Adapter)。戴上眼镜,他就会打咏春;换一副”厨师眼镜”,他就会炒菜。
这一副眼镜非常轻(只有几十 MB),易于切换。
3. 技术解析:SFT 数据集构建
微调的成败,80% 取决于数据质量。
3.1 格式 (Instruction Format)
通常是 JSONL 格式:1
{"instruction": "将以下白话文翻译成文言文", "input": "今天天气真好。", "output": "今日天朗气清,惠风和畅。"}
3.2 数据清洗 (Data Cleaning)
- 去重:重复数据会导致模型复读机。
- 多样性:不要只给一种句式。
- CoT 增强:如果想训练推理能力,Output 里最好包含思维链过程。
4. 工业实战:PEFT 技术栈
在 Python 中,我们使用 HuggingFace 的 PEFT (Parameter-Efficient Fine-Tuning) 库。
4.1 常用参数参考
- Rank (r): LoRA 的秩。通常设为 8, 16, 32。越大越能学到复杂特征,但显存占用也越大。
- Alpha: 缩放系数。通常设为 2 * r。
- Target Modules: 要对哪些层加 LoRA?通常是对
q_proj,v_proj(Attention 层) 效果最好。
4.2 显存需求 (以 Llama 3 8B 为例)
- Full Finetune: ~120GB (A100 x 2)
- LoRA (16-bit): ~24GB (3090/4090)
- QLoRA (4-bit): ~10GB (普通显卡也能跑!) -> QLoRA 是平民微调的神器。
5. 总结与预告
- 本章总结:
- SFT 是注入垂直领域知识和风格的最佳手段。
- LoRA/QLoRA 让个人开发者也能在消费级显卡上训练大模型。
- 数据质量 > 数据数量。1000 条高质量数据胜过 10万条垃圾数据。
- 下章预告:
我们讨论的都是文本(Text)。但世界是多模态的。下一章《多模态视界:CLIP 与 ViT》,我们将探索 AI 是如何”看见”并理解这个世界的。



