


“离群并不意味着你是错的,只意味着你是孤独的。”
上一章的统计方法(Z-Score)假设数据服从某种分布(如正态分布)。但在现实世界中,数据的形状可能千奇百怪(如双螺旋、甜甜圈、不规则的多簇)。
这时候,任何假设分布的模型都会失效。我们需要回归几何直觉:
异常点就是那些离大家都远的点。
本章将介绍两类不依赖分布假设的算法:KNN(看距离)和 LOF(看密度)。
1. KNN 异常检测:简单的力量
KNN (K-Nearest Neighbors) 不仅可以做分类,也可以做异常检测。
它的逻辑非常朴素:如果你的 K 个最近邻居都离你很远,那你就是异常点。
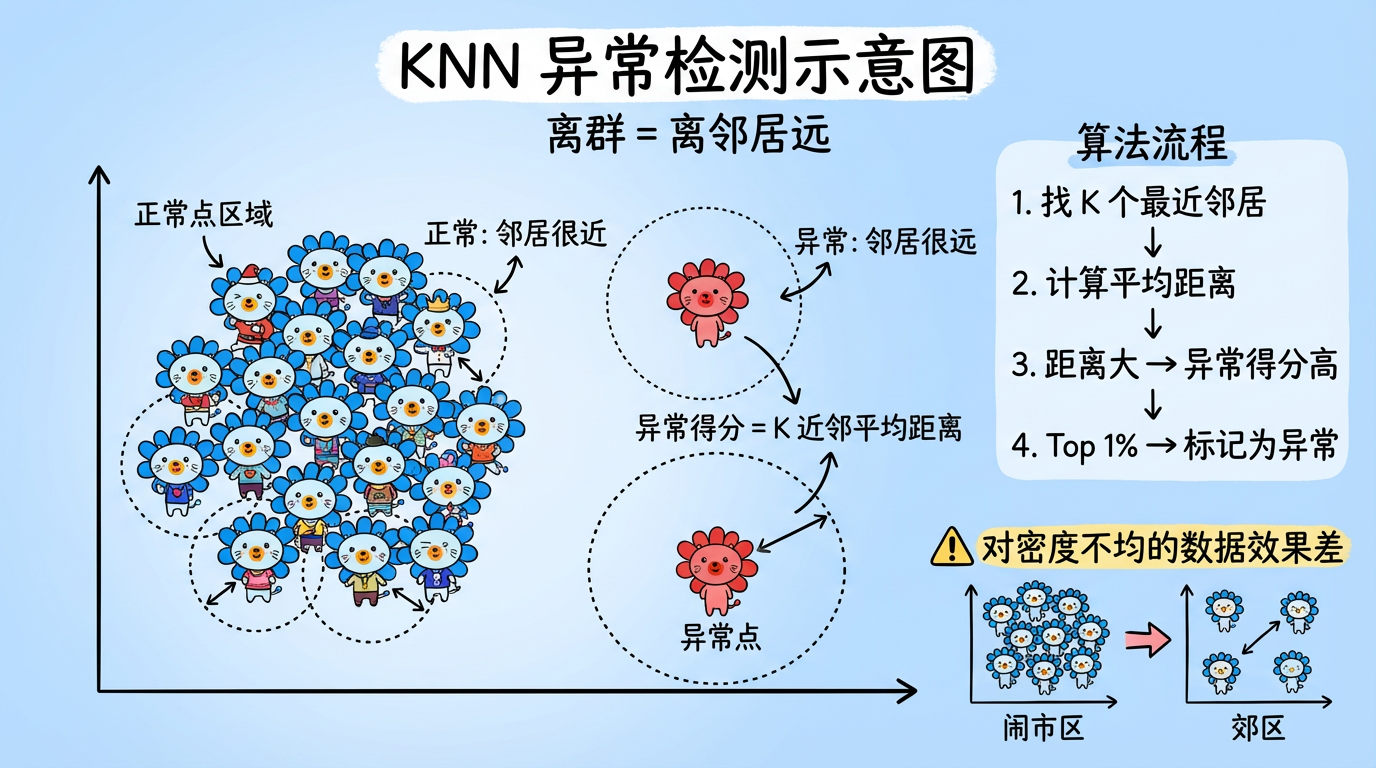
(图注:正常点 A 的邻居都在身边;异常点 B 的邻居都在十万八千里外。B 的平均邻居距离显著大于 A。)
1.1 算法流程
- 找邻居:对于数据点 $x$,找到它最近的 $k$ 个邻居。
- 算得分:计算这 $k$ 个邻居的平均距离(或者第 $k$ 个邻居的距离)。
- 排座次:这个距离就是 异常得分 (Anomaly Score)。得分越高,越异常。
- 切一刀:设定一个阈值(比如 Top 1%),得分最高的点即为异常。
1.2 优缺点分析
- 优点:
- 非参数:不需要假设数据服从正态分布。
- 可解释:你可以告诉用户“因为它离所有正常工单都很远”。
- 缺点:
- 计算量大:需要计算所有点对的距离,复杂度 $O(N^2)$。
- 密度敏感:这是它最大的死穴。无法处理多密度的数据集。
2. LOF (局部离群因子):密度的相对论
2.1 为什么 KNN 不行?(多密度问题)
想象一个城市:
- 闹市区 (C1):人口极度密集。大家都挤在一起,人与人之间距离 1 米。
- 郊区 (C2):人口稀疏。人与人之间距离 100 米。
KNN 的困境:
- 如果在闹市区,有一个人离邻居 10 米远。在 KNN 看来,10 米很近啊,正常。但在闹市区,这其实是异常(为什么大家都在排队,你一个人站在 10 米开外?)。
- 如果在郊区,大家距离都是 100 米。KNN 看来,100 米很远啊,异常。但其实在郊区这很正常。
结论:用同一把尺子(全局阈值)去衡量不同密度的区域,注定会失败。
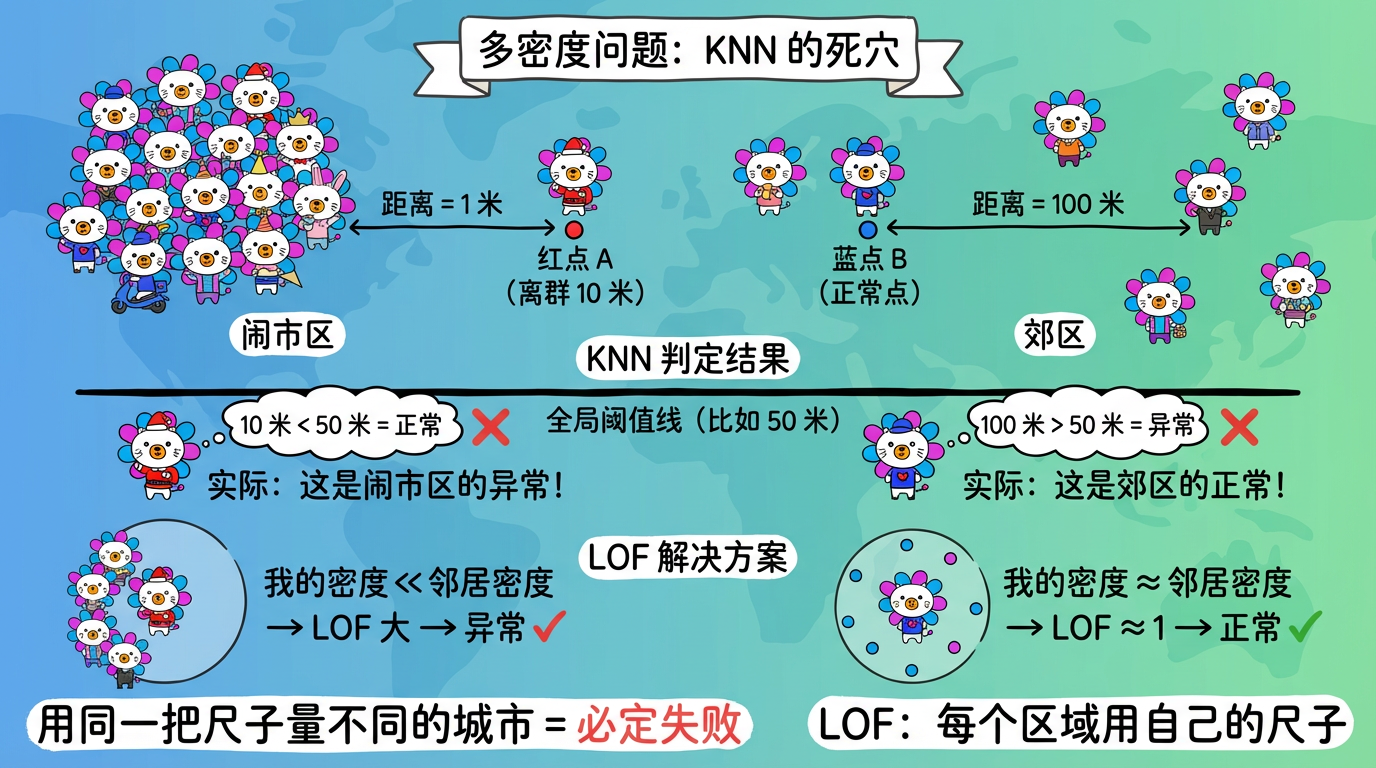
(图注:闹市区的离群点被漏判,郊区的正常点被误判。KNN 的全局阈值无法处理密度差异。)
2.2 LOF 的核心思想:相对密度
LOF (Local Outlier Factor) 引入了相对密度的概念。它不看绝对距离,而是看:
“你的密度”与“你邻居的密度”的比值。
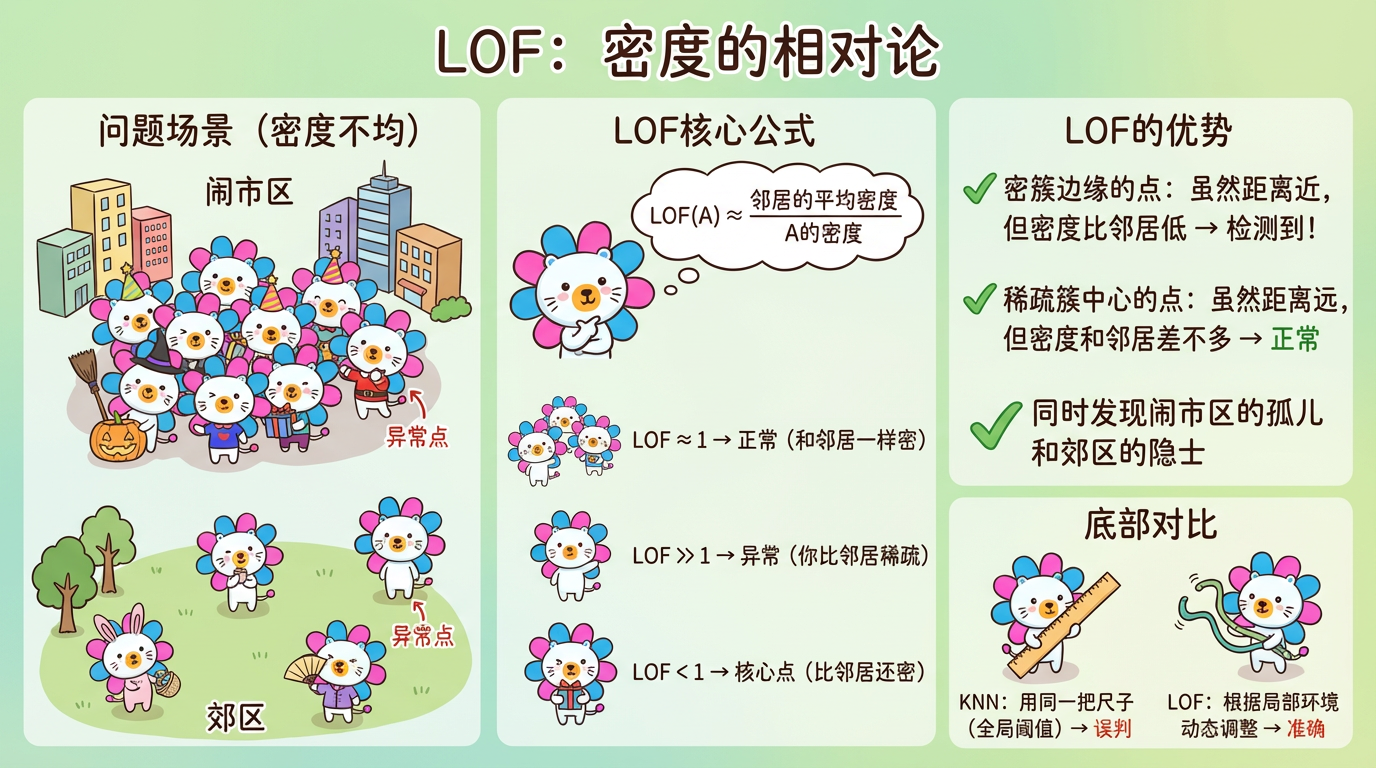
(图注:点 A 的密度很低,但它的邻居(在圆圈里)密度很高。这种反差使得 A 的 LOF 值很高。)
2.3 核心公式推导 (简化版)
- 局部可达密度 (LRD):大概就是“我周围邻居有多挤”的倒数。
- LOF 指数:
$$ LOF(A) \approx \frac{\text{邻居们的平均 LRD}}{\text{A 的 LRD}} $$
判读指南:
- $LOF \approx 1$:正常。你的密度和邻居差不多。大家都是郊区人,或者大家都是城里人。
- $LOF \gg 1$:异常。你的密度远小于邻居的密度。你的邻居很挤,而你很空。你是“闹市区的孤儿”。
- $LOF < 1$:核心点。你的密度比邻居还大。你是“比正常还正常”的致密核心。
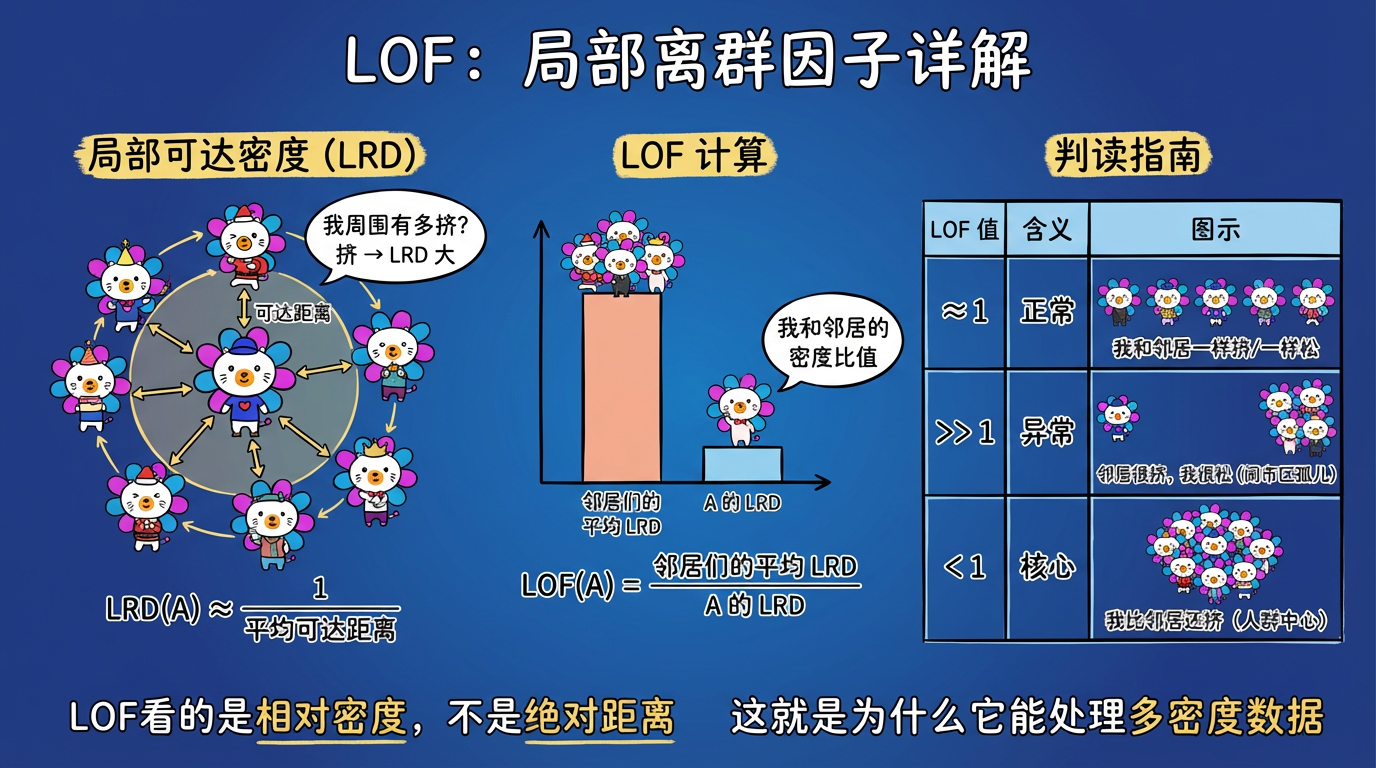
(图注:LOF 通过比较自身密度与邻居密度的比值来判断异常程度。)
3. 技术对比:距离 vs 密度
| 算法 | 核心指标 | 适用场景 | 局限性 |
|---|---|---|---|
| KNN | 绝对距离 | 密度均匀的数据集,简单场景 | 无法处理多密度簇 (闹市区 vs 郊区) |
| LOF | 相对密度比 | 密度不均的复杂数据集,检测局部异常 | 计算慢,对近邻数 k 敏感 |
| COF | 链式距离 | 线性和曲线状的数据 (如血管分布) | 更慢 |
| LOCI | 多尺度积分 | 极其复杂的数据,自动选半径 | 极慢 (实际上很少用) |
4. 代码实战:检测不均匀簇中的异常
我们将生成一个“闹市区”和一个“郊区”,并在其中安插几个异常点,看看 KNN 和 LOF 的表现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import LocalOutlierFactor, NearestNeighbors
# 1. 生成数据:两个密度不同的簇
np.random.seed(42)
# C1: 闹市区 (密)
X_dense = np.random.normal(0, 0.2, (200, 2))
# C2: 郊区 (稀)
X_sparse = np.random.normal(3, 1.0, (200, 2))
X = np.r_[X_dense, X_sparse]
# 2. 插入异常点
# Outlier 1: 在闹市区旁边 (距离 0.8)。对于闹市区来说,这很远。
# Outlier 2: 在郊区旁边 (距离 0.8)。对于郊区来说,这很近。
X_outliers = np.array([[0.8, 0.8], [3.8, 3.8]])
X = np.r_[X, X_outliers]
# ==========================================
# 方法 A: KNN (绝对距离)
# ==========================================
knn = NearestNeighbors(n_neighbors=20)
knn.fit(X)
distances, _ = knn.kneighbors(X)
# 取第 20 个邻居的距离作为得分
knn_scores = distances[:, -1]
# ==========================================
# 方法 B: LOF (相对密度)
# ==========================================
lof = LocalOutlierFactor(n_neighbors=20, contamination='auto')
# sklearn 返回的是负的 LOF,越接近 -1 越正常,越小越异常
lof.fit(X)
lof_scores = -lof.negative_outlier_factor_
# 3. 绘图对比
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# KNN 结果
scatter1 = ax1.scatter(X[:, 0], X[:, 1], c=knn_scores, cmap='Reds', s=50, edgecolor='k')
ax1.set_title("KNN Scores (Absolute Distance)")
plt.colorbar(scatter1, ax=ax1, label='Distance to 20th Neighbor')
# 你会发现:郊区的正常点得分都很高(被误判为异常),而闹市区的异常点得分很低(被漏判)。
# LOF 结果
scatter2 = ax2.scatter(X[:, 0], X[:, 1], c=lof_scores, cmap='Reds', s=50, edgecolor='k')
ax2.set_title("LOF Scores (Relative Density)")
plt.colorbar(scatter2, ax=ax2, label='LOF Score')
# 你会发现:LOF 准确地把两个异常点都标红了,且忽略了郊区和闹市区的密度差异。
plt.show()5. 实践要点
- 参数 k 的选择:
n_neighbors至关重要。- 太小:容易受随机噪声干扰,把几个偶然凑在一起的噪声当成正常簇。
- 太大:会跨越多个簇,导致局部密度估计不准。
- 经验:通常建议设为 20。或者设为
MinPts(你认为一个簇最少有多少人)。
- 高维失效:无论是 KNN 还是 LOF,都依赖欧氏距离计算。在 1536 维空间,距离失效,这些算法效果会大打折扣。
- 对策:务必先降维(PCA 到 20-50 维),然后再跑 LOF。
- 计算瓶颈:LOF 需要计算所有点的 k-近邻,复杂度 $O(N^2)$。
- 对于 10 万数据,可能要跑几分钟。
- 对于 100 万数据,可能要跑几天。
- 对策:如果数据量太大,请看下一章的 iForest。
下一章预告
如果数据量达到百万级,算不动距离怎么办?
有没有一种算法,不需要计算昂贵的 $O(N^2)$ 距离矩阵,像切西瓜一样随便切几刀,就能把异常点找出来?
这就是大数据时代的神器——隔离森林 (Isolation Forest)。



