


“虽然每片雪花都是独一无二的,但有些雪花实在是太独特了。”
在文本分析项目中,我们的目标不仅是聚类(发现常态),更是风险挖掘。
什么是风险?风险通常意味着“异常”。
- 大部分工单都在说“快递慢”(常态)。
- 突然有一条工单说“快递员在门口放火”(异常)。
如何用数学定义“异常”?最古老也最经久不衰的方法是统计学。
统计学告诉我们:“正常”就是大多数,“异常”就是极少数。
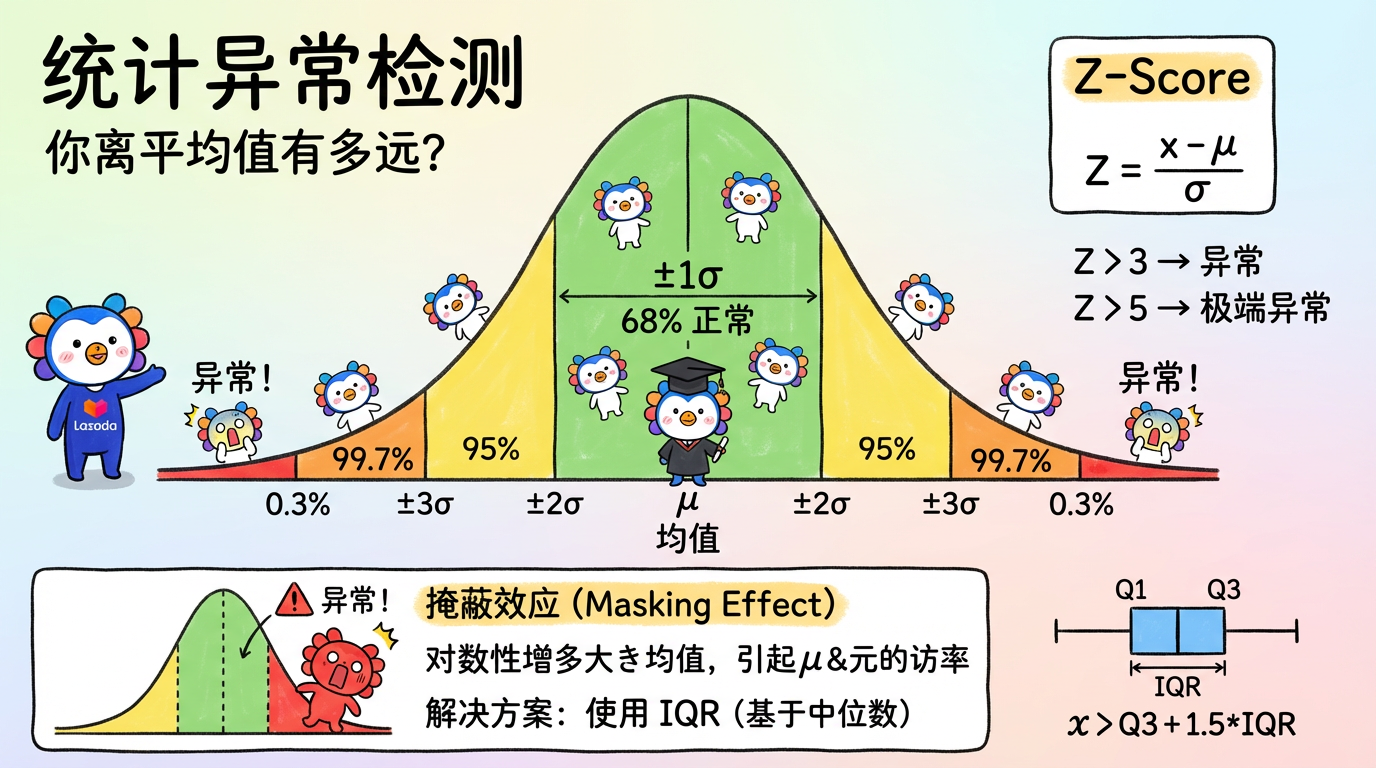
(图注:在正态分布中,落在 3σ 之外的区域就是异常区。)
1. 核心概念:你离平均值有多远?
1.1 正态分布假设 (The Normal Assumption)
统计方法的核心假设是:正常数据服从某种分布(通常是正态分布),而异常数据是小概率事件。
想象一下人类的身高:
- 平均身高 $\mu = 170cm$。
- 标准差 $\sigma = 5cm$。
- 68% 的人在 $170 \pm 5$ 之间。
- 99.7% 的人在 $170 \pm 15$ (155-185) 之间。
- 如果你身高 2.3米,你落在了 $3\sigma$ 之外。恭喜你,你是那是 $0.3\%$ 的异类。
1.2 Z-Score (标准分数) —— 最通用的尺子
不同数据的单位不一样(身高是 cm,存款是元),怎么比?
我们要把它们都换算成“距离平均值有几个标准差”。这就是 Z-Score。
$$ Z = \frac{x - \mu}{\sigma} $$
- Z = 0:你就是平均人。
- Z = 1:你比平均水平高一点点。
- Z > 3:疑似异常。你有点离谱了。
- Z > 5:几乎肯定是异常。你太离谱了。
1.3 致命缺陷:掩蔽效应 (Masking Effect)
Z-Score 有个死穴:均值 $\mu$ 和方差 $\sigma$ 本身非常容易受异常值影响。
- 场景:班里有 9 个穷光蛋(资产 0)和 1 个马斯克(资产 1000 亿)。
- 结果:
- 均值 $\mu$ 被拉到了 100 亿。
- 方差 $\sigma$ 被撑得巨大。
- 算一下穷光蛋的 Z-Score:$(0 - 100) / \text{巨大} \approx 0$。
- 算一下马斯克的 Z-Score:$(1000 - 100) / \text{巨大} \approx \text{很小}$。
- 结论:因为马斯克的存在,大家都变得“正常”了。异常值把自己掩护起来了。
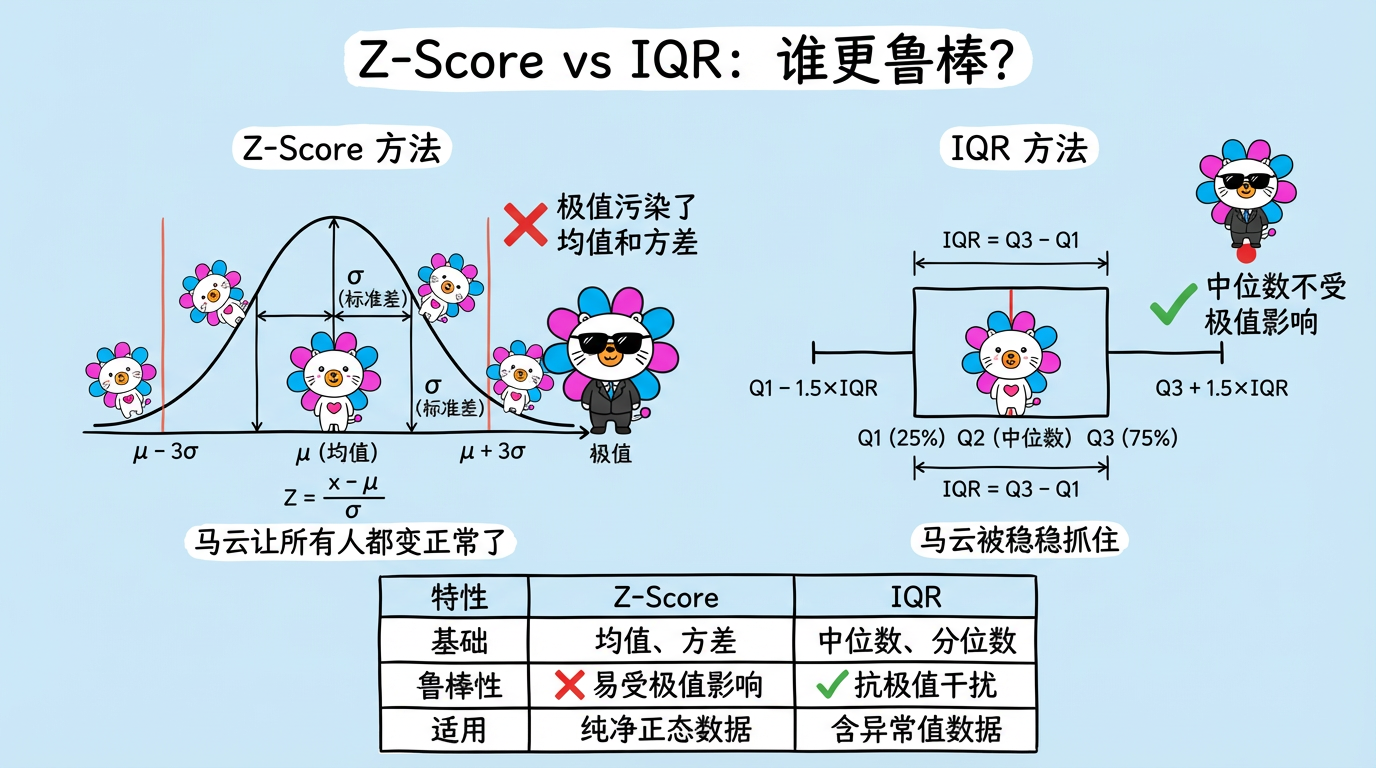
(图注:Z-Score 受极值污染,IQR 基于中位数更鲁棒。)
2. 进阶技术:鲁棒统计 (Robust Statistics)
为了解决掩蔽效应,我们需要更硬核的统计量。我们需要不受马斯克影响的指标。
2.1 IQR (四分位距) —— 中位数的智慧
不再看均值(Mean),而是看中位数 (Median) 和分位数 (Quantile)。
- Q1:第 25% 的人。
- Q3:第 75% 的人。
- IQR:$Q3 - Q1$。代表了中间 50% 大众的贫富差距。
- 异常判定:
- 上限:$Q3 + 1.5 \times IQR$
- 下限:$Q1 - 1.5 \times IQR$
为什么它鲁棒?
哪怕班里混进了 10 个马斯克,中位数(第 50 名)依然是那个普通人。Q1 和 Q3 也几乎不变。
所以 IQR 能稳准狠地把马斯克抓出来。
2.2 Grubbs 检验
专门用于检验“只有一个异常值”的假设检验方法。
- 它假设数据服从正态分布。
- 它通过计算最大值与均值的偏差,看这个偏差是否大到“不科学”。
- 适用场景:小样本数据,逐个剔除异常。
3. 多变量统计:马氏距离 (Mahalanobis Distance)
如果是多维数据(比如身高和体重),单纯看每一维的 Z-Score 是不够的。
- 案例:
- 身高 190cm:在人群中属于正常偏高(Z=2)。
- 体重 50kg:在人群中属于正常偏瘦(Z=-2)。
- 但是,身高 190cm 且 体重 50kg:极度异常(竹竿)。
这种异常,单独看 X 或 Y 都看不出来,必须看相关性。
马氏距离就是为此而生的。它本质上是消除了相关性干扰的欧氏距离。
$$ D_M(x) = \sqrt{(x - \mu)^T \Sigma^{-1} (x - \mu)} $$
- $\Sigma^{-1}$:协方差矩阵的逆。它的作用是:如果两个特征高度相关(身高体重),就给它们降权;如果两个特征不相关,就保持原权。
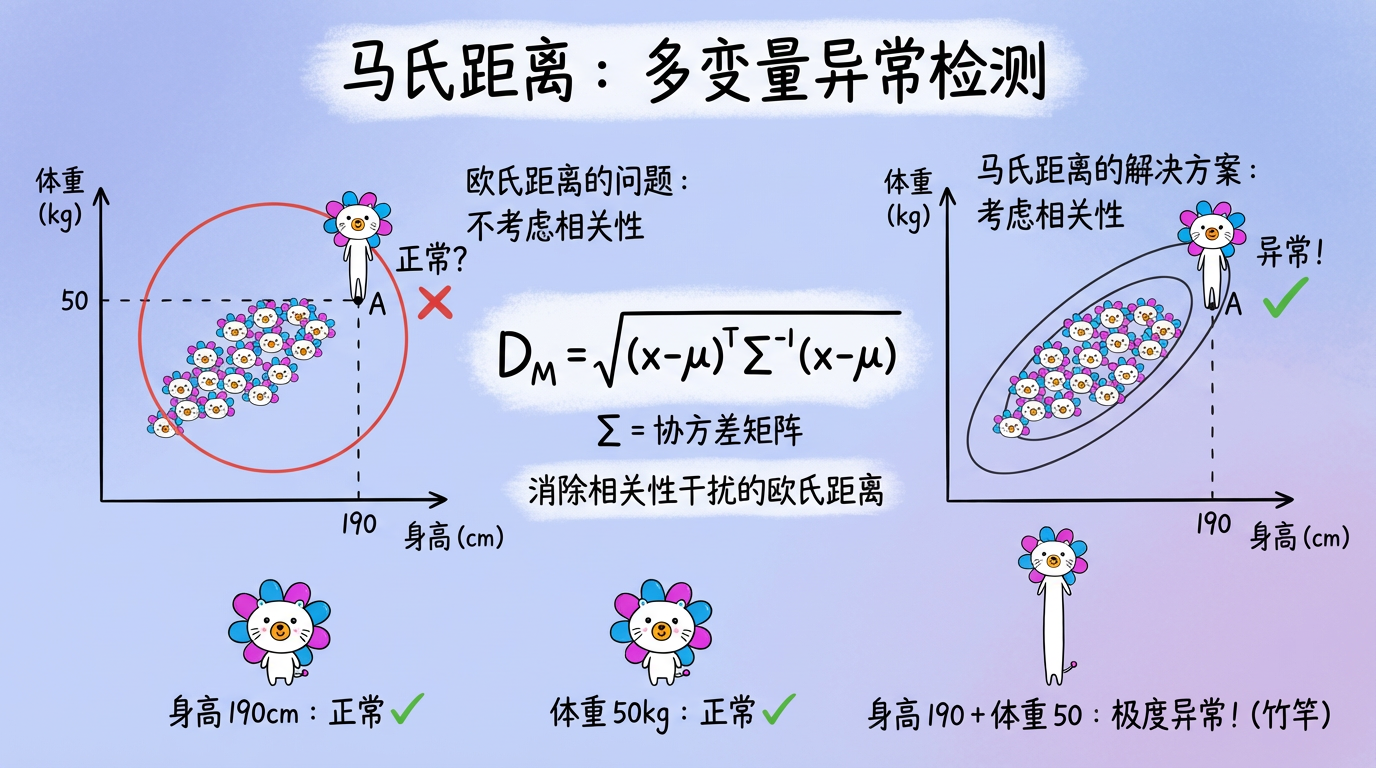
(图注:红色点在 X 和 Y轴投影上都在正常范围内(盒子内),但在联合分布中,它显然偏离了主群体(椭圆)。)
4. 代码实战:Z-Score vs IQR
我们来模拟一个“马斯克混入班级”的场景,看看两种方法的表现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import numpy as np
import matplotlib.pyplot as plt
# 1. 生成数据:100 个正常点 + 5 个极端异常点
np.random.seed(42)
normal_data = np.random.normal(0, 1, 100) # 均值0,方差1
outliers = np.array([10, 12, 15, -10, 20]) # 极端的异常值
data = np.concatenate([normal_data, outliers])
# ==========================================
# 方法 A: Z-Score (传统方法)
# ==========================================
mean = np.mean(data)
std = np.std(data)
z_scores = np.abs((data - mean) / std)
# 阈值通常设为 3
z_outliers = data[z_scores > 3]
print(f"真实均值: 0, 受污染均值: {mean:.2f}")
print(f"真实方差: 1, 受污染方差: {std:.2f}")
print(f"Z-Score 抓到了 {len(z_outliers)} 个异常点 (漏网之鱼!)")
# ==========================================
# 方法 B: IQR (鲁棒方法)
# ==========================================
q1 = np.percentile(data, 25)
q3 = np.percentile(data, 75)
iqr = q3 - q1
# 判定范围
lower_bound = q1 - 1.5 * iqr
upper_bound = q3 + 1.5 * iqr
iqr_outliers = data[(data > upper_bound) | (data < lower_bound)]
print(f"IQR 抓到了 {len(iqr_outliers)} 个异常点 (全部抓住!)")
# 绘图对比
plt.figure(figsize=(10, 4))
plt.plot(data, 'o', label='Data')
plt.axhline(mean + 3*std, color='r', linestyle='--', label='Z-Score Threshold')
plt.axhline(upper_bound, color='g', linestyle='--', label='IQR Threshold')
plt.legend()
plt.title("Z-Score vs IQR")
plt.show()5. 实践要点
- 数据正态性:Z-Score 假设数据是正态的。
- 陷阱:电商销量、点赞数通常是长尾分布(Power Law)。如果直接算 Z-Score,会把所有头部爆款(Top 1%)都当成异常杀掉。
- 对策:先对数据取
log1p(对数变换),把它拉成近似正态,再算 Z-Score。
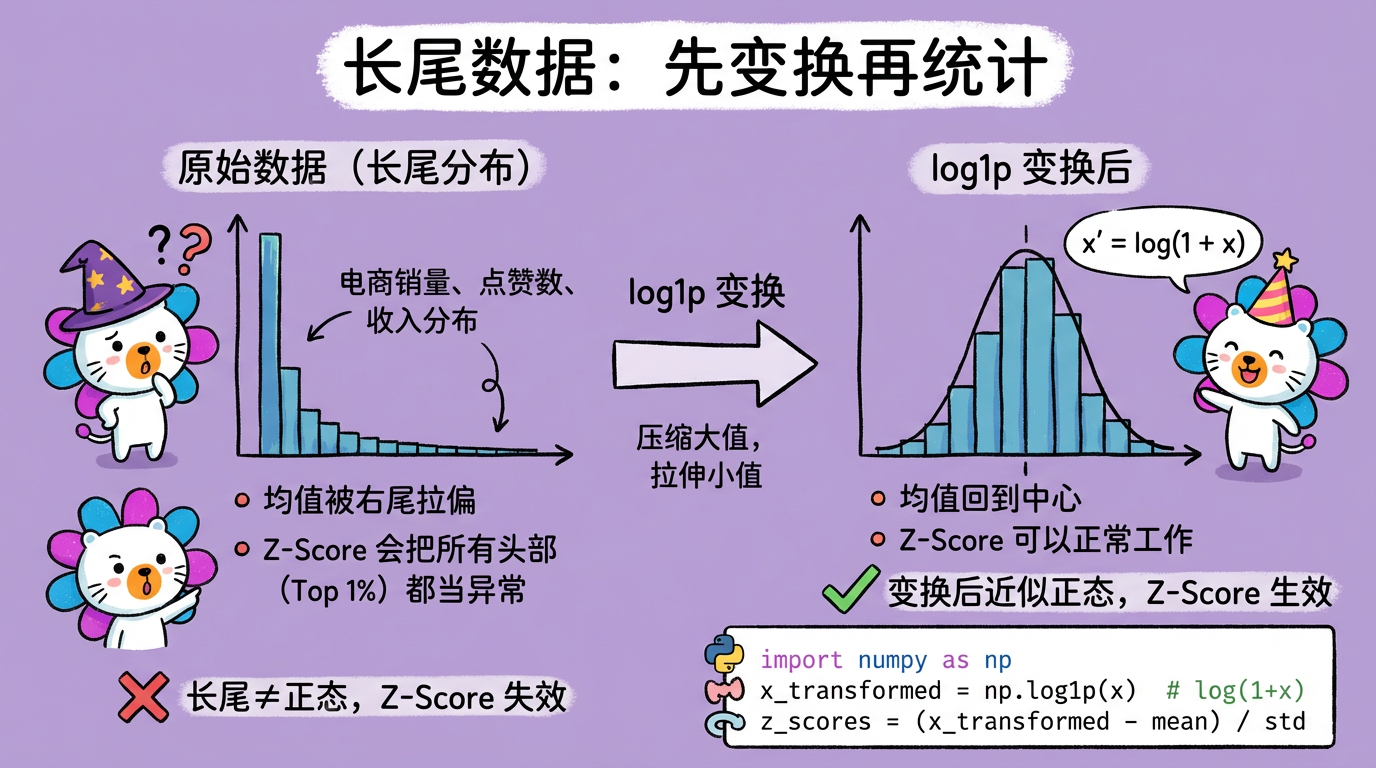
(图注:长尾分布通过 log1p 变换后接近正态,Z-Score 才能正常工作。)
- 高维失效:在 1536 维的文本 Embedding 空间里,马氏距离需要计算 $1536 \times 1536$ 的协方差矩阵逆矩阵。
- 后果:计算极慢,且极其不稳定(矩阵不可逆)。
- 结论:高维异常检测通常不走统计路线,而是走下一章的距离/密度路线。
下一章预告
统计方法假设数据服从某种分布(如正态分布)。
如果数据分布极其复杂(比如是个双螺旋结构,或者是几个形状各异的圈),统计方法就废了。
这时候,我们需要回归最朴素的几何直觉:离群就是离邻居远。



