


“给我一个数字,我就能撬动地球。—— 前提是这个数字已经归一化了。”
在前面的章节中,我们学习了各式各样的异常检测算法,它们会吐出各种数字:
- K-Means:离群距离 (Distance)。单位可能是米、元、或者抽象的欧氏距离。
- LOF:局部离群因子 (Factor)。通常大于 1,没有上限。
- Isolation Forest:异常概率/分数 (Score)。通常在 0 到 1 之间。
但老板和业务方不想看这些天书。他们只想知道:
“这个用户的风险是 85 分(高危),还是 20 分(安全)?”
这就需要我们构建一个 风险评分模型 (Risk Scoring Model)。本章将探讨如何科学地将多个异构指标,像炼金术一样,融合为一个最终的 Risk Score。
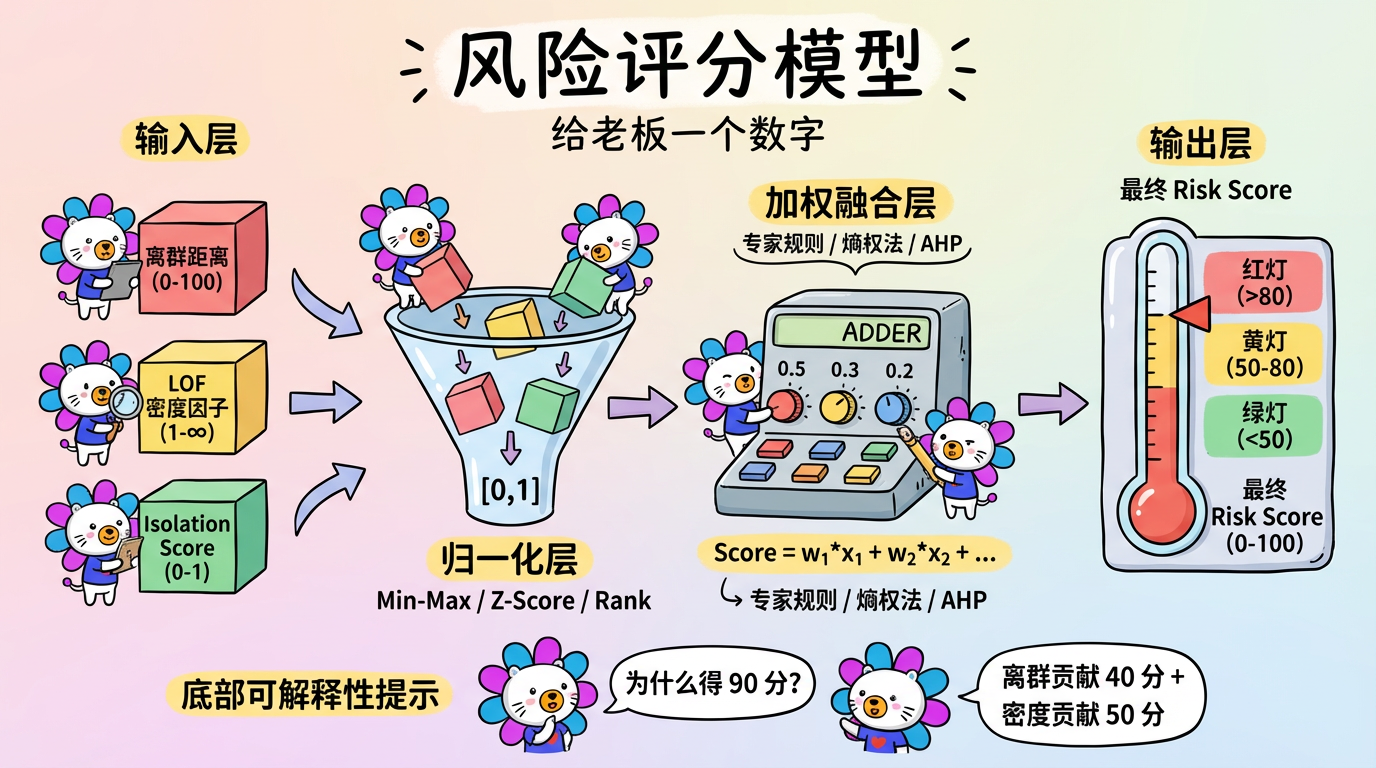
(图注:输入层是原始指标,经过归一化层、加权层,最终汇聚成 Risk Score。)
1. 核心概念:多因子融合的艺术
评分模型本质上是一个函数:$Score = f(x_1, x_2, …, x_n)$。
虽然深度学习 (Deep Learning) 很火,但在风险评分领域,最常用、最稳健的形式依然是线性加权求和:
$$ Score = w_1 \cdot \hat{x}_1 + w_2 \cdot \hat{x}_2 + … + w_n \cdot \hat{x}_n $$
这个公式看似简单,但有两个巨坑必须填平:
- 量纲不同 ($\hat{x}$):距离是 [0, 100],概率是 [0, 1],LOF 是 [1, $\infty$]。如果直接相加,大数会吃掉小数。必须归一化。
- 权重难定 ($w$):到底是距离重要,还是密度重要?需要一套赋权机制。
2. 归一化策略 (Normalization)
我们的目标是把所有指标都拉到同一起跑线,通常是 $[0, 1]$ 或 $[0, 100]$。
2.1 Min-Max Scaling (离差标准化)
这是最简单粗暴的方法。
$$ x_{new} = \frac{x - x_{min}}{x_{max} - x_{min}} $$
- 优点:严格限制在 [0, 1],解释性好(0 是最好,1 是最差)。
- 缺点:极度受异常值影响。
- 场景:99 个人的欠款是 1 万,有 1 个人的欠款是 1 亿。
- 结果:那个 1 亿的人归一化后是 1。其他 99 个人全是 0.0001。
- 反转:在异常检测中,这反而可能是优点! 我们就是想把那个“显眼包”揪出来,同时压低普通人的噪音。
2.2 Z-Score Standardization (标准差标准化)
$$ x_{new} = \frac{x - \mu}{\sigma} $$
- 优点:保留了数据的分布形态,对异常值稍微没那么敏感。
- 缺点:没有固定的上下界(可能是 -3 到 +5),不方便转化为 0-100 分。
2.3 Rank Scaling (排名归一化) —— 推荐
不管数值是多少,只看排名百分比。
$$ x_{new} = \frac{Rank(x)}{N} $$
- 优点:极度鲁棒。不管那个欠款是 1 亿还是 1 万亿,它都是第一名 (1.0)。数据会均匀分布在 [0, 1] 之间。
- 缺点:丢失了“程度”信息。第一名和第二名可能只差 0.01 元,也可能差 100 亿,排名看不出来。
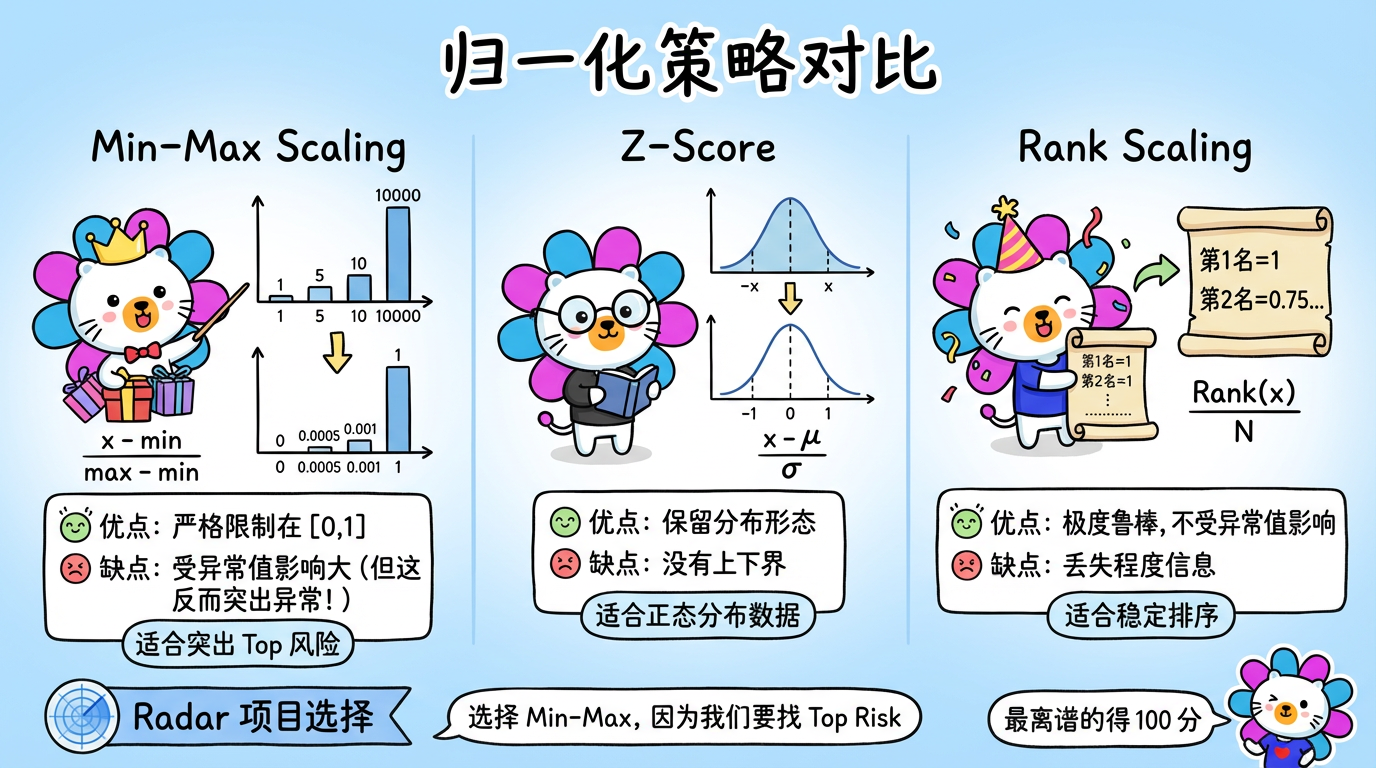
(图注:Min-Max 凸显极端值;Rank 抹平差距。根据业务需求选择。)
3. 权重设计 (Weighting)
如何决定 $w_i$?这是一个哲学问题。
3.1 专家规则 (Heuristic) —— 拍脑袋
直接问业务专家。
- “老张,你觉得‘离群距离’和‘局部密度’哪个更能代表风险?”
- 老张:“离群更重要吧,给 0.6;密度给 0.4。”
- 优点:解释性极强,完全符合业务直觉,老板容易接受。
- 缺点:主观,难以验证。
3.2 熵权法 (Entropy Weight Method) —— 让数据说话
利用信息论中的熵 (Entropy)。
- 逻辑:
- 如果某个指标大家的数值都差不多(方差小,混乱度高,熵大),说明这个指标没啥区分度,权重应该低。
- 如果某个指标大家差异巨大(方差大,熵小),说明这个指标蕴含信息量大,权重应该高。
- 优点:客观,自动化。
3.3 AHP (层次分析法) —— 科学地拍脑袋
让专家做选择题,而不是直接填空。
- 不要问:“A 权重多少?”
- 要问:“你觉得指标 A 比指标 B 重要多少?(1-9 分)”
- 然后构建判断矩阵,通过计算特征向量得出一致性权重。
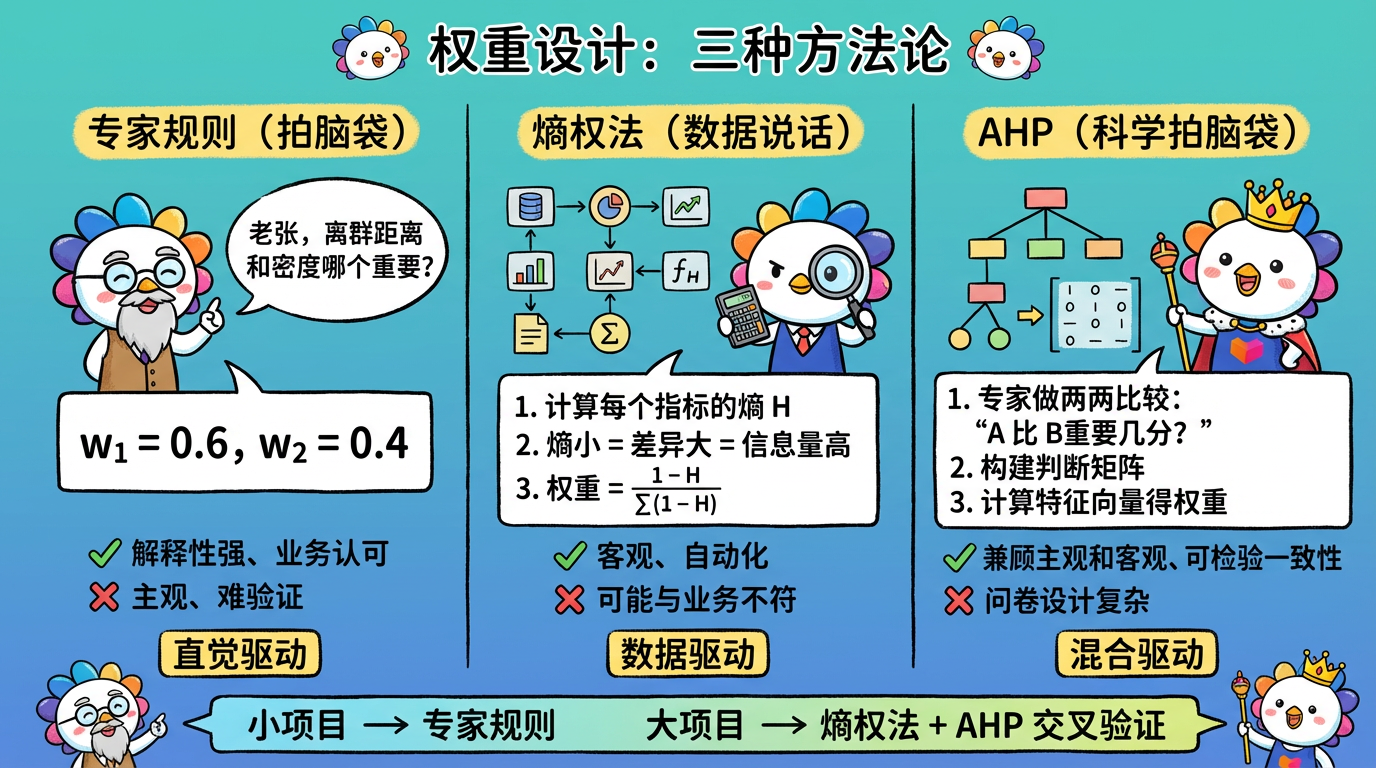
(图注:专家规则靠直觉,熵权法靠数据,AHP 兼顾两者。)
4. 综合评分公式:实战案例
在实际项目中,我们不需要搞太复杂。一个简单而有效的混合策略往往最好用。
策略:
- 归一化:使用 Min-Max。因为我们就是想找 Top Risk,不仅要排名第一,还要看它到底有多离谱。
- 权重:使用 50/50 均分。除非有强烈的业务理由,否则不要轻易认为谁比谁重要。
$$ Risk = 100 \times (0.5 \times \text{Norm}(Distance) + 0.5 \times \text{Norm}(Density)) $$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import numpy as np
# 假设我们有两个原始指标数组
cluster_distances = np.array([0.1, 0.5, 2.0, 10.0]) # 离群距离
density_scores = np.array([1.0, 1.2, 3.0, 5.0]) # LOF 分数 (越大越异常)
# 1. 归一化 (Min-Max)
def min_max_scale(arr):
if arr.max() == arr.min():
return np.zeros_like(arr)
return (arr - arr.min()) / (arr.max() - arr.min())
norm_dist = min_max_scale(cluster_distances)
norm_dens = min_max_scale(density_scores)
print(f"归一化距离: {norm_dist}")
# [0. 0.04 0.19 1. ] -> 注意:那个 10.0 把其他人压得很扁
print(f"归一化密度: {norm_dens}")
# [0. 0.05 0.5 1. ]
# 2. 加权融合 (50/50)
risk_scores = (norm_dist * 0.5 + norm_dens * 0.5) * 100
print(f"最终风险分: {risk_scores}")
# [ 0. 4.5 34.5 100. ]5. 实践要点
- 分数校准 (Calibration):
- 直接算出来的分数,分布往往很难看(长尾)。比如 90% 的人都得 0-5 分,只有几个 100 分。
- 如果你希望分数分布更像“正态分布”或者更平滑,可以在归一化前加一个 Log 变换 (
np.log1p),或者最后加一个 Sigmoid 变换。
- 分级 (Tiering):
- 老板不需要精确的 87.5 分。他需要的是:红灯 (High)、黄灯 (Medium)、绿灯 (Low)。
- 切分策略:
- High Risk: Top 1% (需要立即处理)。
- Medium Risk: Top 5% (需要关注)。
- Low Risk: 剩余 95%。

(图注:红黄绿灯策略将连续分数转化为可操作的业务决策。)
- 可解释性 (Explainability):
- 如果用户问“为什么我得了 100 分?”,你不能说“因为模型算的”。
- 你得能通过贡献度归因告诉他:“因为你的‘离群距离’贡献了 50 分(满分),‘低密度’贡献了 50 分(满分)。你既离得远,又很孤独。”
下一章预告
至此,我们的数学模型(聚类、降维、异常、评分)已经全部搭建完毕。
但是,这一堆数字(Risk=85, Cluster=3)对于业务人员来说还是天书。
- “Cluster 3 到底代表什么业务含义?”
- “这个 85 分的风险具体是指什么?”
如何让机器用人类的语言,告诉我们“这里发生了什么”?
LLM (大语言模型) 将作为最后一块拼图登场。



