


“以前我们教机器学数学,现在我们教机器读课文。”
在传统的无监督学习流程中,最大的痛点是“结果不可读”。
- 聚类结果:
Cluster_42。 - 异常结果:
Anomaly_Score = 98.5。 - 业务人员:???
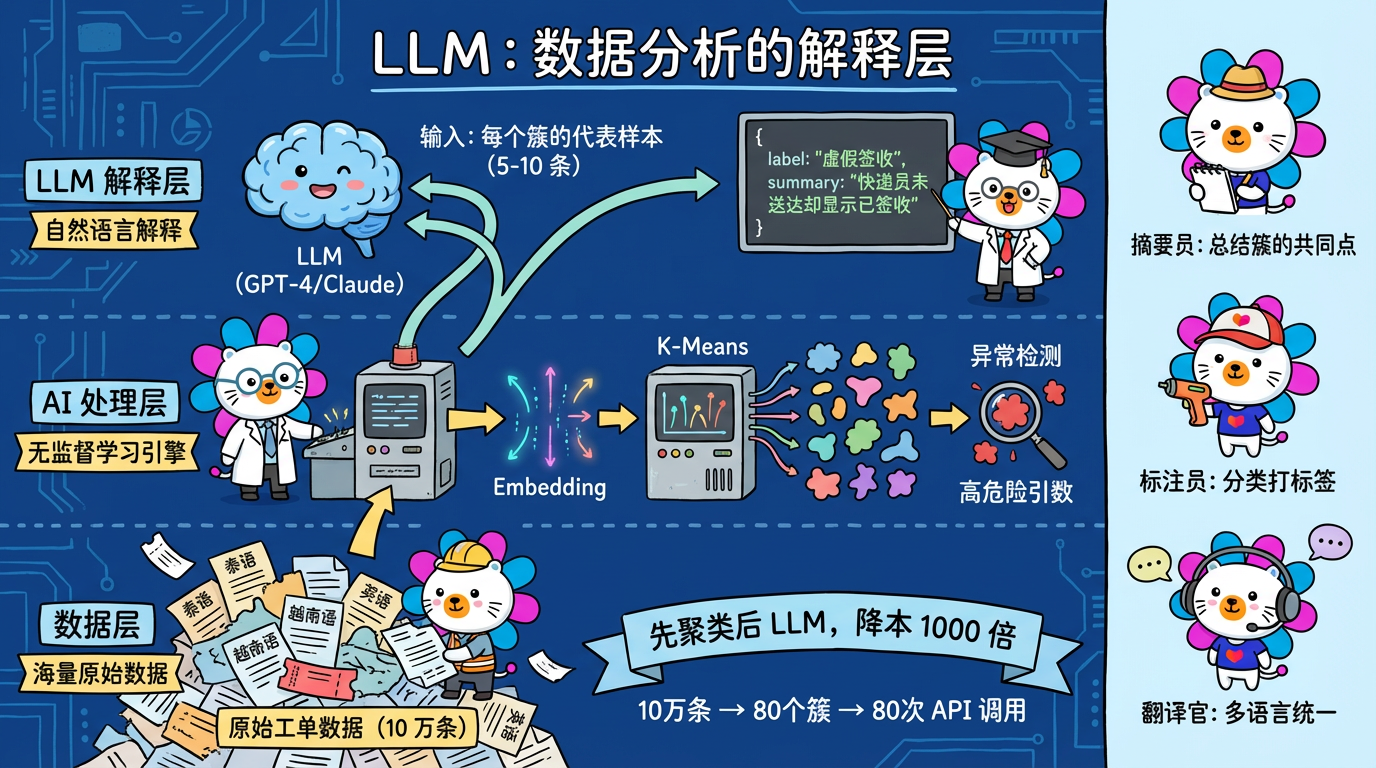
在大模型 (LLM) 时代,我们有了一种全新的范式:使用 LLM 作为这一流程的“解释层” (Interpretation Layer)。
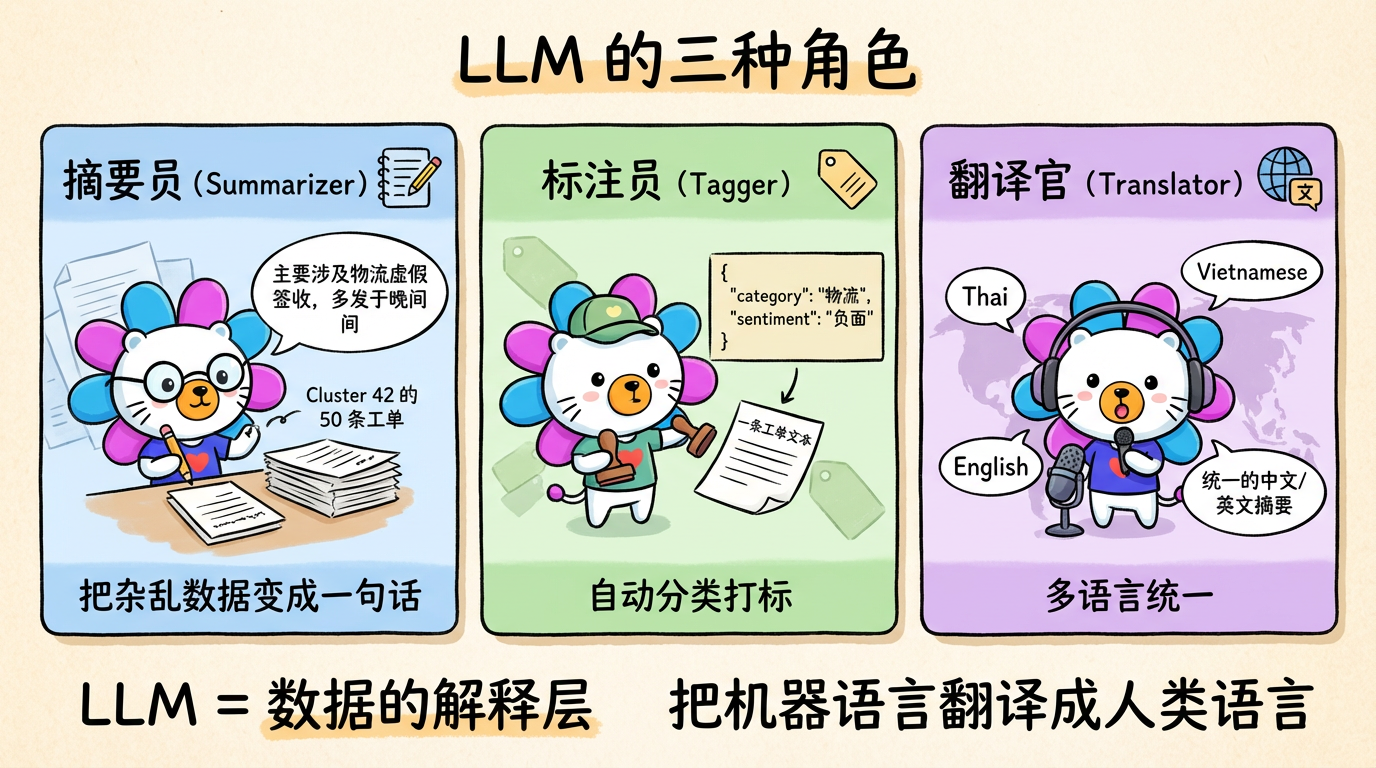
1. 核心概念:LLM 的三种角色
在数据分析链路中,LLM 可以扮演三种角色:
1.1 摘要员 (Summarizer)
这是最基础的用法。
- 输入:Cluster 42 中的 50 条工单文本。
- Prompt:请总结这些工单的共同投诉点。
- 输出:“主要涉及物流虚假签收,且多发生在晚间。”
1.2 标注员 (Tagger)
- 输入:一条工单。
- Prompt:请判断这属于【物流、支付、商品】中的哪一类?输出 JSON。
- 输出:
{"category": "物流", "sentiment": "负面"}
1.3 翻译官 (Translator)
- 输入:泰语、越南语混合文本。
- 输出:统一的英文/中文摘要。这是多语言文本分析系统的关键能力。
2. 技术对比:LLM vs 传统 NLP
| 任务 | 传统 NLP (TF-IDF/LDA) | LLM (GPT-4/Claude) |
|---|---|---|
| 关键词提取 | 提取出高频词(如 “please”, “help”),往往无意义 | 提取出语义关键词(如 “fake signature”) |
| 主题建模 | 主题词袋(”logistics, time, wait”),需要脑补 | 连贯的句子总结,包含因果关系 |
| 小样本能力 | 需要大量数据训练 | Zero-shot 或 Few-shot 即可工作 |
| 成本 | 几乎免费 | 昂贵 (API 调用费) |
| 速度 | 毫秒级 | 秒级 (慢) |
3. 代码实战:Prompt Engineering 实践
在实际项目中,需要设计精密的 Prompt 来确保 LLM 输出结构化数据。
1
2
3
4
5
6
7
8
9
10
# 代码示例
prompt = f"""
分析以下客服工单样本,提炼共同的业务场景。
样本:
{samples_text}
请严格按照以下 JSON 格式输出(不要有任何其他内容):
{{"label": "简短标题(10字内)", "summary": "一句话总结(50字内)"}}
"""关键技巧:
- System Constraints:明确“不要有其他内容”。
- Format Enforcing:指定 JSON 模板。
- Length Limit:限制字数,防止 LLM 写作文。
- Sampling:不要把几万条全发过去(太贵),每个簇只抽 5-10 条代表性样本。
4. 幻觉 (Hallucination) 与控制
LLM 最大的问题是胡说八道。
- 它可能编造出一个不存在的投诉原因。
- 它可能无视你的 JSON 格式要求。
解决方案:
- Temperature = 0:把随机性降到最低,让输出尽可能确定。
- Robust Parsing:代码里写好正则匹配,就算它加了 Markdown 符号也能提取出 JSON。
- Human in the Loop:关键的风险报告,最后一步必须由人审核。
5. 实践要点
- 聚类 + LLM = 黄金搭档:
- 先用 K-Means 把 10 万条数据聚成 80 类。
- 再用 LLM 读这 80 类(而不是读 10 万条)。
- 这是降低 LLM 成本最有效的方法(降本 1000 倍)。
- 上下文长度:注意 LLM 的 Context Window。如果样本太长,需要截断或分批摘要。
- 隐私问题:工单中可能包含手机号、地址。在发给 OpenAI 之前,必须在本地跑正则进行脱敏 (Masking)。
下一章预告:
我们用 Python 跑出了很棒的结果。
但是,能不能把这些结果固化下来?
能不能把 AI 的智慧“蒸馏”成简单的 SQL 规则,让它在数仓里每天自动跑?



