


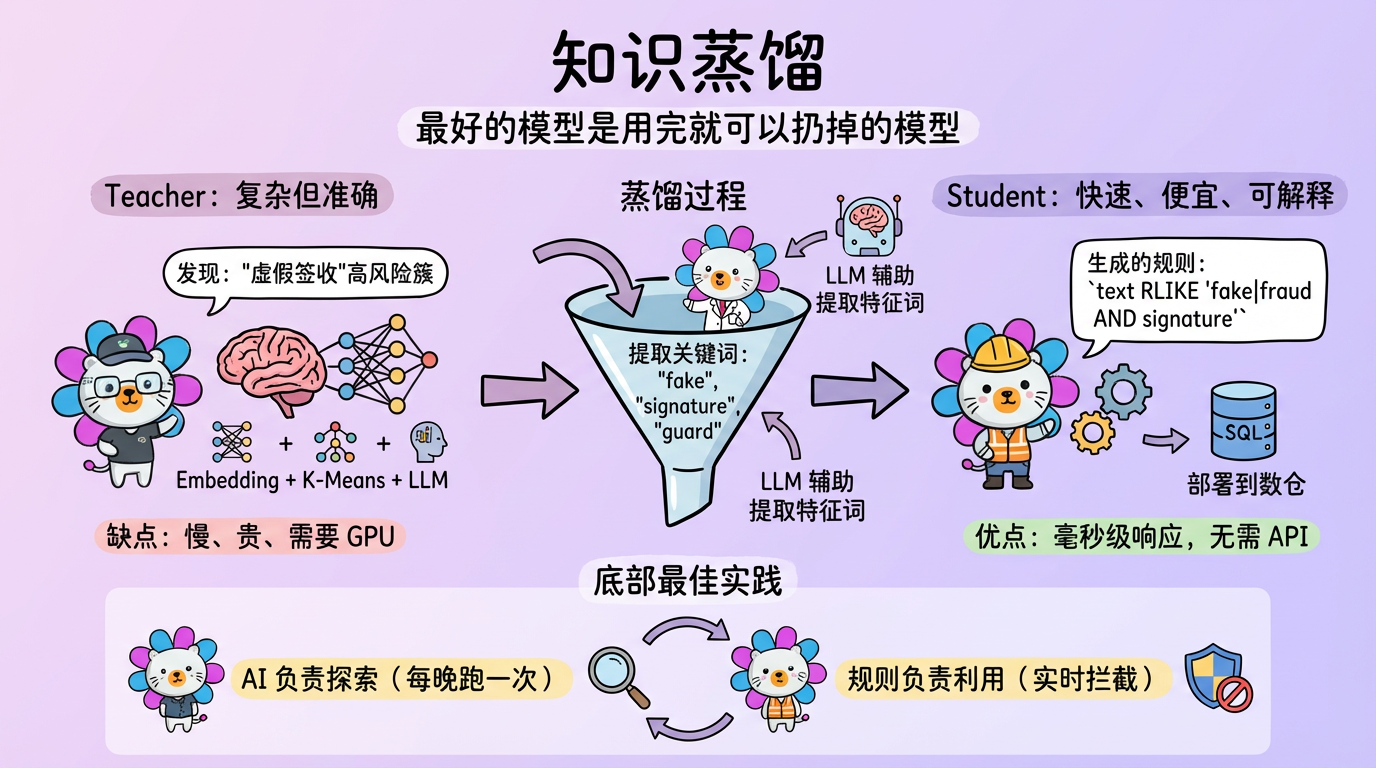
“最好的模型,是用完了就可以扔掉的模型。”
在 Python 里跑完聚类和 LLM 之后,我们得到了深刻的洞察。
但 Python 脚本难以处理亿级的实时数据流。
我们需要把 Python/AI 学到的知识,转移到更轻量级、更高效的系统(如 SQL 引擎、规则引擎)中去。
这一过程被称为 知识蒸馏 (Knowledge Distillation),或者更具体地说,规则提取 (Rule Extraction)。
1. 核心概念:Model-to-Rule
1.1 为什么需要规则?
- 性能:SQL
RLIKE比 Embedding 快一万倍。 - 成本:不需要调 API,不需要 GPU。
- 可解释性:规则是白盒(White-box),完全透明。
- 合规:某些行业要求必须能解释为什么拒绝了这笔交易。
1.2 蒸馏流程
- Teacher (AI):用 Embedding + KMeans + LLM 发现了一个高风险簇(例如“虚假签收”)。
- Extraction:分析这个簇里的文本,提取特征词(如
fake,signature,guard)。 - Student (Rule):生成一条正则规则:
text RLIKE '(fake|fraud) AND signature'。 - Deploy:把这条 SQL 部署到数仓。
2. 自动化 SQL 生成
在实际项目中,可以实现一个自动化脚本,将聚类结果转换为 SQL 规则。
2.1 关键词提取
使用 LLM 从每个簇中提取关键词。1
prompt = "请从以下文本中提取 5 个最具代表性的关键词(Regex 格式),用于匹配同类问题。"
2.2 规则组装
我们将关键词组装成 CASE WHEN 语句。
1
2
3
4
5
6
7
SELECT
CASE
WHEN text RLIKE 'fake sign|not receive' THEN 'High_Risk_Fake_Sign'
WHEN text RLIKE 'rude|shout' THEN 'Medium_Risk_Attitude'
ELSE 'Normal'
END as risk_label
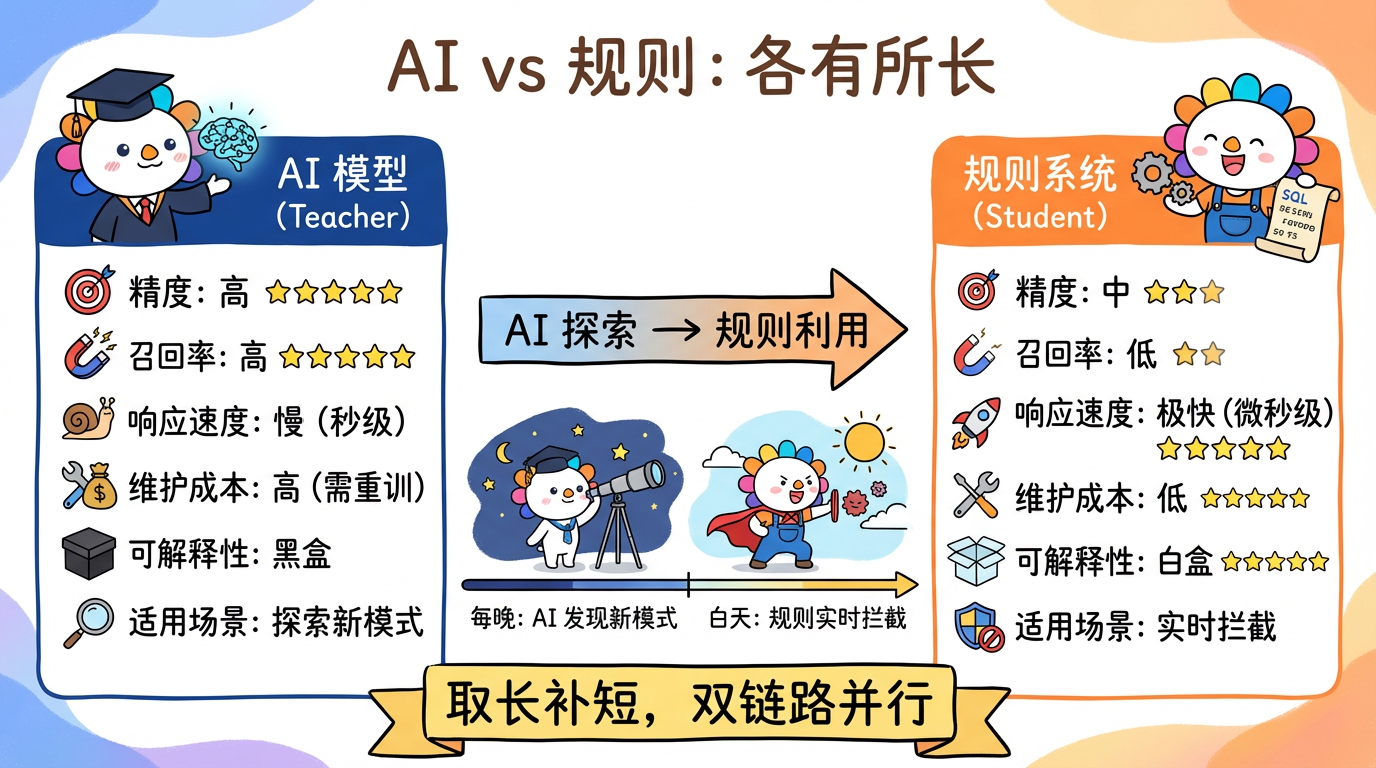
FROM logs;3. 技术对比:AI vs 规则
| 维度 | AI 模型 (Teacher) | 规则系统 (Student) |
|---|---|---|
| 精度 | 高 (泛化能力强) | 中 (容易漏抓变体) |
| 召回率 | 高 | 低 (覆盖不全) |
| 维护成本 | 高 (需重新训练) | 低 (改代码即可) |
| 响应速度 | 慢 (ms 级) | 极快 (us 级) |
| 冷启动 | 难 | 易 |
最佳实践:AI 负责“探索”,规则负责“利用”。
- 每天晚上跑一次 AI,发现新模式,生成新规则。
- 白天用规则系统实时拦截。
4. 决策树近似 (Decision Tree Approximation)
除了关键词提取,还可以用决策树来模仿复杂模型。
- 用复杂模型给数据打标(生成伪标签)。
- 用原始特征(如金额、时间)训练一棵浅层的决策树去拟合伪标签。
- 把决策树的路径翻译成 If-Then 规则。
5. 实践要点
- 准确率校验:自动生成的 SQL 必须在历史数据上回测。如果误伤率(False Positive)太高,不能上线。
- 多语言规则:对于多语言场景,需要生成多套关键词(或者先翻译再匹配)。
- 规则生命周期:规则是会“腐烂”的。随着业务变化,旧规则会失效。必须建立规则淘汰机制。
下一章预告:
最后,我们将视角拉高,看看如何构建一个工业级的无监督学习系统。
批处理还是流处理?如何处理断点续传?向量数据库怎么用?
这是从算法工程师进阶到架构师的必修课。



