


“算法只是冰山一角,工程才是水面下的巨兽。”
恭喜你,你已经掌握了无监督学习的所有核心算法。
但在实际工作中,写出算法代码可能只占 10% 的时间。
剩下的 90% 时间,你在处理:数据管道、异常恢复、性能优化、成本控制。
本章将以一个典型的文本分析系统为例,剖析工业级数据挖掘系统的架构设计。
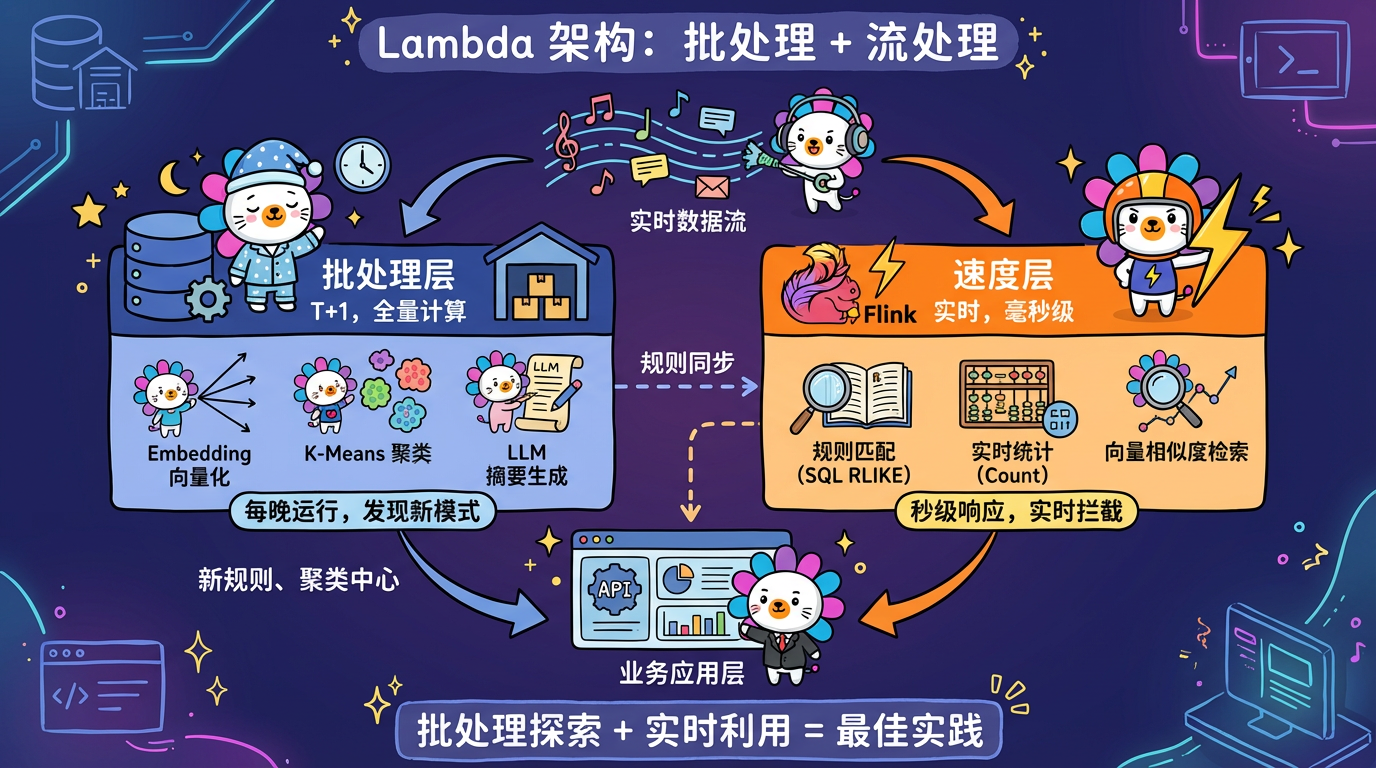
1. 核心概念:批处理 vs 流处理
1.1 批处理 (Batch Processing)
- 模式:T+1。每天凌晨把昨天的数据全量跑一遍。
- 适用:Embedding, KMeans, LLM 总结。这些算法很重,没法实时跑。
- 常见选择:文本分析系统通常采用批处理。因为”风险挖掘”通常不需要秒级响应,发现昨天的风险已经很有价值了。
1.2 流处理 (Stream Processing)
- 模式:实时。每来一条数据,立马处理。
- 适用:规则匹配 (SQL), 简单统计 (Count)。
- 架构:Flink / Flink SQL。
最佳实践 (Lambda 架构):
- Batch Layer:每晚跑重型 AI,生成新的规则/中心点。
- Speed Layer:实时用这些规则/中心点去过滤新数据。
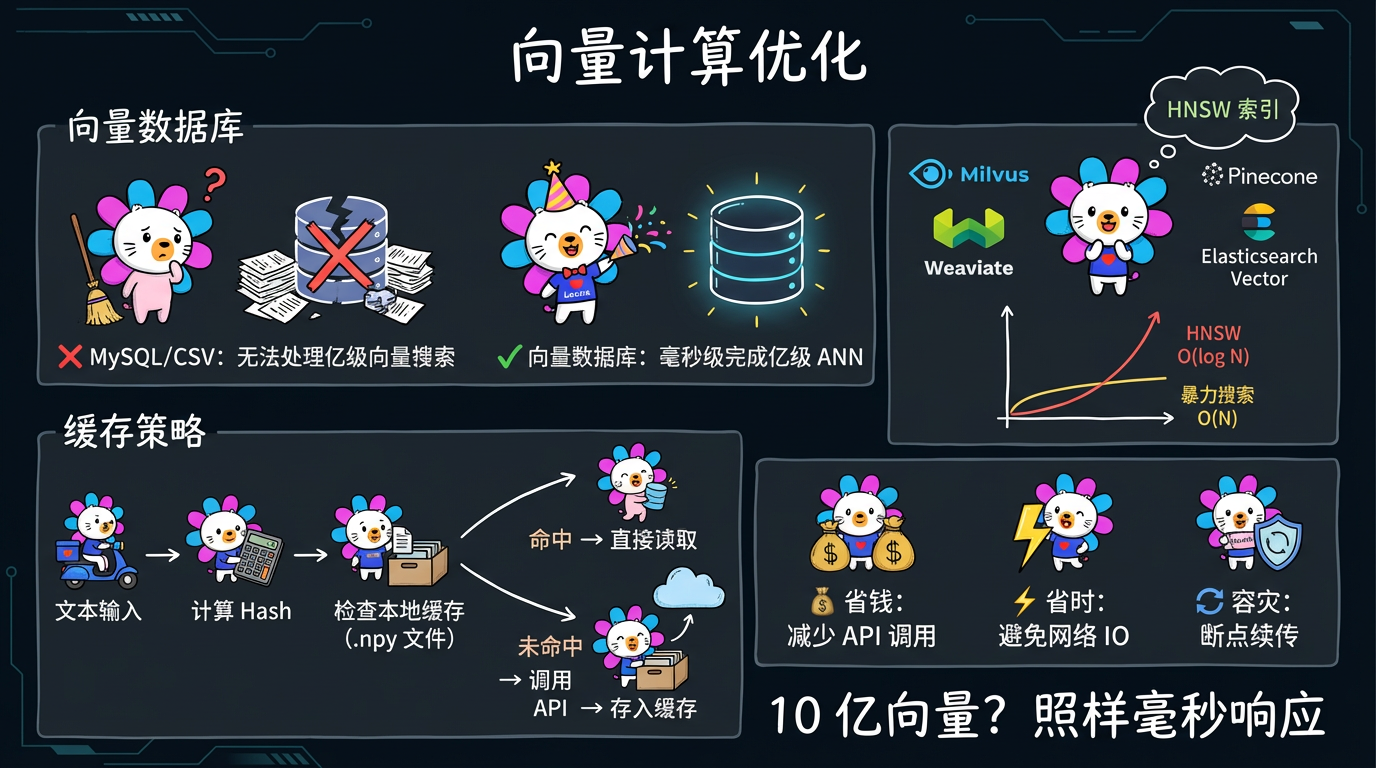
2. 向量计算优化
处理 100 万条向量很快,但处理 10 亿条呢?
2.1 向量数据库 (Vector DB)
不要把向量存 MySQL 或 CSV。
使用专门的向量数据库:Milvus, Pinecone, Weaviate, Elasticsearch (Vector)。
它们内置了 HNSW 索引,可以在毫秒级完成亿级数据的近似搜索 (ANN)。
2.2 缓存策略 (Caching)
在实际代码中,可以实现一个非常”暴力”但有效的缓存机制:1
2
3
4
5
6def get_embeddings_batch(texts):
# 计算文本 Hash
texts_hash = compute_texts_hash(texts)
# 检查本地是否有 .npy 文件匹配这个 Hash
# 如果有,直接读取;如果没有,调用 API 并缓存
# ...
为什么要这样?
- 省钱:OpenAI API 很贵。
- 省时:网络 IO 很慢。
- 容灾:如果程序跑到 99% 崩了,下次重启能直接从缓存读,不需要重跑。
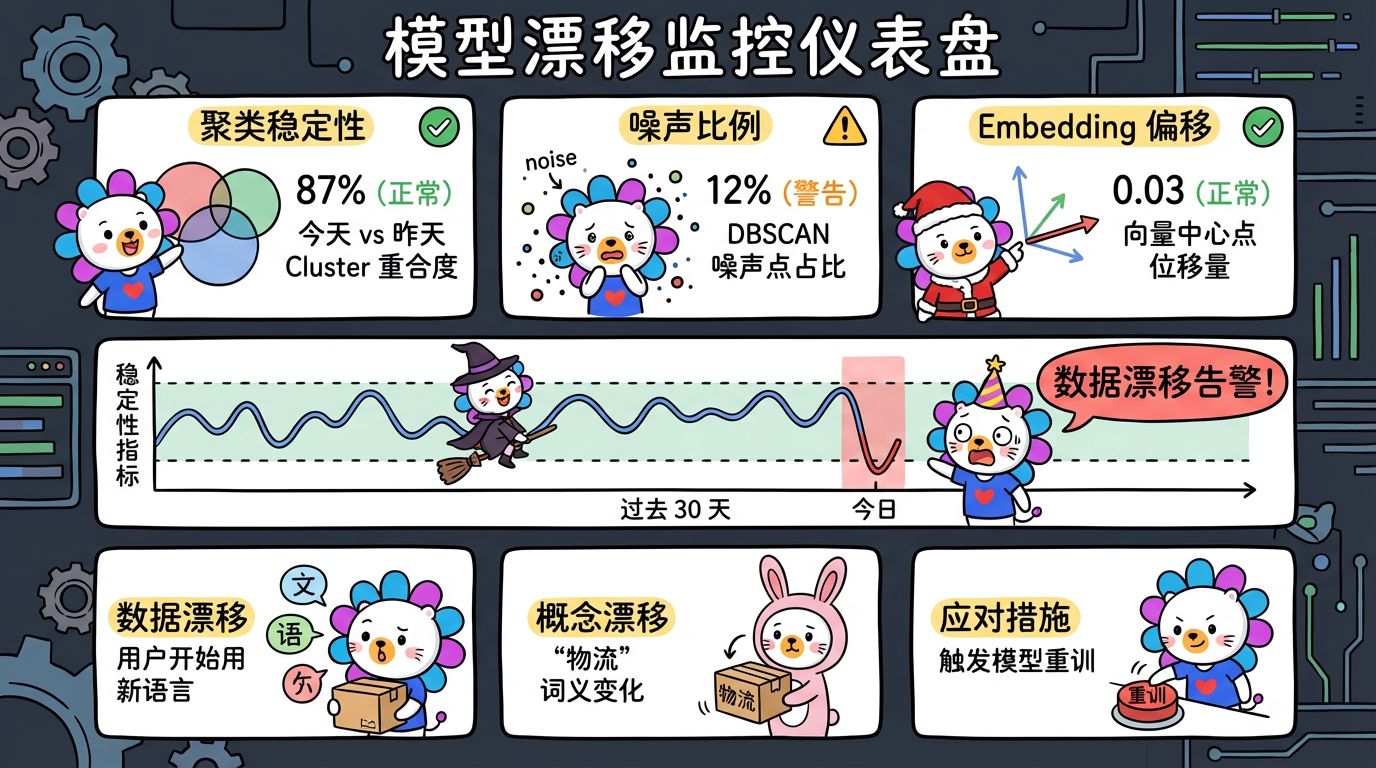
3. MLOps:模型监控
无监督学习最怕模型漂移 (Model Drift)。
- 数据漂移:用户突然开始用一种新的语言投诉。
- 概念漂移:原本属于”物流”的词,现在变成了”诈骗”的词。
监控指标:
- 聚类稳定性:今天的 Cluster 1 和昨天的 Cluster 1 重合度多少?
- 噪声比例:如果 DBSCAN 的噪声点比例突然从 5% 飙升到 50%,说明模型失效了,需要重训。
- Embedding 分布:监控向量空间的中心点是否发生了显著位移。
4. 结语:AI 分析师的未来
我们正处于一个时代的转折点。
- 过去:分析师用 Excel 和 SQL 手动挖掘数据。
- 现在:算法工程师用 Python 和 K-Means 辅助挖掘。
- 未来:AI Agent 自动巡检数据,自动调用工具(聚类、降维),自动生成报告,并主动向人类预警。
无监督学习,是通往 通用人工智能 (AGI) 的必经之路。因为只有学会了无监督学习,机器才能像人类婴儿一样,通过观察世界来通过常识,而不是永远依赖人类的喂养(标注数据)。
希望这套教程能成为你探索数据宇宙的罗盘。
愿你的数据里,永远藏着黄金。
📚 附录:核心技术栈清单
| 领域 | 核心库/工具 |
|---|---|
| 数据处理 | Pandas, NumPy, Spark |
| 机器学习 | Scikit-Learn (KMeans, IsolationForest) |
| 降维可视化 | UMAP-learn, Plotly |
| Embedding | OpenAI API, HuggingFace Transformers |
| 向量检索 | Faiss, Milvus |
| 大语言模型 | LangChain, OpenAI |
(全书完)



