


“地球是圆的,但地图是平的。把球面画成平面的过程,就是流形学习。”
PCA 假设数据分布在一个平坦的超平面上。但现实世界的数据往往是卷曲的、扭曲的。
经典的例子是 “瑞士卷” (Swiss Roll) 数据集。数据像一块卷起来的地毯。
如果你直接用 PCA 从侧面压扁它(线性投影),原本相隔很远的两层会叠在一起,红色的点和蓝色的点就混淆了。这就叫投影混叠。
我们需要把这个卷小心翼翼地展开,就像把地毯铺平一样。这叫 流形学习 (Manifold Learning)。
1. 核心概念:流形假设 (Manifold Hypothesis)
流形学习基于一个大胆的假设:
虽然数据看起来维数很高(比如 1536 维),但它们其实只分布在一个维数很低的流形(比如 2 维曲面)上。
1.1 什么是“流形”?
流形 (Manifold) 是一个拓扑学概念。通俗地说,它是一个局部看起来是欧氏空间,但整体结构复杂的空间。
- 例子:地球表面。
- 局部:你在操场上跑步,地面是平的(2维平面)。
- 整体:地球是圆的(嵌在3维空间里的2维球面)。
1.2 测地距离 (Geodesic Distance)
在瑞士卷上,点 A 和点 B 可能在三维空间中离得很近(欧氏距离小),但如果你是一只生活在瑞士卷表面的蚂蚁,你要从 A 爬到 B,你需要沿着卷面绕很多圈(测地距离大)。
- 欧氏距离 (Euclidean Distance):直线穿墙而过。对于卷曲数据,这是一种欺骗性的距离。
- 测地距离 (Geodesic Distance):沿着曲面行走。这是数据的真实距离。
流形学习的核心任务,就是试图恢复这种测地距离,并把它在低维空间中展示出来。

(图注:虚线是欧氏距离(短但错误),实线是测地距离(长但正确)。蚂蚁不能飞,它必须爬过实线。)
2. 经典算法:Isomap (等距映射)
Isomap 是流形学习的鼻祖之一。它的思想极其朴素:既然测地距离才是真理,那我们就直接算测地距离!
2.1 算法三部曲
- 构图 (Graph Construction):
- 对于每个点,找到它的 K 个最近邻(比如 K=5)。
- 把这些点连起来。
- 隐喻:这就像在数据表面铺设了一张渔网。渔网只能连接相邻的节点。
- 算距离 (Shortest Path):
- 计算图中任意两点间的最短路径。
- 使用 Dijkstra 或 Floyd 算法。
- 原理:虽然 A 和 B 离得远,但我们可以通过 A -> C -> D -> E -> B 一步步跳过去。所有跳跃距离之和,近似等于测地距离。
- 降维 (MDS):
- 把计算好的“测地距离矩阵”丢进 MDS (多维缩放) 算法。
- MDS 会寻找一个新的低维坐标系,使得新坐标系下的欧氏距离尽可能等于输入的测地距离。
2.2 优缺点分析
- 优点:全局结构保持得很好。它能完美展开瑞士卷,保留长宽比例。
- 缺点:
- 慢! 计算所有点对的最短路径是 $O(N^3)$ 的噩梦。数据量超过 5000 就跑不动了。
- 短路风险:如果 K 设得太大,或者有噪声点,可能会在两个本该分开的卷面之间搭一座桥。蚂蚁会直接走捷径,导致展开失败。
3. 经典算法:LLE (局部线性嵌入)
LLE 代表了另一种流派:局部派。它的思想是:地球是圆的,但你脚下的篮球场是平的。
3.1 算法逻辑:拼图游戏
- 局部重构 (Local Reconstruction):
- 对于每个点 $x_i$,找它的邻居。
- 试着用邻居的线性组合来表示它:$x_i \approx \sum_j w_{ij} x_j$。
- 目标:找出一组权重 $w$,使得重构误差最小。
- 隐喻:这一步是在记录每个点和邻居的相对几何关系(比如:我在张三左边 1 米,李四右边 2 米)。
- 全局降维 (Global Alignment):
- 在低维空间找对应的点 $y_i$。
- 核心约束:这些点必须保持同样的线性组合关系(权重 $w_{ij}$ 不变)。
- $y_i \approx \sum_j w_{ij} y_j$。
- 隐喻:这就像玩拼图。只要每块拼图和它周围拼图的咬合关系不变,整个拼图怎么弯曲、怎么平铺都可以。
3.2 优缺点分析
- 优点:可以解开极其卷曲的流形。对局部细节保留得很好。
- 缺点:
- 对噪声极其敏感。
- 数据挤压:往往把数据挤在中间,难以保持全局几何形状。
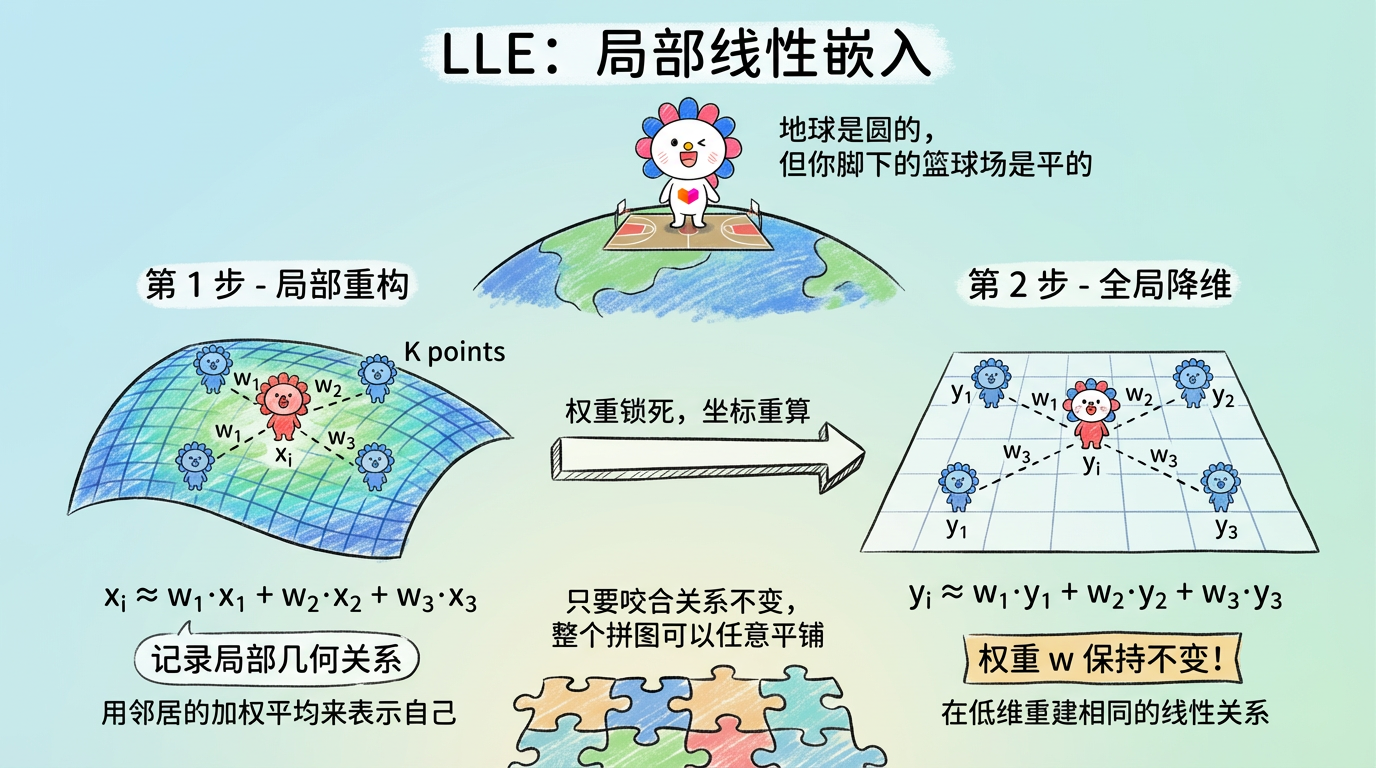
(图注:左图是高维卷曲状态,右图是低维展开状态。虽然形状变了,但每个小红点相对于蓝点的相对位置(权重)是锁死的。)
4. 维度灾难:流形学习的噩梦
你可能会问:既然流形学习这么好,为什么没一统天下?
因为有一个幽灵一直盘旋在数据科学上空:维度灾难 (The Curse of Dimensionality)。
在高维空间(如 1000 维):
- 距离失效:所有点之间的欧氏距离都趋于相等。Isomap 的“最近邻”可能根本不是真的近。
- 数据稀疏:数据像撒在沙漠里的几粒沙子。要填满 1000 维空间,需要的数据量是天文数字。流形甚至可能是不连通的(断裂的)。
这就是为什么传统的 Isomap 和 LLE 在工业界(面对稀疏、高维、含噪的真实数据)往往效果不佳。我们需要更鲁棒的算法——于是 t-SNE 和 UMAP 应运而生。
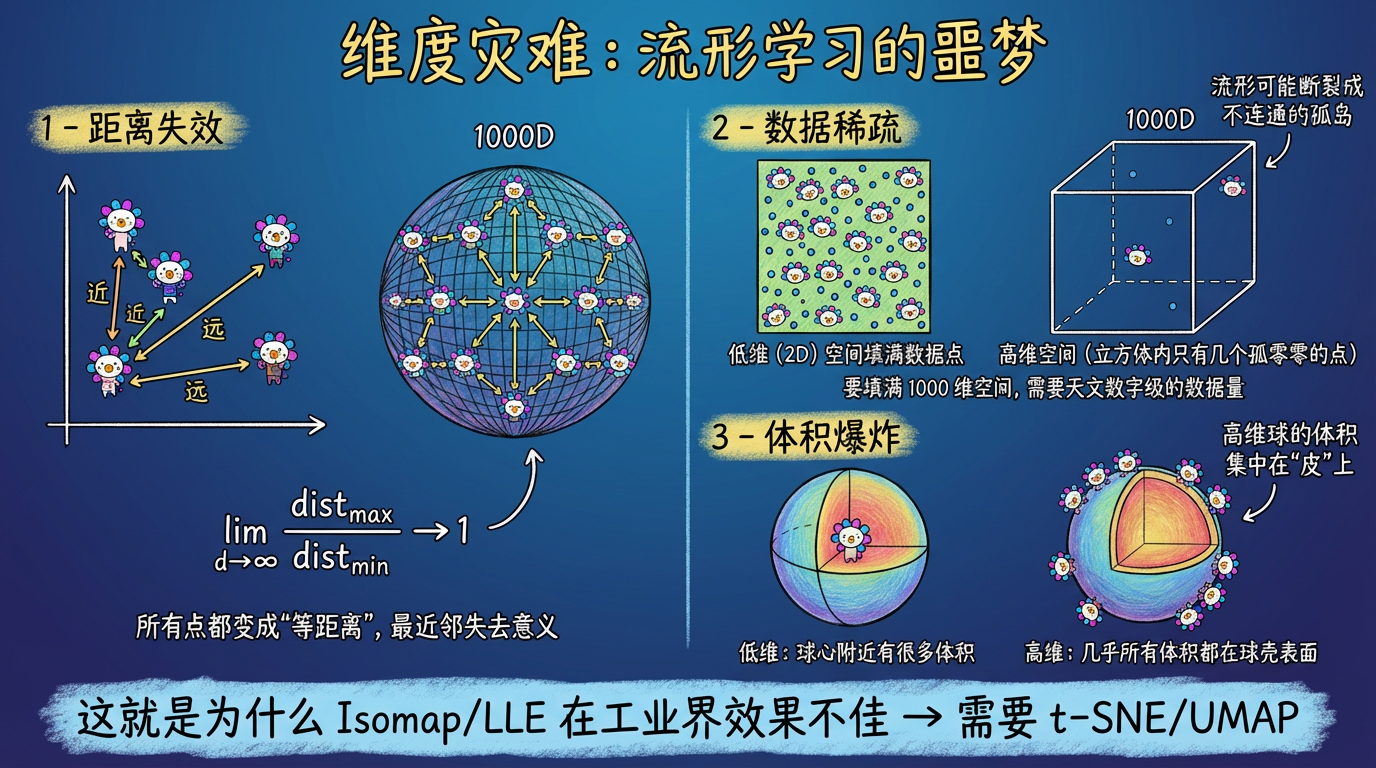
(图注:高维空间中,距离失效、数据稀疏、体积集中在表面。这是流形学习的噩梦。)
5. 代码实战:展开瑞士卷
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
from sklearn import manifold, datasets
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 1. 生成瑞士卷数据
# n_samples=1500: 数据点数量
# noise=0.0: 纯净的瑞士卷。如果设为 0.5,Isomap 就会因为短路而崩溃。
X, color = datasets.make_swiss_roll(n_samples=1500, noise=0.0)
# 2. 降维算法对比
# A. Isomap (展开)
# n_neighbors=10: 连接最近的 10 个点
X_iso = manifold.Isomap(n_neighbors=10, n_components=2).fit_transform(X)
# B. LLE (局部重构)
X_lle = manifold.LocallyLinearEmbedding(n_neighbors=10, n_components=2).fit_transform(X)
# C. t-SNE (作为对比)
# 这是一个概率方法,我们将在下一章详细讲
X_tsne = manifold.TSNE(n_components=2, perplexity=30, init='pca', random_state=42).fit_transform(X)
# 3. 绘图
fig = plt.figure(figsize=(20, 5))
# 原始 3D 数据
ax = fig.add_subplot(141, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=color, cmap=plt.cm.Spectral)
ax.view_init(4, -72)
ax.set_title("Original Swiss Roll (3D)")
# Isomap 结果
ax = fig.add_subplot(142)
ax.scatter(X_iso[:, 0], X_iso[:, 1], c=color, cmap=plt.cm.Spectral)
ax.set_title("Isomap (Unrolled)")
# 预期:完美的长方形,颜色渐变均匀。
# LLE 结果
ax = fig.add_subplot(143)
ax.scatter(X_lle[:, 0], X_lle[:, 1], c=color, cmap=plt.cm.Spectral)
ax.set_title("LLE (Unrolled)")
# 预期:也是长方形,但可能形状有点扭曲。
# t-SNE 结果
ax = fig.add_subplot(144)
ax.scatter(X_tsne[:, 0], X_tsne[:, 1], c=color, cmap=plt.cm.Spectral)
ax.set_title("t-SNE (Fragmented)")
# 预期:数据断裂成几块。t-SNE 不保证连续性。
plt.show()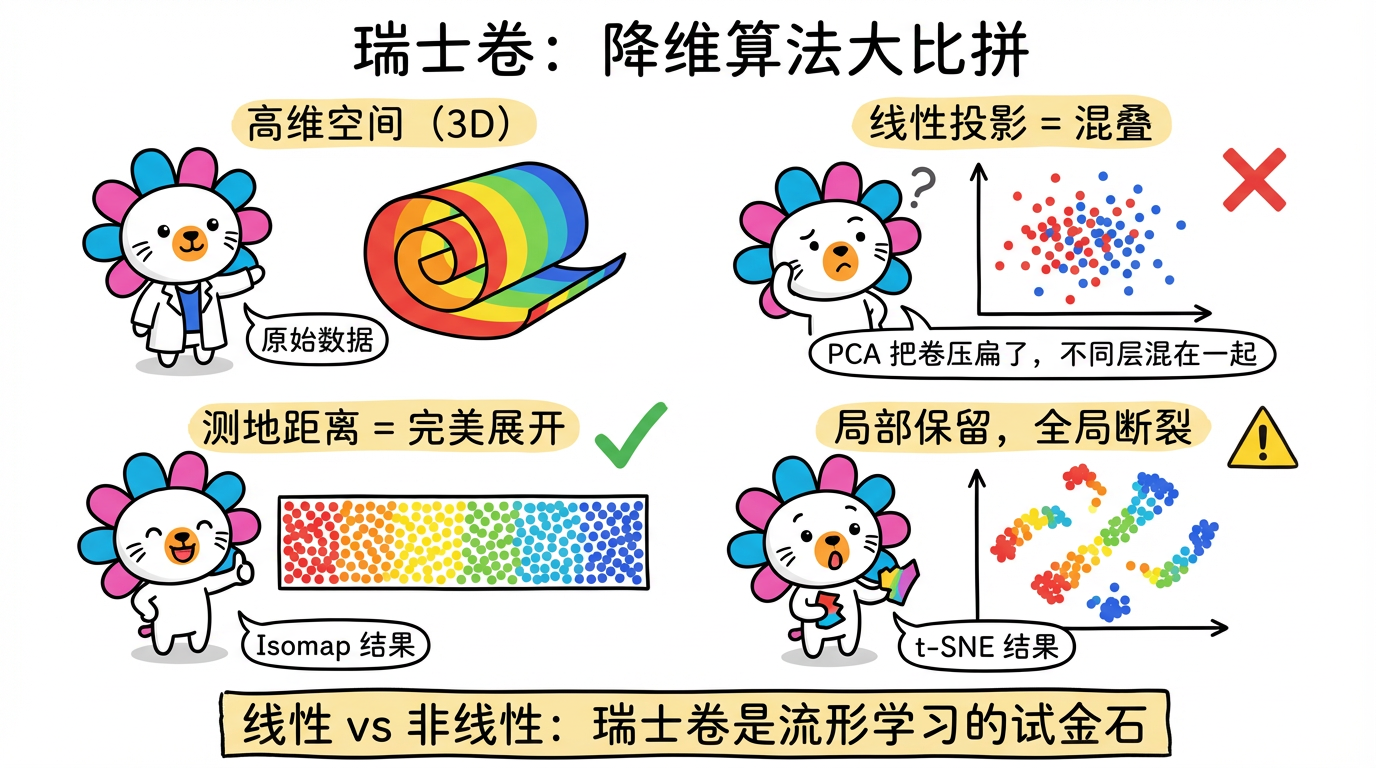
(图注:PCA 混叠、Isomap 完美展开、t-SNE 断裂。瑞士卷是流形学习的试金石。)
6. 实践要点
- 邻居数 (K / n_neighbors):这是所有流形学习算法最重要的“超参数”。
- K 太小:图不连通,数据像饼干一样碎裂成孤岛。
- K 太大:引入了“短路”连接(横跨卷面的错误边),导致卷曲没解开,反而被压扁了。
- 技巧:如果你不知道 K 选多少,试着画出 K 与“残差方差”的关系图,找拐点。
- 工业界现状:
- Isomap / LLE:学院派。理论优美,但计算复杂度太高 ($O(N^2)$ 或 $O(N^3)$),且对噪声太敏感。主要用于教学。
- t-SNE / UMAP:实战派。虽然理论复杂(涉及概率和拓扑),但它们通过近似算法(如 Barnes-Hut 树)解决了计算效率问题,且对噪声有很强的容忍度。
下一章预告
终于轮到 t-SNE 登场了。它放弃了严谨的几何距离,转而投向了概率统计的怀抱。
- 它是怎么做到在二维屏幕上把 MNIST 的 10 个数字分得那么开的?
- 为什么它叫 “t”-SNE?这个 “t” 和学生 t 分布有什么关系?
- 为什么说它是“可视化之王”?



