


“最好的数据压缩算法,不是 zip,而是理解数据的结构。”
我们生活在一个高维数据爆炸的时代。
- 图像:一张 100x100 像素的小头像,如果展平,就是 10,000 维的向量。
- 文本:一段包含 512 个 token 的文本,如果用 Embedding 表示,通常是 768 维或 1536 维。
- 用户画像:一个电商用户的特征,可能包含点击历史、购买力、地理位置等几千个指标。
在这些成千上万的维度中,往往充斥着冗余(比如“出生年份”和“年龄”完全相关)和噪声(比如图片边缘的随机噪点)。
降维 (Dimensionality Reduction) 的目标很简单:去粗取精。把那些冗余的、噪声的维度扔掉,只保留最核心的信息。这不仅能减少存储空间,更能让后续的聚类算法(如 K-Means)跑得更快、更准。
本章我们将介绍降维领域的鼻祖——主成分分析 (PCA)。虽然它诞生于 1901 年,虽然它是线性的,但它依然是目前最常用、最稳健的数据预处理工具。它是数据科学家的“瑞士军刀”。
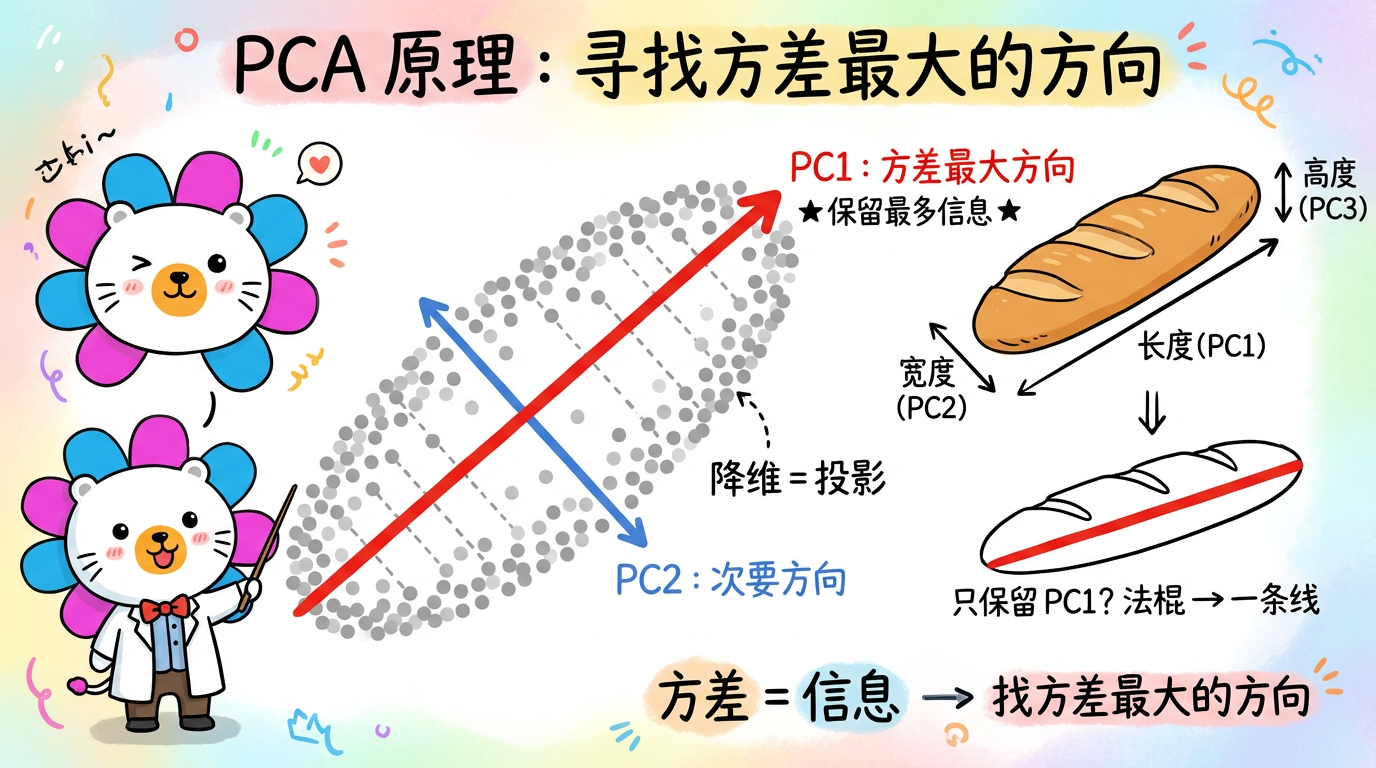
(图注:数据像一个扁平的法棍面包。PCA 找到了面包的主轴,让我们能忽略厚度,只看长度。)
1. 核心概念:为什么“方差”就是“信息”?
在学习 PCA 之前,我们必须达成一个共识:方差 (Variance) = 信息 (Information)。
1.1 一个直观的例子:学生成绩
假设我们有一个班级的成绩单,包含两个特征:
- 数学成绩:大家的分别很大。学霸考 100 分,学渣考 0 分。分数分布在 [0, 100] 之间,方差很大。
- 体育成绩:大家都差不多。基本都在 [80, 85] 之间,方差很小。
如果我们被迫只能保留一个特征来区分这些学生,你会选哪个?
当然是数学成绩。
- 因为数学成绩方差大,能把学生区分开(提供了信息)。
- 体育成绩方差小,大家都一样,提供了很少的信息(甚至接近常数)。
结论:在降维时,我们总是希望保留那些方差最大的方向,扔掉那些方差极小的方向(因为那通常是噪声或常数)。
1.2 PCA 的思想:换个角度看世界
PCA 的核心任务是:旋转坐标轴。它要找到一个新的坐标系,使得数据在新坐标轴上的投影方差最大。
想象一个法棍面包(数据云)悬浮在空中:
- 原始坐标系 (X, Y, Z):这是人为设定的,比如 X 代表“面粉量”,Y 代表“烘焙时间”。这跟面包的几何形状可能没关系。
- PCA 坐标系 (PC1, PC2, PC3):这是由数据决定的。
- 主成分 1 (PC1):沿着法棍最长的方向。在这个方向上,数据分布最广(方差最大)。保留它,我们就保留了面包的主要长度。
- 主成分 2 (PC2):沿着法棍宽度的方向。这是仅次于长度的第二大方差方向。
- 主成分 3 (PC3):沿着法棍厚度的方向。这是方差最小的方向。
如果我们只能保留 1 个维度,我们肯定选 PC1。这样我们就能用一条线来近似这根法棍,虽然丢失了宽度和厚度,但保留了物体最大的特征。
2. 数学推导:一步步拆解 PCA
这部分包含核心的线性代数原理,理解它能让你明白 PCA 为什么会失败(以及什么时候会失败)。
第一步:中心化 (Centering)
先把数据的中心挪到原点 $(0,0)$。
$$ X_{new} = X - \mu $$
为什么? 因为 PCA 是基于旋转的。如果不把数据挪到原点,旋转轴就会乱套。就像转动地球仪,必须围绕地心转一样。
第二步:计算协方差矩阵 (Covariance Matrix)
计算矩阵 $\Sigma = \frac{1}{N} X^T X$。
这个矩阵描述了特征之间是如何“联动”的。
- $\Sigma_{ij} > 0$:特征 i 变大,特征 j 也变大(正相关)。
- $\Sigma_{ij} = 0$:特征 i 和 j 不相关(正交)。
- $\Sigma_{ij} < 0$:特征 i 变大,特征 j 变小(负相关)。
PCA 的目标其实就是去除相关性。在新的坐标系里,所有特征应该是不相关的(协方差为 0)。
第三步:特征值分解 (Eigen-decomposition)
这是 PCA 的灵魂。我们需要求解协方差矩阵的特征方程:
$$ \Sigma v = \lambda v $$
- 特征向量 $v$ (Eigenvector):它指出了新坐标轴的方向(法棍的朝向)。在 PCA 中,它们被称为“主成分方向”。
- 特征值 $\lambda$ (Eigenvalue):它代表了这个方向上的方差大小(法棍有多长)。
第四步:排序与截断
- 算出所有的特征值和特征向量。
- 按特征值 $\lambda$ 从大到小排序。
- 截断:如果你想降到 $k$ 维,就只取前 $k$ 个特征向量。
- 投影:把原始数据 $X$ 投影到这 $k$ 个向量上,得到降维后的数据。
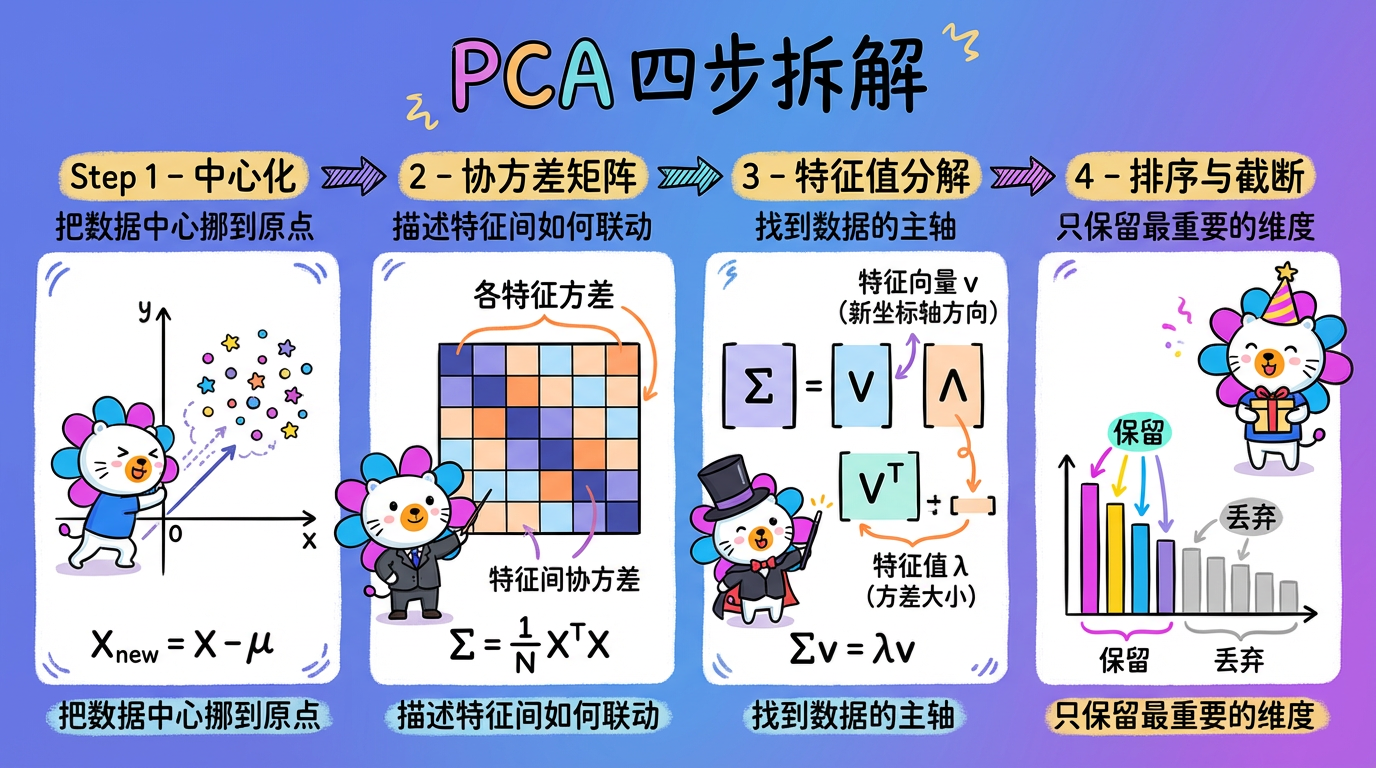
(图注:中心化 → 协方差矩阵 → 特征值分解 → 排序截断。四步完成降维。)
3. 技术对比:线性与非线性
PCA 是线性的,这意味着它只能做“旋转”和“拉伸”,不能做“弯曲”。
| 算法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| PCA | 方差最大化 (线性) | 快 (矩阵运算),可解释 (知道哪个特征重要),无参数 (不用调参) | 处理不了非线性流形 (如瑞士卷),容易受离群点影响 (方差会被极值拉偏) | 图像压缩,去噪,预处理,特征工程 |
| t-SNE | 概率分布匹配 (非线性) | 可视化效果极佳,分堆明显 | 慢,丢失全局结构,不可逆 (不能用于新数据) | 2D/3D 可视化 |
| UMAP | 拓扑流形 (非线性) | 比 t-SNE 快,兼顾全局与局部 | 理论复杂 | 2D/3D 可视化,特征提取 |
| Autoencoder | 神经网络 (非线性) | 极其灵活,可处理超大规模数据 | 黑盒,训练难 | 深度学习管道 |
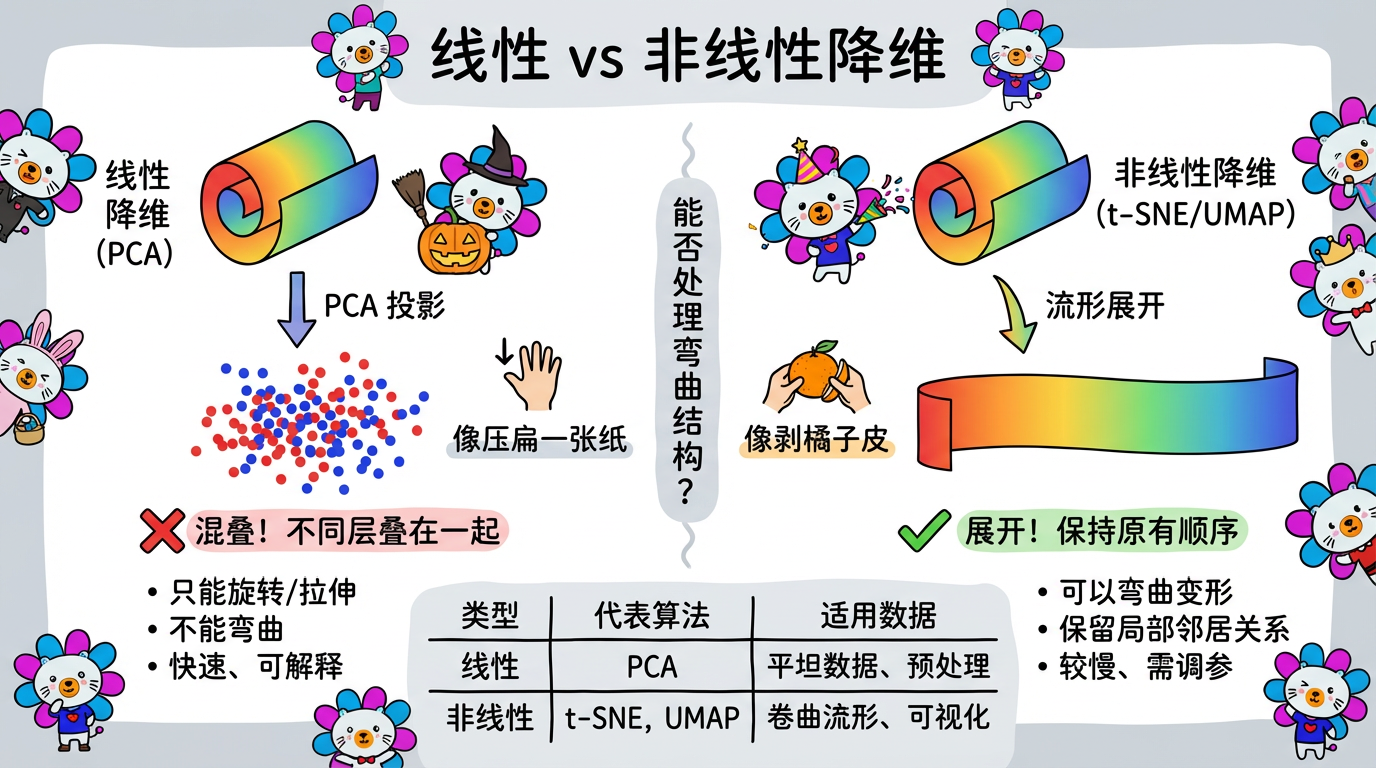
(图注:左边:PCA 只能像压扁一张纸一样降维。右边:非线性算法可以像剥橘子皮一样把弯曲的表面展开。)
4. 代码实战:Scikit-Learn 实现 PCA
我们来模拟一个实际场景:把一个拉长的、旋转过的椭圆数据降维。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
import numpy as np
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 1. 准备数据
# 生成一个拉长的椭圆数据 (2D),带有旋转
# 我们可以把这想象成:身高(X) 和 体重(Y) 的关系,它们是高度相关的
rng = np.random.RandomState(1)
X = np.dot(rng.rand(2, 2), rng.randn(2, 200)).T
# 2. 预处理 (关键步骤!)
# PCA 对量纲极其敏感。如果 X 的单位是毫米(0-2000),Y 的单位是米(0-2),
# 毫米的方差会远远大于米,导致 PCA 认为只有 X 重要。
# 所以必须用 StandardScaler 把它们都变成标准正态分布。
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 训练 PCA
# n_components=2: 这里我们先不降维,保留所有成分,看看每个成分的权重
pca = PCA(n_components=2)
pca.fit(X_scaled)
# 4. 结果分析
print("--- PCA 分析报告 ---")
print(f"主成分方向 (特征向量):\n{pca.components_}")
print(f"每个方向的方差 (特征值): {pca.explained_variance_}")
print(f"方差解释率 (重要性): {pca.explained_variance_ratio_}")
# 输出示例: [0.97, 0.03]
# 含义:第一个主成分包含了 97% 的信息,第二个只包含了 3%(可能是噪声)。
# 5. 降维
# 既然 PC2 只有 3% 的信息,我们可以放心地扔掉它,只保留 1 维
pca_1d = PCA(n_components=1)
X_pca = pca_1d.fit_transform(X_scaled)
print(f"\n降维后形状: {X_pca.shape}") # (200, 1)
# 6. 数据还原 (Inverse Transform)
# 我们可以把降维后的数据还原回去,看看丢掉了多少信息
X_restored = pca_1d.inverse_transform(X_pca)
# 7. 绘图对比
plt.figure(figsize=(10, 5))
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], alpha=0.3, label='Original')
plt.scatter(X_restored[:, 0], X_restored[:, 1], alpha=0.8, color='red', label='Restored')
plt.legend()
plt.title('PCA Compression & Restoration')
# 你会看到红色的点完美地排成了一条直线,这就是 PCA 找到的“主轴”
plt.show()5. 实践避坑指南
5.1 必须先归一化 (Normalization)
这是新手最容易犯的错误。
- 错误案例:一个特征是“年收入”(几万到几百万),另一个特征是“年龄”(0到100)。
- 后果:PCA 算方差时,会发现“年收入”的方差是 $10^{10}$ 级别,而“年龄”只有 $10^2$。于是 PCA 认为只有“年收入”重要,直接把“年龄”当噪声扔了。
- 正确做法:使用
StandardScaler,把所有特征都缩放到 均值=0,方差=1。让大家站在同一起跑线上比拼相关性。
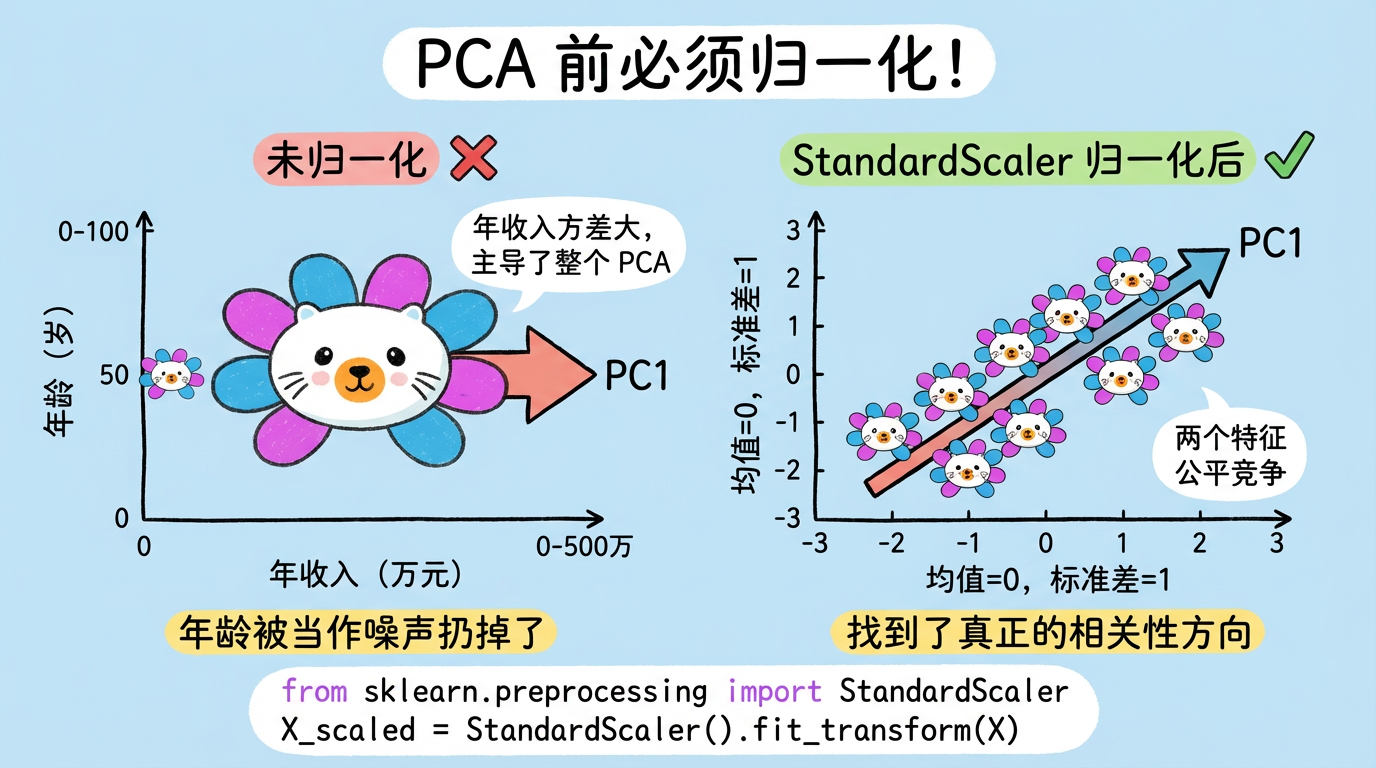
(图注:左图未归一化,年收入主导了 PCA;右图归一化后,两个特征公平竞争。)
5.2 如何选择 K 值?(方差解释率)
我们不需要拍脑袋决定降到几维。PCA 给了我们一个科学的指标:解释方差比 (Explained Variance Ratio)。
- 可视化法:画出
cumsum(pca.explained_variance_ratio_)曲线。 - 95% 准则:通常我们希望保留原始数据 95% 的信息量。
- 在 sklearn 中,你可以直接设
PCA(n_components=0.95)。 - 算法会自动计算需要多少个维度才能凑够 95% 的方差。
- 对于 768 维的 BERT 向量,通常 50-100 维就能保留 99% 的信息。这说明 BERT 向量里有大量的冗余!
- 在 sklearn 中,你可以直接设
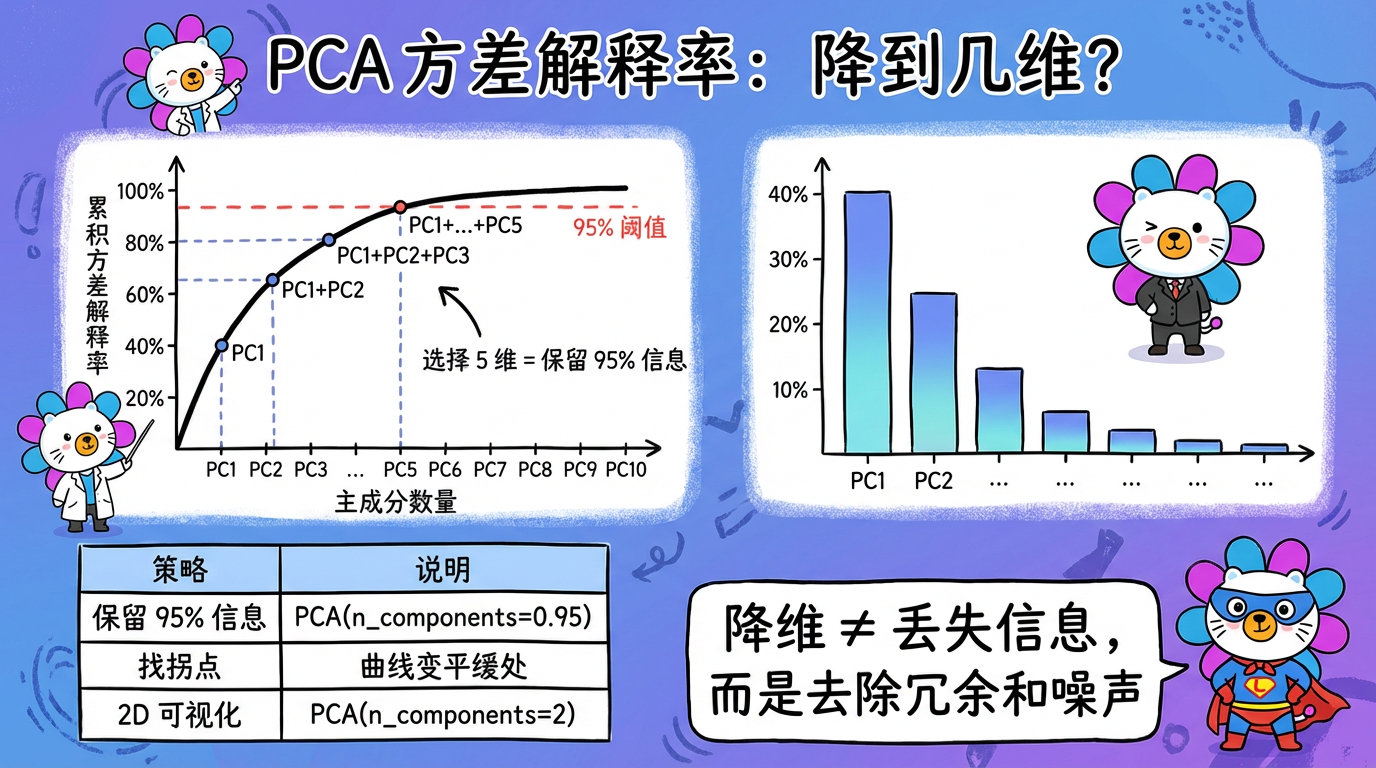
(图注:横轴是维度数量,纵轴是累计解释的方差百分比。曲线通常在开始时急剧上升,然后变平。拐点处就是最佳截断点。)
5.3 PCA 作为“前菜”
在跑 t-SNE 或 UMAP 之前,通常强烈建议先跑一遍 PCA。
- 目的:把维度从 10000 (图片) 或 1536 (文本) 降到 50。
- 好处:
- 去噪:扔掉了那些只有 0.01% 方差的噪声维度,让后续算法看得更清楚。
- 加速:t-SNE/UMAP 的计算复杂度与维度有关。先降维能让后续算法快几十倍。
下一章预告
PCA 只能处理“平坦”的数据。如果数据像一个瑞士卷蛋糕一样卷在一起,PCA 这一刀切下去,红色的层和蓝色的层就混在一起了。
为了小心翼翼地展开这个卷,我们需要引入测地距离的概念。这就进入了流形学习的领域。



