


“没有标准答案的考试,该怎么评分?”
在监督学习(如猫狗分类)中,评估很简单:你猜对了多少个?Accuracy = 95%。
但在无监督学习中,我们没有 Ground Truth(真实标签)。
机器把数据分成了 3 堆,你怎么知道分得对不对?也许实际上应该是 4 堆?或者那两个点不该在一起?
本章我们将介绍一套系统化的评估体系。既然没有外部答案,我们就从内部结构、稳定性、业务价值等多个维度来审视聚类结果。
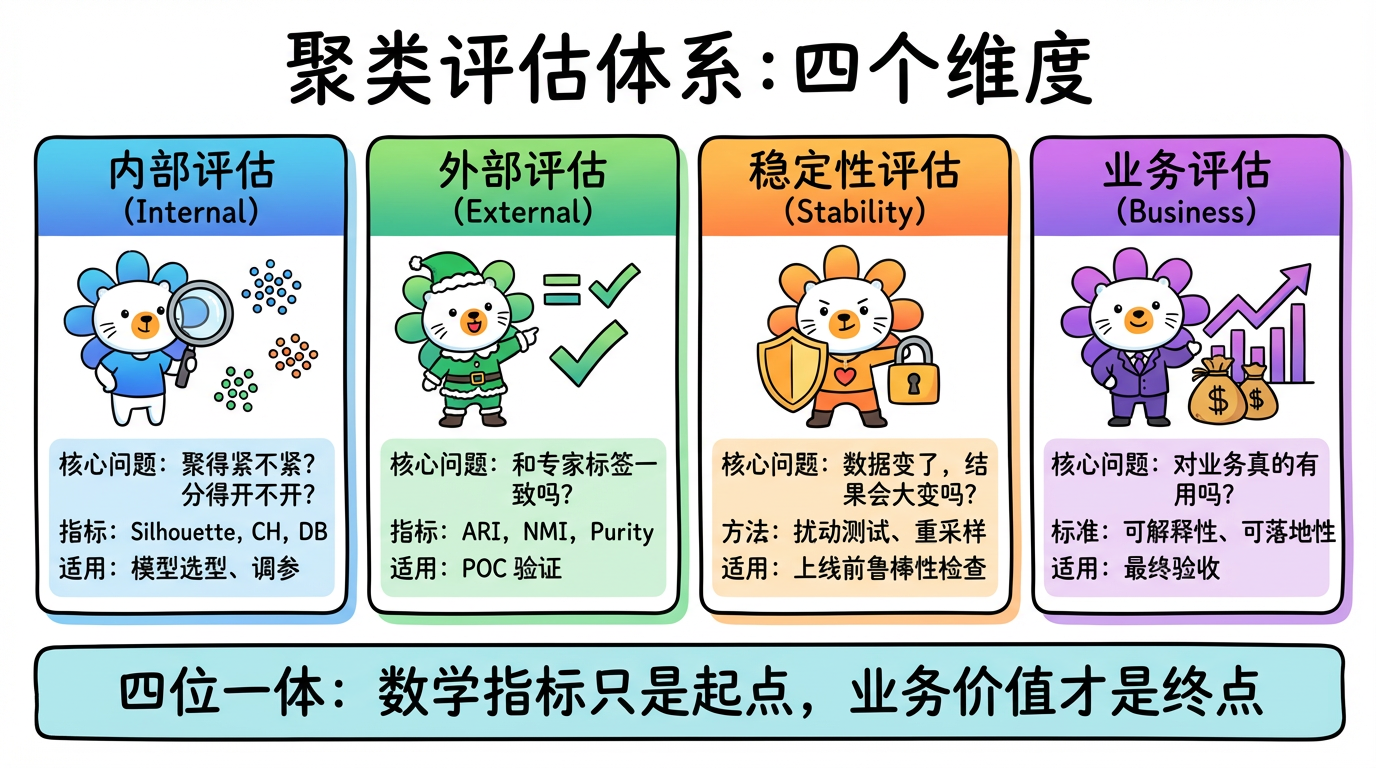
(图注:聚类评估的四个维度:内部评估、外部评估、稳定性评估、业务评估。)
1. 评估体系概览 (The Evaluation Taxonomy)
聚类评估不仅仅是算一个分数,它是一个分层的体系:
| 评估维度 | 核心问题 | 常用指标/方法 | 适用阶段 |
|---|---|---|---|
| 1. 内部评估 (Internal) | 聚得紧不紧?分得开不开? | Silhouette, CH, DB | 模型选型 (调参、选 K) |
| 2. 外部评估 (External) | 和专家标的标签一致吗? | RI, NMI, Purity | POC 验证 (有少量标注数据时) |
| 3. 稳定性评估 (Stability) | 数据变一点,结果会不会大变? | 扰动测试, 重采样 | 模型上线前 (鲁棒性检查) |
| 4. 业务评估 (Business) | 对业务真的有用吗? | 可解释性, Actionability | 最终验收 |
2. 内部评估:没有答案怎么打分?
这是最常用的评估方式。我们的普世审美标准是:“物以类聚 (Cohesion),人以群分 (Separation)”。
2.1 轮廓系数 (Silhouette Coefficient) —— 精细的个体体检
它不是给班级打分,而是给每个学生打分。它能画出一张“轮廓图”,让你一眼看出哪个班级很松散。
计算逻辑:
对于点 $i$:- $a(i)$:内卷程度。我离同班同学平均有多近?(越小越好)
- $b(i)$:排外程度。我离隔壁班同学平均有多远?(越大越好)
- $$ s(i) = \frac{b(i) - a(i)}{\max(a(i), b(i))} $$
深度解读:
- 接近 +1:完美。我稳稳地坐在班级中心。
- 接近 0:骑墙派。我站在两个班级的走廊上,分给谁都行。
- 接近 -1:身在曹营心在汉。我离隔壁班比离自己班还近,肯定是分错了。
局限性:轮廓系数假设簇是凸形(球形)的。如果你的数据是“月牙形”的(DBSCAN 擅长的那种),轮廓系数会很低,但这不代表聚类是错的。
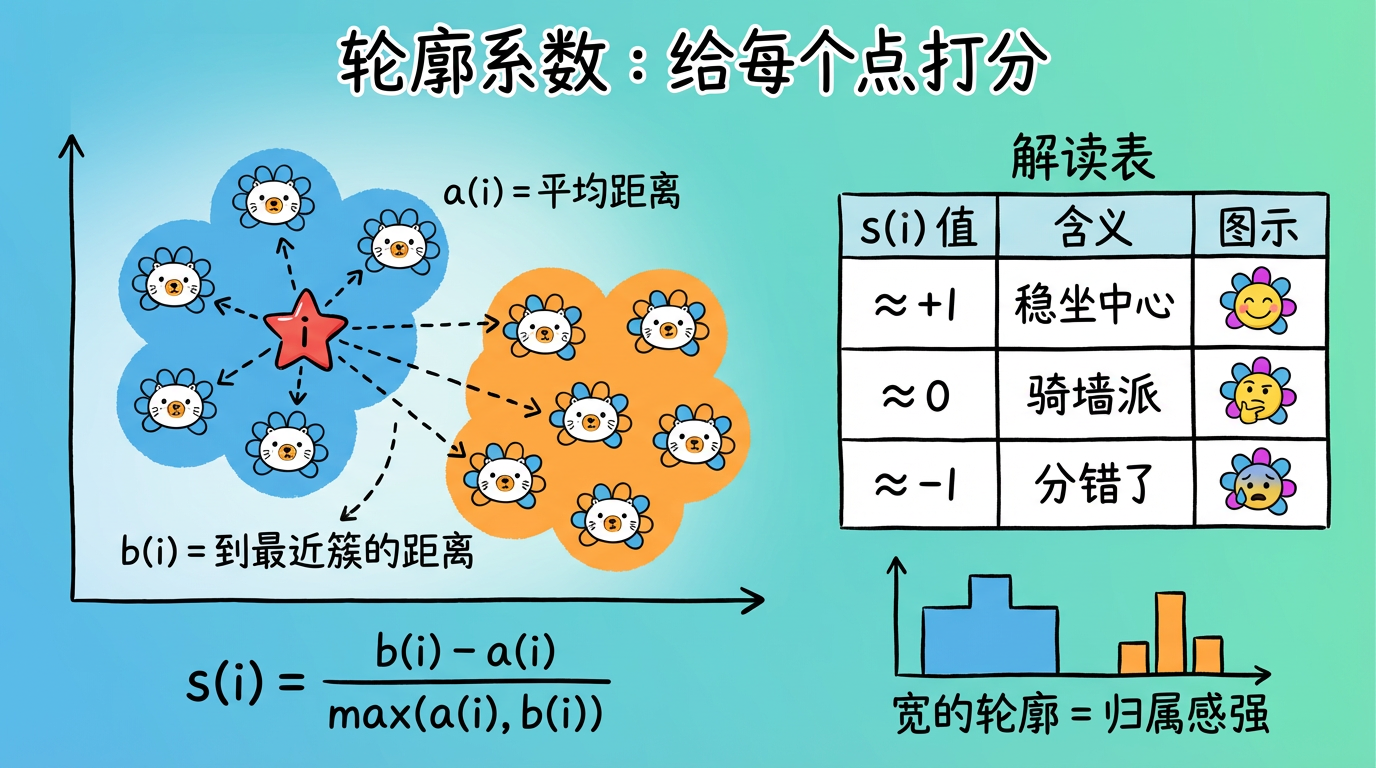
(图注:a(i) 是点到同簇的平均距离,b(i) 是到最近邻簇的距离。s(i) 接近 1 表示归属感强。)
2.2 Calinski-Harabasz (CH) Index —— 统计学的严谨
也叫方差比准则。它的核心思想源自 ANOVA(方差分析)。
$$ CH = \frac{\text{簇间方差 (Separation)}}{\text{簇内方差 (Cohesion)}} \times \frac{N-K}{K-1} $$
- 核心思想:我们希望簇间方差大(不同簇差异明显),簇内方差小(簇内非常团结)。
- 优点:计算只涉及矩阵运算,速度极快。在千万级数据上,它是唯一跑得动的指标。
2.3 Davies-Bouldin (DB) Index —— 寻找最差短板
它是一种悲观的指标。它不看平均情况,而是去挑刺:对于每一个簇,它都去寻找和它最像(最难区分)的那个簇,计算它们的相似度。
- 判定:DB 指数是所有“最大相似度”的平均值。数值越小越好(0 代表完美分离)。
3. 外部评估:如果有“上帝视角”
在项目初期(POC 阶段),我们通常会人工标注一小部分数据(比如 500 条),作为 Ground Truth。这时我们可以用外部指标来验证算法。
3.1 Rand Index (RI) & ARI
- Rand Index (RI):简单的准确率。
- 机器判定“在一起”且人工也判定“在一起”的对子数 + 机器判定“分开”且人工也判定“分开”的对子数 / 总对子数。
- Adjusted Rand Index (ARI):推荐使用。
- RI 有个问题:即使随机乱猜,RI 也不会是 0(因为总能蒙对一些)。
- ARI 对随机猜测进行了校正。ARI = 0 表示随机乱猜,ARI = 1 表示完美匹配。
3.2 归一化互信息 (NMI)
- 源自信息论。它衡量的是:“知道了聚类结果,能给推断真实标签带来多少信息量?”
- 特点:NMI 对簇的数量不敏感,适合对比 K 值不同的聚类结果。
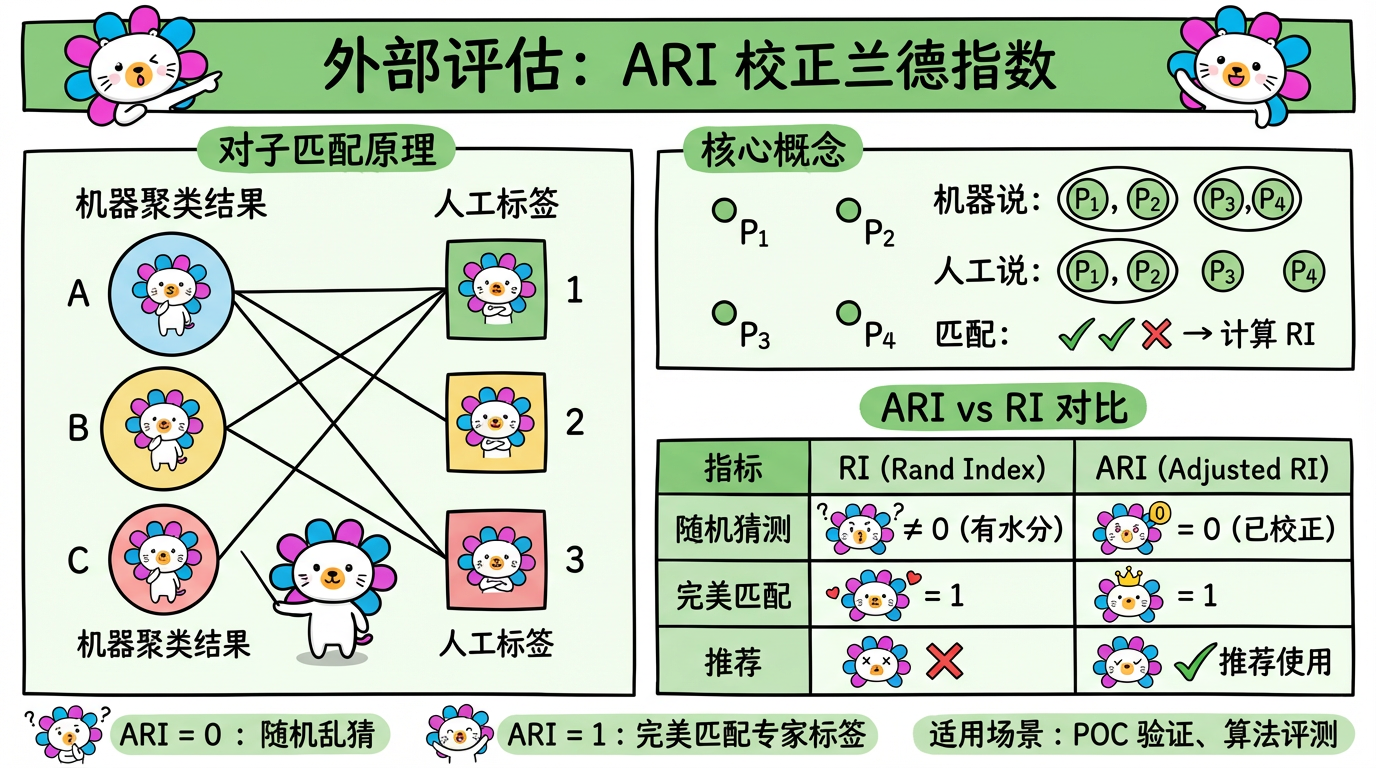
(图注:ARI 校正了随机猜测的影响。ARI=0 表示随机,ARI=1 表示完美匹配。)
4. 稳定性评估:经得起考验吗?
这是新手最容易忽略的一环。一个好的聚类模型,应该是稳健的。
测试方法(扰动测试):
- 随机采样:从原数据中随机抽取 90% 的数据。
- 重新聚类:用同样的参数跑一遍 K-Means。
- 对比结果:对比这两次聚类的中心点位置、簇的成员构成。
- 如果不稳定:仅仅少了一点数据,聚类结果就面目全非(比如簇 A 突然分裂成了两个,或者簇 B 消失了)。说明目前的聚类结构是偶然的,不可靠。
- 如果稳定:说明我们要找的结构是真实存在于数据分布中的。
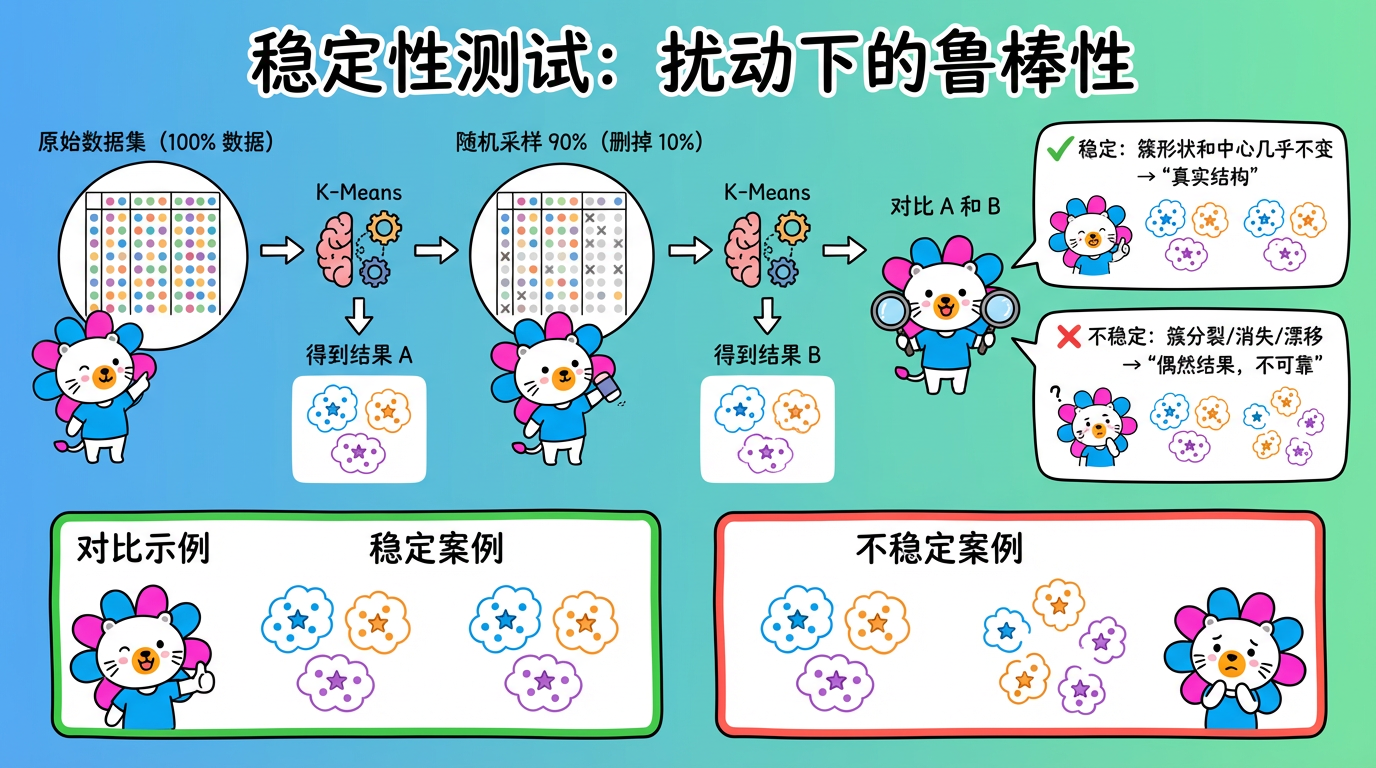
(图注:扰动测试流程:采样 90% 数据重新聚类,对比结果是否稳定。)
5. K 值的选择艺术
5.1 肘部法则 (Elbow Method)
我们画出 $K$ 与 Inertia (簇内误差平方和 SSE) 的关系图。
我们要找的是性价比最高的点(收益递减点)。就像人的手肘:在此之前,增加 K 能大幅降低误差;在手肘之后,增加 K 只是微小的优化,不划算。
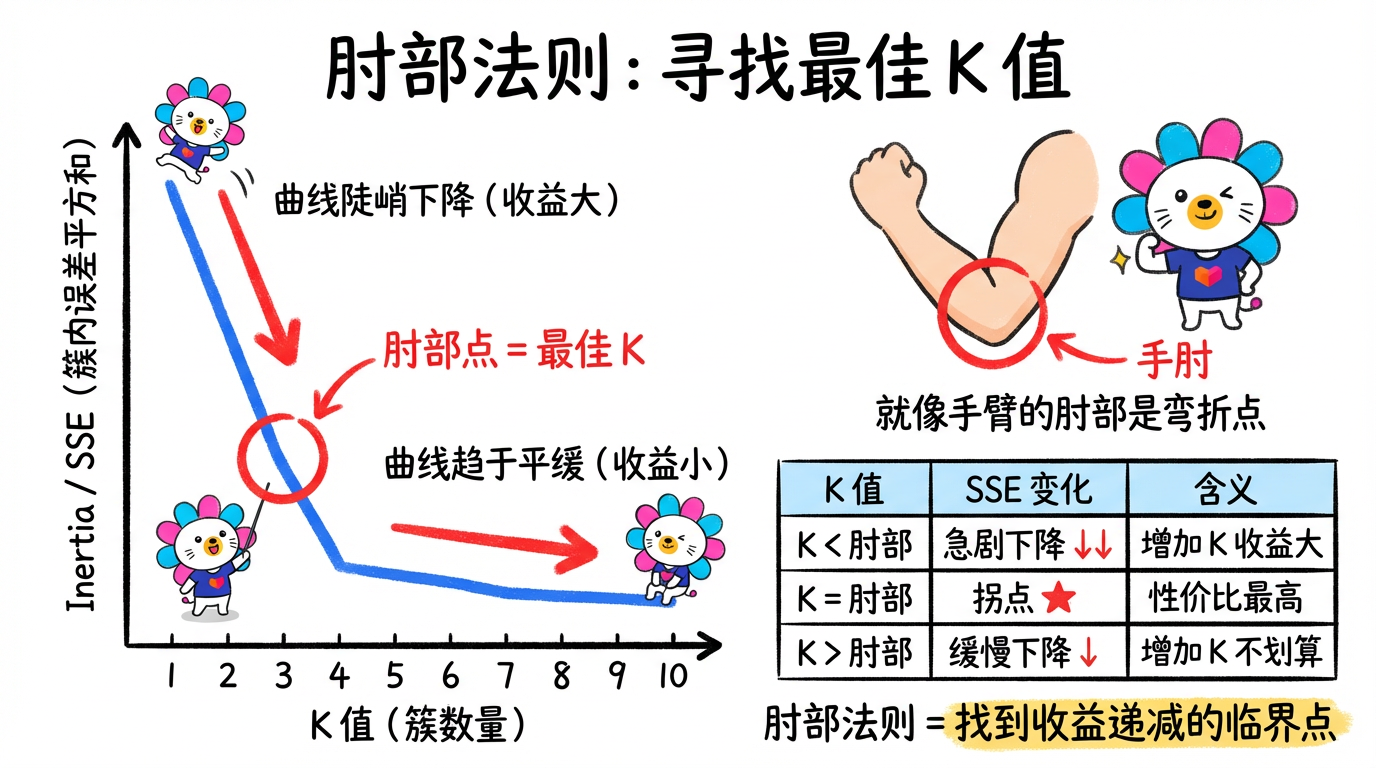
(图注:在 K=3 处出现明显的拐点。此处即为最佳 K 值。)
5.2 为什么不能完全听指标的?
这是新手的最大误区。
在实际项目中,如果用肘部法则,可能算出来最佳 K=5 或 K=8。
但我们在第 2 章提到,我们最终强行设了 K=80。这是否违反了科学精神?
没有。因为业务需求 > 数学指标。
- 数学视角:把所有“投诉”归为一类 (K=1),非常紧凑,轮廓系数可能最高。
- 业务视角:这毫无意义。我要区分“丢件”、“破损”、“慢”。即使它们在语义空间上很像(导致数学上很难分开,轮廓系数降低),我也必须把它们拆开。
结论:无监督学习的评估指标仅供参考。最终的评判标准是 可解释性 (Interpretability) 和 可落地性 (Actionability)。如果 K=80 能帮运营人员发现新问题,那它就是最好的 K。
6. 代码实战:全家桶评估
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
from sklearn import datasets
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score, adjusted_rand_score
import matplotlib.pyplot as plt
import numpy as np
# 1. 生成模拟数据 (带真实标签 y_true,用于演示外部评估)
X, y_true = datasets.make_blobs(n_samples=1000, centers=4, random_state=42)
# 2. 跑 K-Means
kmeans = KMeans(n_clusters=4, random_state=42).fit(X)
labels = kmeans.labels_
# ==========================================
# Part A: 内部评估 (假设没有标签)
# ==========================================
print("--- 内部评估 (Internal) ---")
# 1. 轮廓系数 (Silhouette)
# 注意:O(N^2) 复杂度,大数据请采样 sample_size=10000
sil = silhouette_score(X, labels)
print(f"Silhouette Coefficient (接近1好): {sil:.3f}")
# 2. CH 指数 (Calinski-Harabasz)
# 计算超快,适合大数据
ch = calinski_harabasz_score(X, labels)
print(f"Calinski-Harabasz Index (越大越好): {ch:.1f}")
# 3. DB 指数 (Davies-Bouldin)
db = davies_bouldin_score(X, labels)
print(f"Davies-Bouldin Index (越小越好): {db:.3f}")
# ==========================================
# Part B: 外部评估 (假设有少量人工标注标签)
# ==========================================
print("\n--- 外部评估 (External) ---")
# 1. Adjusted Rand Index (ARI)
ari = adjusted_rand_score(y_true, labels)
print(f"Adjusted Rand Index (1为完美): {ari:.3f}")
# 如果结果是 0.95,说明机器聚出来的簇和专家标注几乎一致。
# ==========================================
# Part C: 稳定性评估 (Stability)
# ==========================================
print("\n--- 稳定性评估 (Stability) ---")
# 随机删掉 10% 的数据,再跑一次
indices = np.random.choice(X.shape[0], size=int(X.shape[0]*0.9), replace=False)
X_sub = X[indices]
kmeans_sub = KMeans(n_clusters=4, random_state=42).fit(X_sub)
# (此处通常需要更复杂的对齐算法来比较两个模型,略)
print("稳定性检查:观察中心点是否剧烈漂移...")
print(f"原中心点:\n{kmeans.cluster_centers_[0]}")
print(f"新中心点:\n{kmeans_sub.cluster_centers_[0]}")7. 总结对比表
| 指标类型 | 指标 | 目标 | 速度 | 核心价值 |
|---|---|---|---|---|
| 内部指标 | Silhouette | 接近 1 | 慢 $O(N^2)$ | 衡量个体归属感,适合小数据精细评估 |
| CH Index | 越大越好 | 快 $O(N)$ | 衡量整体方差比,适合大数据 | |
| DB Index | 越小越好 | 快 $O(N)$ | 衡量最差分离度,寻找短板 | |
| 外部指标 | ARI | 接近 1 | 快 | 金标准(如果有标签),验证算法能力 |
| NMI | 接近 1 | 快 | 信息论视角,适合不同 K 值对比 | |
| 选择方法 | 肘部法则 | 找拐点 | - | 平衡误差与复杂度,确定最佳 K |
| 终极裁判 | 业务价值 | 有用 | - | 最终标准:可解释、可落地、稳定性 |
下一章预告
至此,我们完成了聚类算法的学习。
接下来,我们将进入无监督学习的另一大支柱——降维。
我们一直在说“先降维再聚类”。
- 降维到底是怎么把 1536 个数字变成 2 个数字的?
- 为什么降维后还能保留原有的含义?
- PCA 又是如何像投影仪一样工作的?



