


“上帝不掷骰子,但数据科学家掷。” —— 改编自爱因斯坦
之前的聚类算法(K-Means, DBSCAN)都有一个共同特征:硬聚类 (Hard Clustering)。
一个样本要么属于 A,要么属于 B,没有中间地带。
这就像把人简单分为“好人”和“坏人”,丢失了人性的复杂灰度。
在实际的文本分析场景中,我们经常遇到这种情况:
用户工单:”快递员态度太差了,而且还不给我送上楼,我要退款!”
这句话既涉及【物流服务】,又涉及【退款流程】。如果硬把它归为某一类,就会丢失另一半信息。
本章我们将介绍 高斯混合模型 (GMM, Gaussian Mixture Model),它引入了 软聚类 (Soft Clustering) 的概念,告诉我们:这个样本 70% 是物流问题,30% 是退款问题。
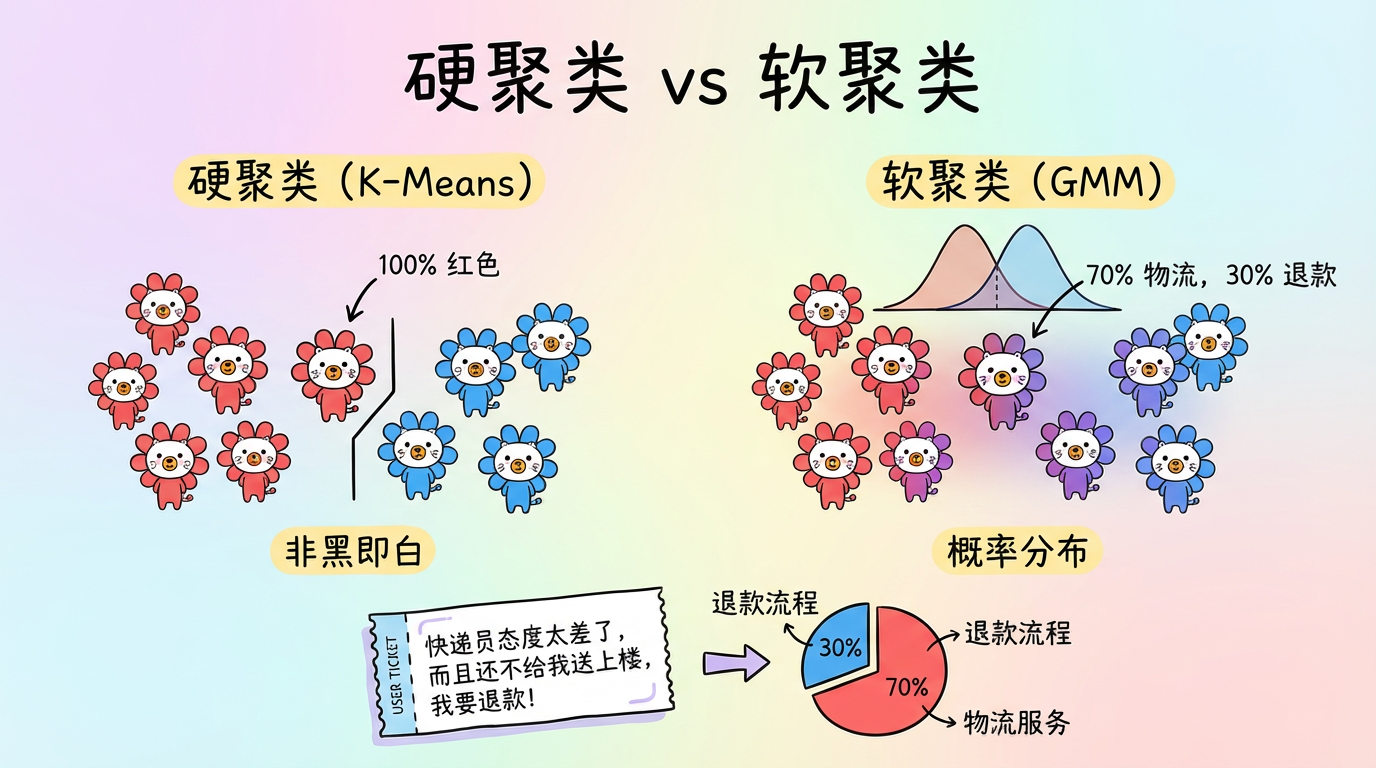
(图注:软聚类允许一个点同时属于多个簇。颜色混合的区域表示不确定性高的“骑墙派”。)
1. 核心概念:世界是由“钟形曲线”组成的
1.1 什么是 GMM?
GMM 的核心假设非常简单:数据不是一堆无规律的石头,而是一堆叠加在一起的波。
具体来说,所有数据都是由 $K$ 个高斯分布(Gaussian Distribution,也就是正态分布/钟形曲线)混合而成的。
想象你在操场上看到一堆人。
- 有一群打篮球的男生,平均身高 180cm(波峰),但也有些矮个和高个(波宽)。
- 有一群跳健美操的女生,平均身高 165cm。
- 如果你只看身高数据,你会看到两个叠加在一起的“钟形曲线”。
GMM 的任务就是把这两个混在一起的钟形曲线拆解出来。
1.2 三个关键参数:给簇“塑形”
为了描述一个高斯分布(一个簇),我们需要三个参数。我们可以把这想象成捏泥人:
- $\mu$ (均值 Mean):位置。决定了钟形曲线的最高点(簇中心)在哪里。
- $\Sigma$ (协方差 Covariance):形状。
- 决定了钟形曲线是胖是瘦,是圆是扁。
- 这是 GMM 相比 K-Means 的最大优势。K-Means 只能找正圆形的簇,而 GMM 通过协方差矩阵,可以拟合细长的椭圆形。
- $\pi$ (权重 Weight):高度。决定了这个簇里有多少人。
$$ P(x) = \sum_{k=1}^K \pi_k \mathcal{N}(x | \mu_k, \Sigma_k) $$
(公式含义:任意一个点出现的概率,等于它属于第1个簇的概率 + 属于第2个簇的概率 + …)
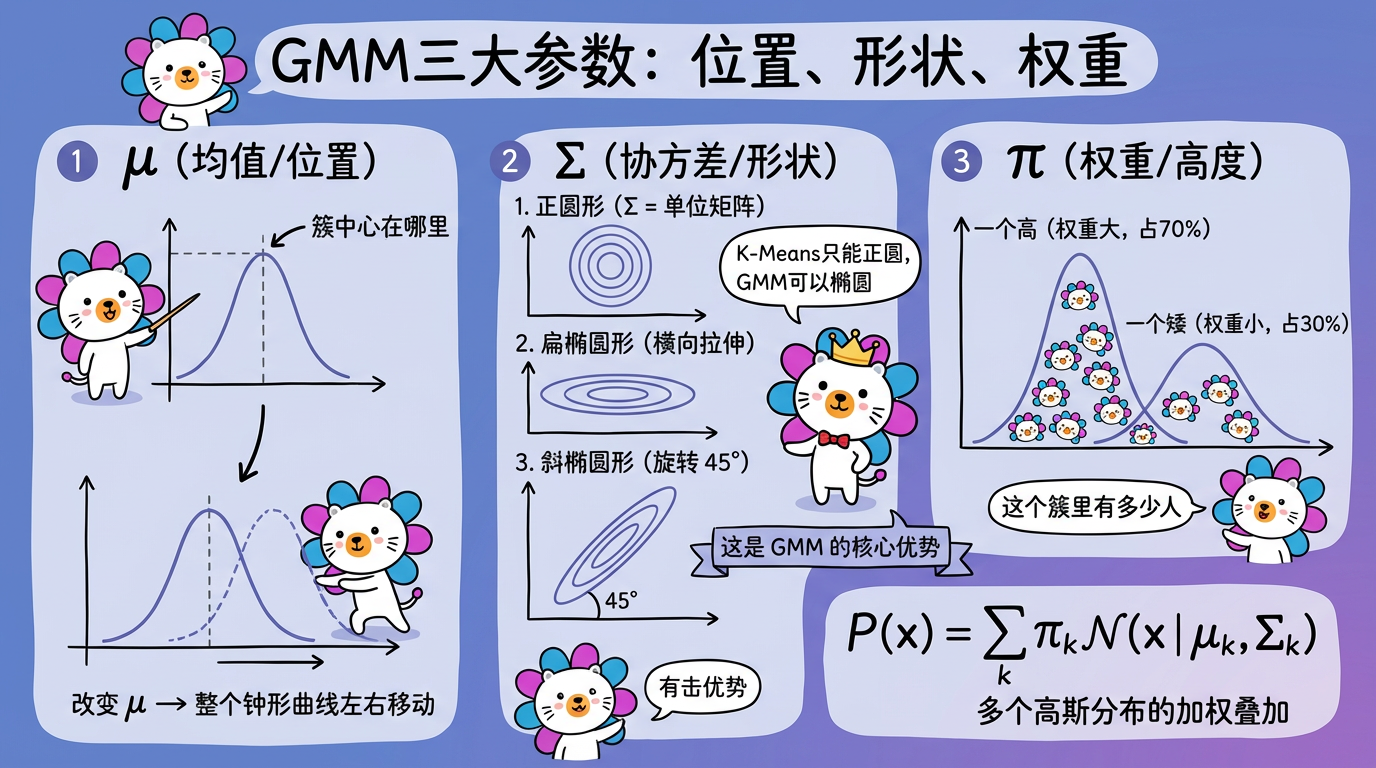
(图注:μ 决定簇的位置,Σ 决定簇的形状(圆形/椭圆),π 决定簇的权重大小。)
2. 怎么解?EM 算法的“食堂打饭”隐喻
我们要解出这三个参数,但是有个“鸡生蛋,蛋生鸡”的难题:
- 蛋 (标签):如果我们知道每个人属于哪一队(篮球/健美操),我们就能算出每一队的平均身高 ($\mu$) 和身形标准差 ($\Sigma$)。
- 鸡 (参数):如果我们知道每一队的平均身高和身形标准差,我们就能算出某个人属于哪一队的概率。
- 死锁:现在我们既不知道标签,也不知道参数。
于是我们有了 EM 算法 (Expectation-Maximization)。这就好比食堂排队打饭:
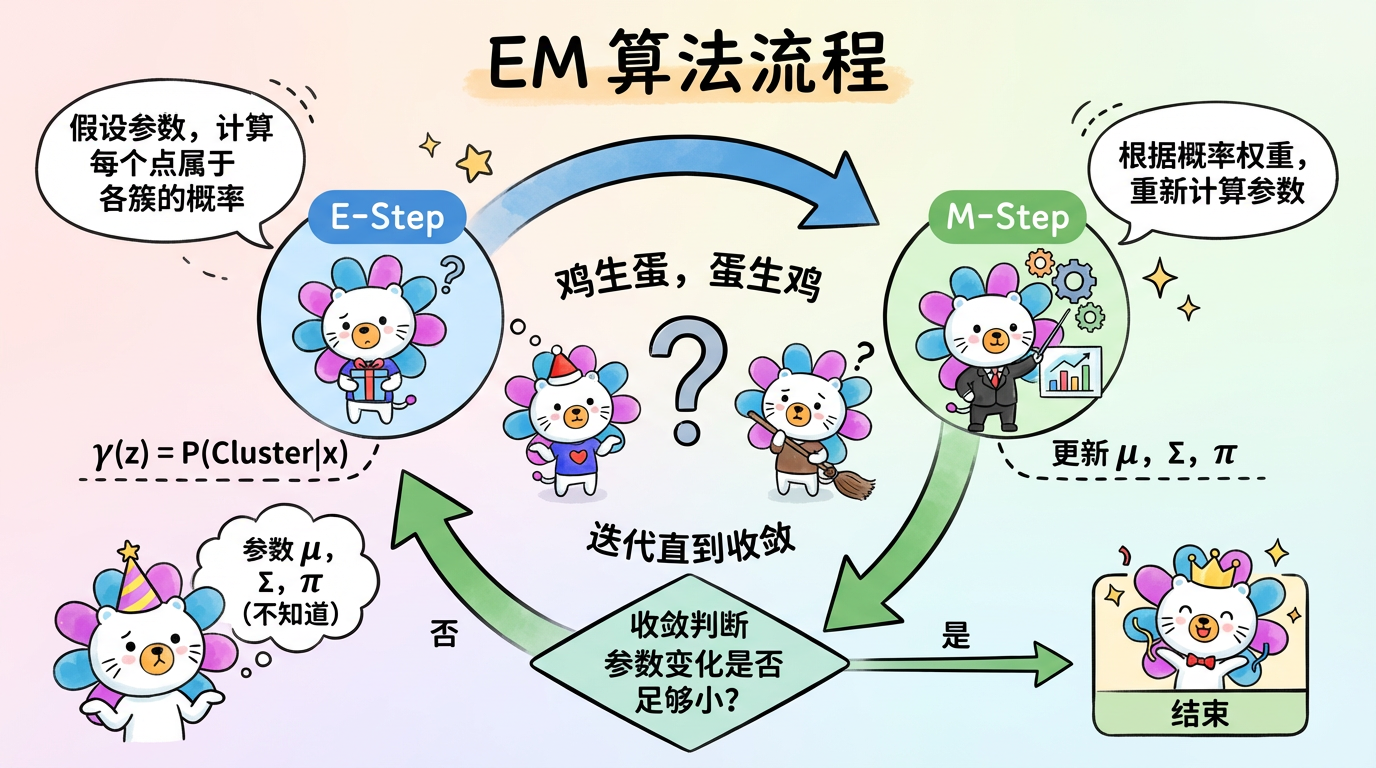
(图注:EM 算法是一个迭代优化的过程。E步计算归属概率,M步更新分布参数,以此往复直到收敛。)
- 初始化 (瞎猜):随便先画两个圈,假装这是两个队。
- E-Step (期望步 / 站队):
- 根据目前的圈(参数),每个人计算自己属于每个圈的概率。
- “我身高 175,看起来有 60% 的可能属于篮球队,40% 的可能属于健美操队。”(注意:这里不是非黑即白,而是按比例站队)。
- M-Step (最大化步 / 调整圈):
- 根据大家站队的结果(加权),重新计算每个圈的中心和形状。
- “既然这 0.6 个人属于篮球队,那篮球队的平均身高得往他这边挪一点点。”
- Loop (循环):重复 2 和 3,直到大家都不再换队,圈也不再移动(收敛)。
3. 技术对比:K-Means vs GMM
| 特性 | K-Means | GMM (高斯混合模型) |
|---|---|---|
| 聚类性质 | 硬聚类 (0 或 1) | 软聚类 (概率分布,如 [0.8, 0.2]) |
| 簇形状 | 只能是正圆 (球体) | 可以是任意方向的椭圆 |
| 参数量 | 少 (只有中心) | 多 (中心 + 协方差矩阵) |
| 计算速度 | 快 (线性复杂度) | 较慢 (涉及矩阵求逆,迭代次数多) |
| 适用场景 | 大规模数据,简单的硬划分 | 需要概率输出,簇有重叠,形状扁长 |
| 本质关系 | K-Means 是 GMM 的特例 | 当 GMM 的方差极小且相等时,就变成了 K-Means |
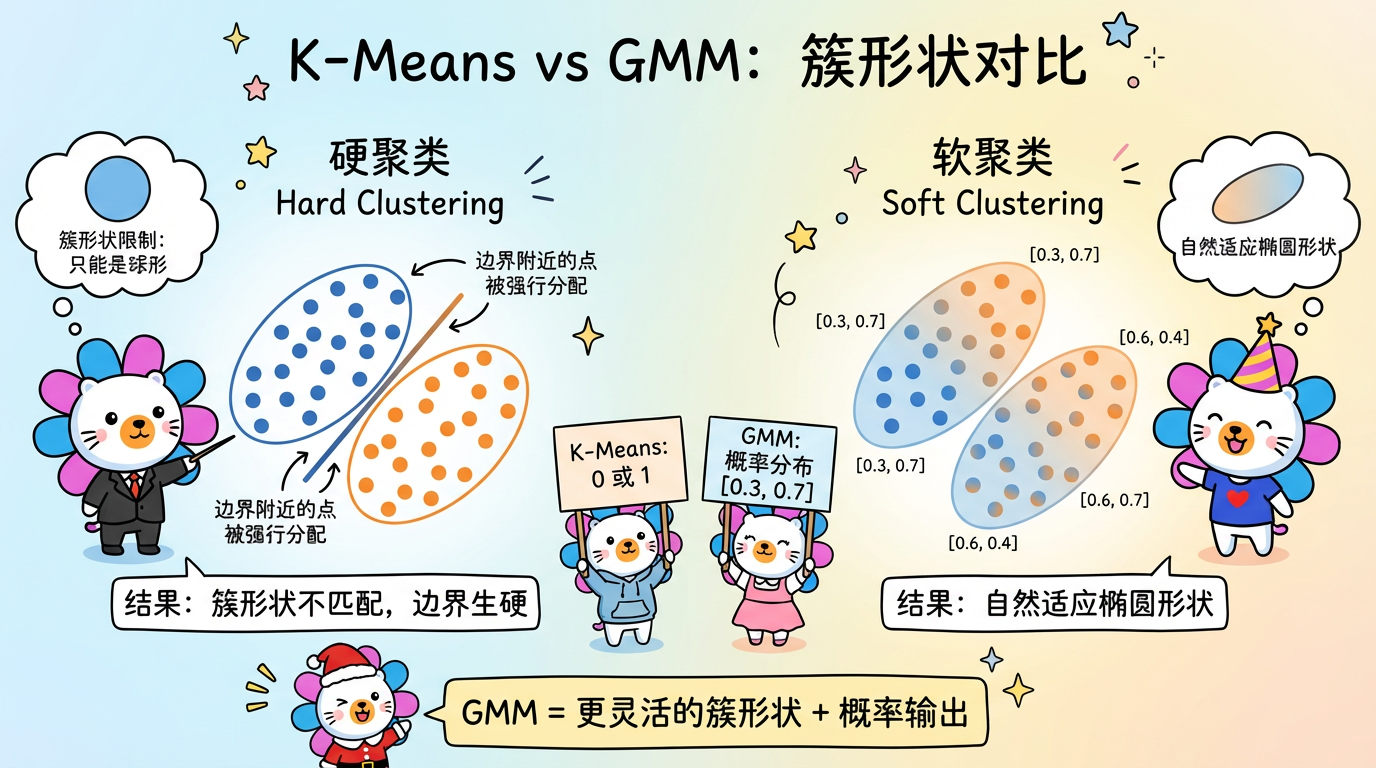
(图注:左图 K-Means 强行把扁长的簇切成了两半;右图 GMM 完美拟合了椭圆形的分布。)
4. 实际应用场景:模糊地带的价值
虽然在通用聚类任务上 K-Means 是老大,但在以下场景中,GMM 的“骑墙派”特性具有极大的商业价值。
场景 A:用户画像中的“多重身份”
有些用户是复杂的。
- K-Means:把用户 A 强行归为“价格敏感型”。
- GMM:告诉我们用户 A
[0.6 价格敏感, 0.4 品质追求]。 - 决策:对于这种用户,我们不仅要推优惠券(满足 0.6),还要推一些高性价比的品牌货(满足 0.4),而不是只推 9.9 包邮的垃圾。
场景 B:异常检测与风控
GMM 可以输出每个样本的似然度 (Likelihood),也就是“这个样本属于当前这个世界的概率”。
- 如果一个样本算出来的概率极低(比如 $10^{-5}$),说明它不属于任何一个现有的正常簇。
- 结论:这大概率是一笔欺诈交易或者一个异常工单。
场景 C:不确定性筛选
- 策略:筛选出那些最大概率小于 0.6 的样本(即
max(probs) < 0.6)。 - 含义:这些样本是模型“拿不准”的。它们往往是脏数据,或者是蕴含了新趋势的边缘案例,值得在这个子集上投入人工复核。
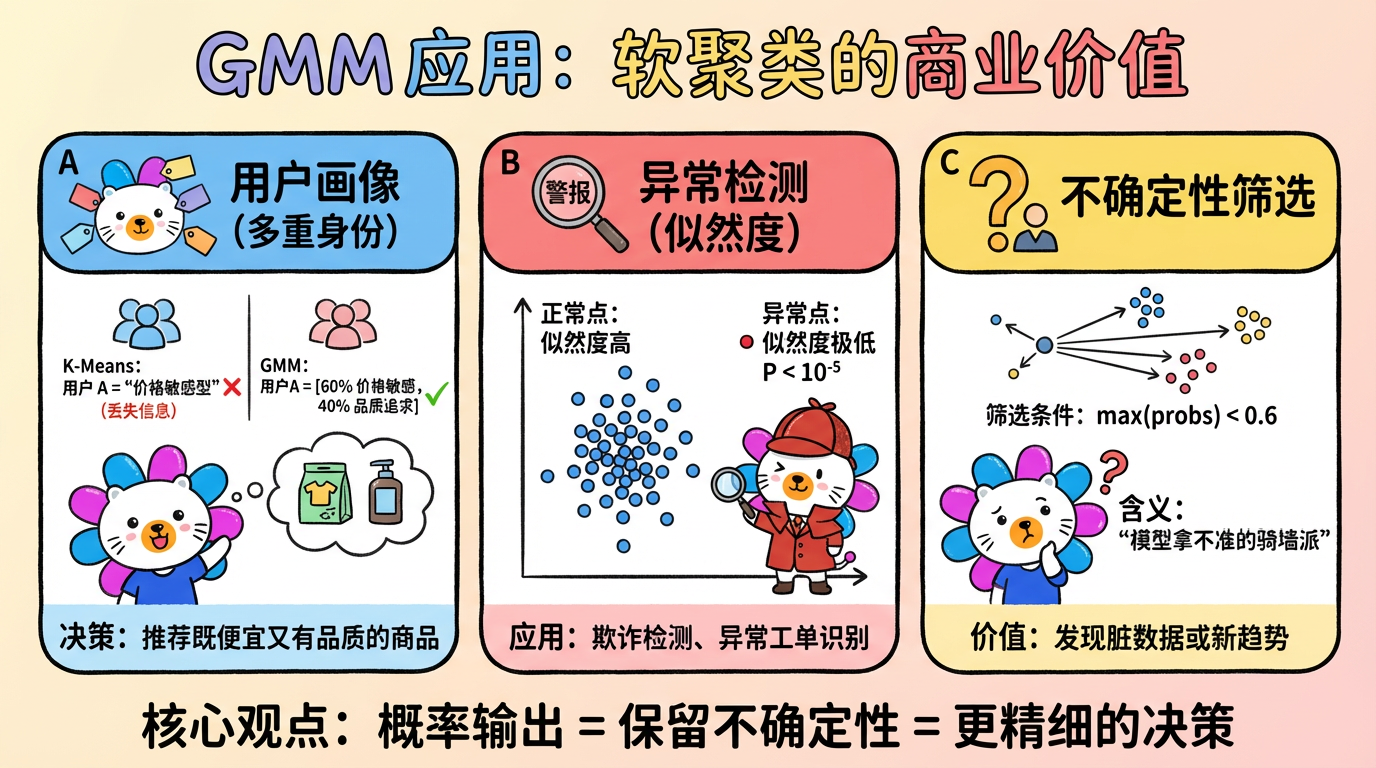
(图注:软聚类的概率输出在用户画像、异常检测、不确定性筛选中具有独特价值。)
5. 模型选择:奥卡姆剃刀
GMM 也面临和 K-Means 一样的问题:K (n_components) 选多少?
K 越大,模型肯定拟合得越好(误差越小),但这可能只是死记硬背(过拟合)。我们需要一个裁判,在“拟合得好”和“模型简单”之间找平衡。这叫奥卡姆剃刀原理:如无必要,勿增实体。
我们引入两个信息准则作为裁判:AIC 和 BIC。
5.1 核心公式拆解
它们的公式长得很像,都由两部分组成:
$$ \text{Score} = \underbrace{-2\ln(\hat{L})}{\text{坏处:拟合误差}} + \underbrace{\alpha \cdot k}{\text{惩罚:模型复杂度}} $$
- 第一项(拟合误差):$\hat{L}$ 是似然度,代表模型对数据的解释能力。拟合得越好,$\hat{L}$ 越大,$-2\ln(\hat{L})$ 就越小。我们希望这项越小越好。
- 第二项(复杂度惩罚):$k$ 是参数个数(模型越复杂,$k$ 越大)。我们希望这项也越小越好。
所以,我们的目标是找一个 K 值,使得 AIC 或 BIC 最小。
5.2 AIC vs BIC:选哪个裁判?
| 准则 | 全称 | 惩罚力度 | 倾向性 | 隐喻 |
|---|---|---|---|---|
| AIC | 赤池信息量准则 | 宽松 ($\alpha=2$) | 允许模型稍微复杂一点,只要预测得准。 | “实用主义者”:只要衣服穿着好看,贵点也没关系。 |
| BIC | 贝叶斯信息量准则 | 严厉 ($\alpha=\ln(n)$) | 随着样本量 $n$ 增加,惩罚极重。倾向于更简单的模型。 | “极简主义者”:衣服必须性价比极高,稍微贵一点都不要。 |
👑 推荐:在聚类任务中,我们通常希望找到数据的“真实结构”,而不只是为了预测。而且聚类很容易过拟合。因此,BIC 是更好的选择。它能帮你砍掉那些不必要的簇,给你一个最精简的分类。
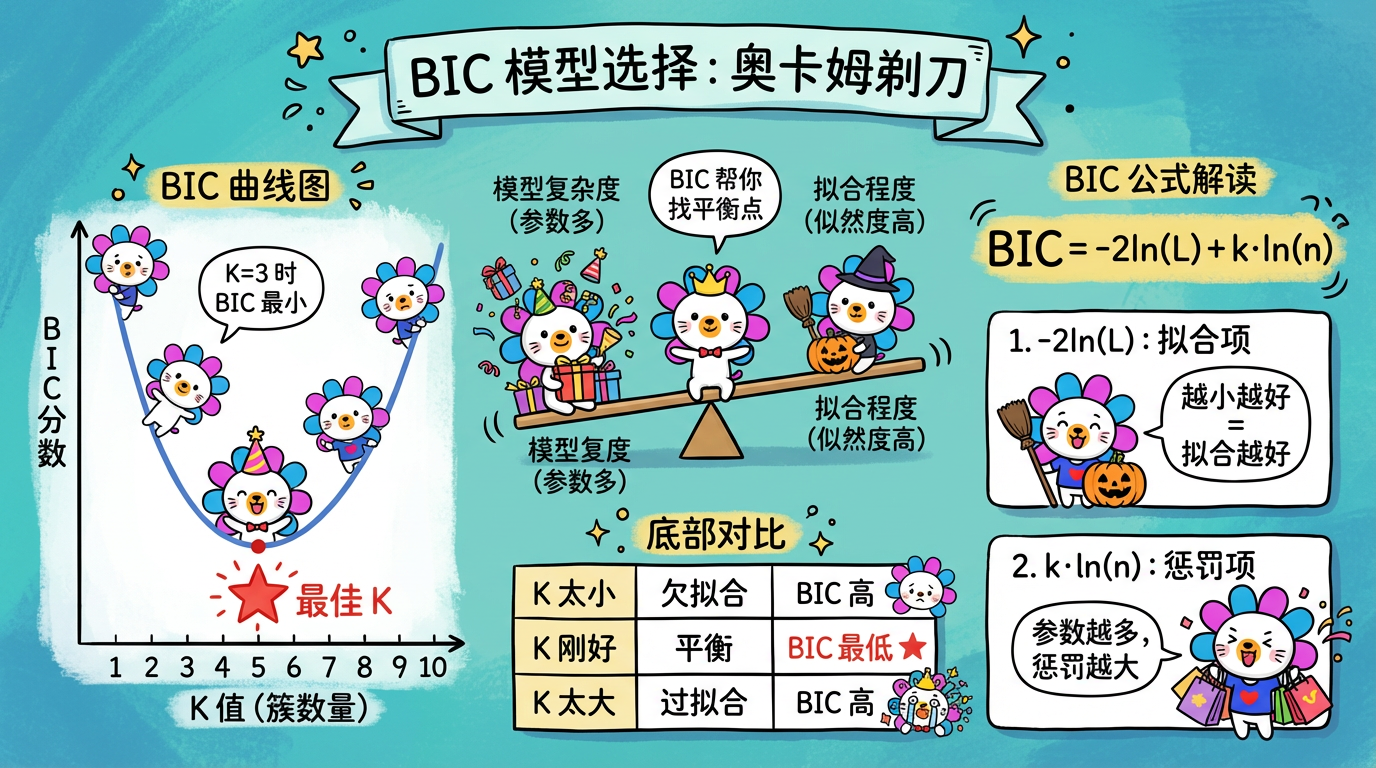
(图注:BIC 曲线在最佳 K 处达到最低点,平衡了拟合程度和模型复杂度。)
6. 代码实战:Scikit-Learn 实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
from sklearn.mixture import GaussianMixture
from sklearn.datasets import make_blobs
import numpy as np
# 1. 准备数据
X, _ = make_blobs(n_samples=500, centers=3, cluster_std=1.5)
# 2. 训练 GMM
# n_components: 簇的数量 (K)
# covariance_type='full': 允许任意形状的椭圆 (最灵活但参数最多)
gmm = GaussianMixture(n_components=3, covariance_type='full', random_state=42)
gmm.fit(X)
# 3. 结果分析
# A. 硬聚类结果 (和 K-Means 类似,返回 0, 1, 2)
labels = gmm.predict(X)
# B. 软聚类概率 (GMM 的灵魂)
# 返回 shape (N, 3),每一行加起来等于 1
probs = gmm.predict_proba(X)
# 看看第一个点的情况
print(f"样本 0 的归属概率: {probs[0]}")
# 可能输出: [0.05, 0.90, 0.05] -> 很有把握是簇 1
# 可能输出: [0.40, 0.50, 0.10] -> 骑墙派,位于簇 0 和 1 的交界处
# 4. 模型选择 (AIC/BIC)
n_components_range = range(1, 10)
bics = []
for n in n_components_range:
gmm_test = GaussianMixture(n_components=n, random_state=42).fit(X)
bics.append(gmm_test.bic(X))
# 找 BIC 最小的那个 K
best_k = n_components_range[np.argmin(bics)]
print(f"BIC 建议的最佳簇数: {best_k}")7. 实践要点
- 预热 (Warm Start):EM 算法很容易陷入局部最优。聪明的做法是先跑一遍 K-Means,用 K-Means 找到的中心点作为 GMM 的初始均值 ($\mu$)。
sklearn默认就是这么做的 (init_params='kmeans')。 - 维度灾难预警:
- GMM 的参数量随着维度平方级增长(因为要算 $D \times D$ 的协方差矩阵)。
- 禁忌:千万不要在 768 维的 BERT 向量上直接跑
covariance_type='full'的 GMM。矩阵会不可逆,模型会过拟合。 - 对策:必须先降维(如 PCA 到 50 维以内),或者强制把协方差矩阵设为
diag(只算对角线,假设特征独立)或spherical(球形,退化为类似 K-Means)。
下一章预告
我们讲了 K-Means, DBSCAN, 层次聚类, GMM…
每种算法跑出来的结果都不一样。
- K-Means 说分 5 类好。
- DBSCAN 说分 3 类好,还有一堆噪声。
- GMM 说分 4 类 BIC 最小。
到底哪个结果是好的?没有标准答案(真实标签)的情况下,我们如何给无监督学习打分?
这需要引入一套全新的评估体系。



