


“生命之树不是平铺直叙的,而是分叉生长的。”
K-Means 给了我们一张扁平的地图:这一块是中国,那一块是美国。在地图上,北京和上海是平级的城市。
但生物学家看世界的眼光不一样。他们会给你画一棵树:
- 所有动物 -> 脊索动物 -> 哺乳动物 -> 食肉目 -> 猫科 -> 家猫。
这种层层嵌套的结构,往往比扁平的分组包含了更丰富的信息。比如,我们不仅想知道“这个客户属于高价值客户”,我们可能还想知道“在高价值客户里,他又属于偏爱理财的那一小撮”。
本章我们将介绍 层次聚类 (Hierarchical Clustering)。它不需要你痛苦地纠结 K 到底是 5 还是 6。它会直接送给你一整棵家谱树(学术名叫 树状图 Dendrogram)。你想把世界分成几份,完全取决于你拿着剪刀在树的哪一层剪一刀。
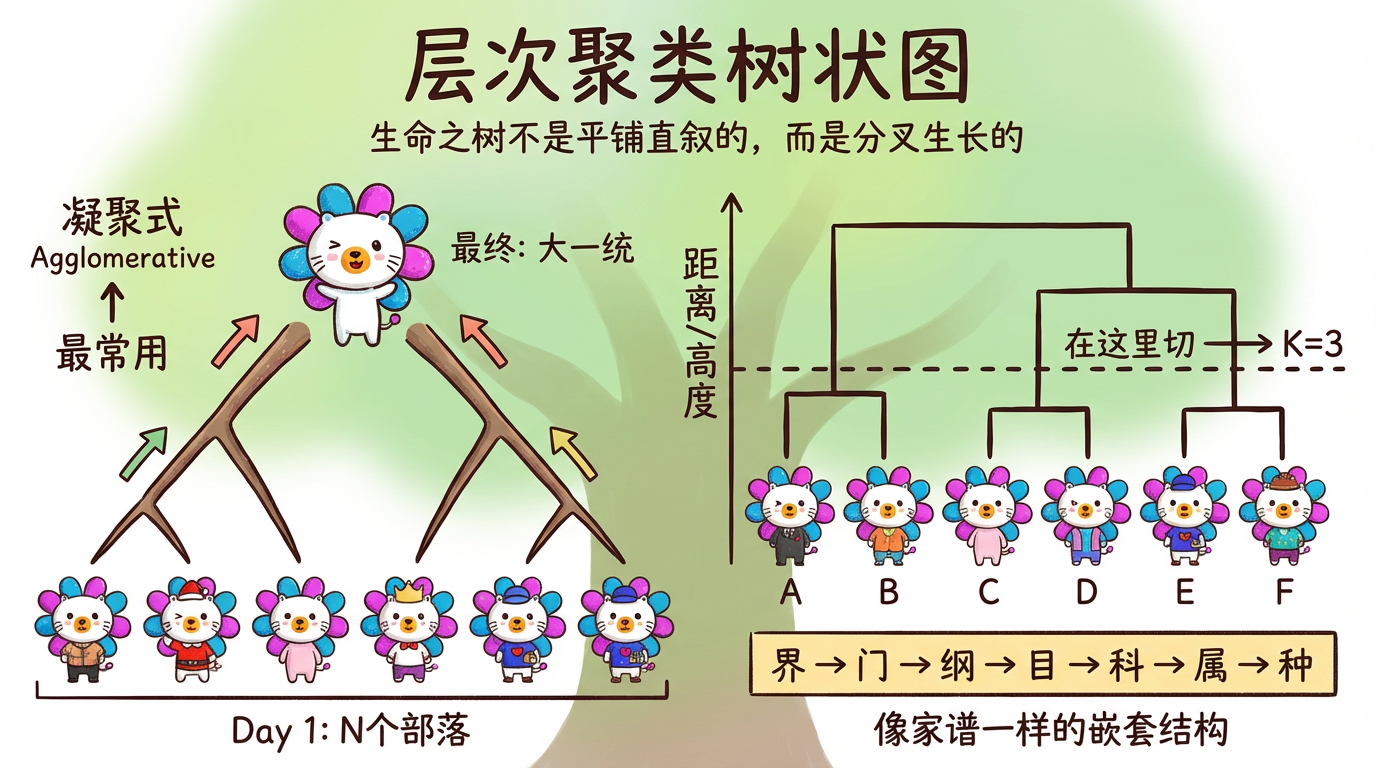
(图注:这是一棵倒置的树。最下面是独立的个体,随着高度上升,它们逐渐合并,最后汇聚成一个根节点。)
1. 两种策略:分久必合,合久必分
建立这棵树,只有两种截然相反的思路。
| 策略 | 学术名称 | 方向 | 过程隐喻 | 工业界地位 |
|---|---|---|---|---|
| 凝聚式 | Agglomerative | 自底向上 (Bottom-Up) | 部落合并:从 N 个小部落开始,两两合并,直到统一成一个大帝国。 | 主流 (默认指的就是它) |
| 分裂式 | Divisive | 自顶向下 (Top-Down) | 帝国分裂:从一个大帝国开始,不断分裂内战,直到每个人都独立建国。 | 罕见 (计算量太大) |
凝聚式过程详解:
- Day 1 (初始状态):世界上有 N 个人。每个人都是一个独立的簇 (Cluster)。
- Day 2 (合并):计算所有簇之间的距离矩阵。上帝看了一眼,发现张三和李四离得最近。于是把他们俩绑在一起,组成了一个新的簇。现在的簇数量是 N-1。
- Day 3 (继续合并):上帝又看了一眼,发现那个 2 人小簇和王五离得挺近……
- Day N (终局):重复这个过程,直到全世界所有人都合并成了一个大一统的帝国(根节点)。
在这个过程中,我们记录下每一次合并发生的“时间”(也就是距离)。这就在历史上画出了一棵树。
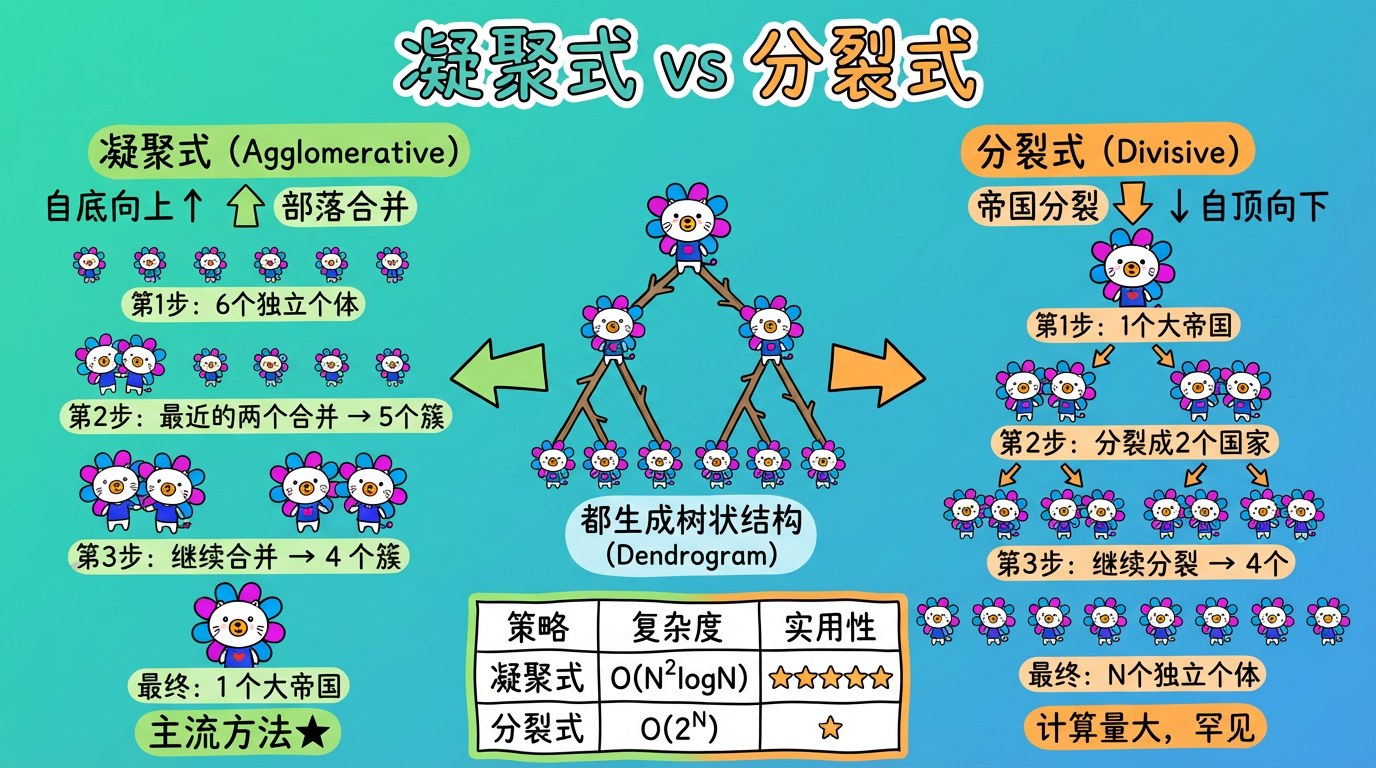
(图注:凝聚式从个体出发逐步合并(主流),分裂式从整体出发逐步拆分(罕见)。)
2. 关键抉择:链接准则 (Linkage Criteria)
在“自底向上”的合并过程中,最核心的问题来了:
我们知道两个“人”之间的距离怎么算(比如欧氏距离 Euclidean Distance),但两个“部落”(簇)之间的距离怎么算?
簇 A 有两个人 ${a_1, a_2}$,簇 B 有两个人 ${b_1, b_2}$。它们到底有多远?这取决于你的链接准则。不同的准则会决定树的形状。
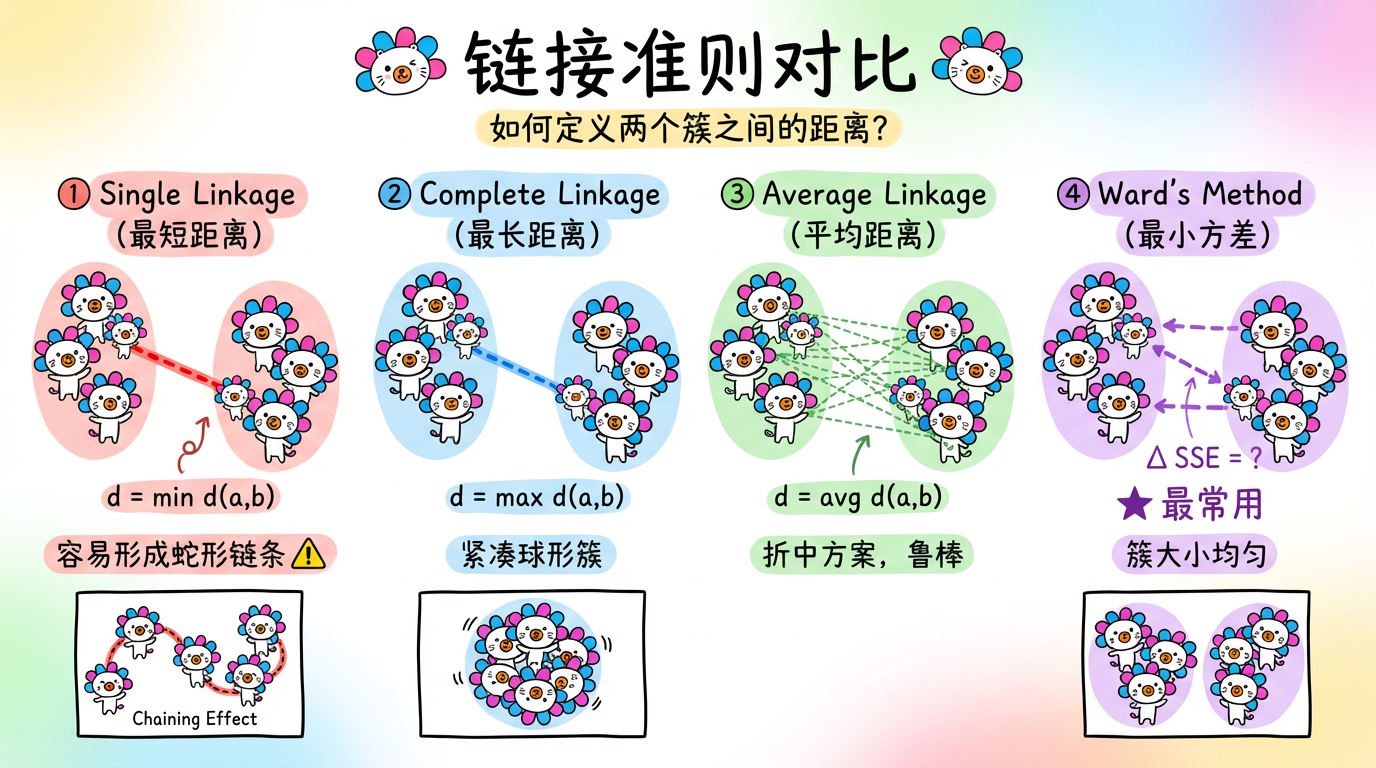
(图注:展示了三种不同的测量方式。Single Linkage 像是在握手,Complete Linkage 像是在对峙,Average Linkage 则是重心的距离。)
| 链接准则 (Linkage) | 规则隐喻 | 公式逻辑 | 优点 | 缺点 |
|---|---|---|---|---|
| Single (最短距离) | “握手”:只要有一个朋友,我们就是一家人。 | $\min dist(a, b)$ | 能处理非球形簇 | 容易产生连锁效应 (Chaining),像贪吃蛇一样连成一长串 |
| Complete (最长距离) | “对峙”:必须所有人都同意,我们才能合并。 | $\max dist(a, b)$ | 生成紧凑的球形簇 | 对异常值极度敏感 |
| Average (平均距离) | “重心”:大家的平均关系怎么样。 | $avg dist(a, b)$ | 折中,稳健 | 计算量稍大 |
| Ward (最小方差) | “混乱度”:合并后,世界的混乱程度增加最少。 | $\min \Delta ESS$ | 效果最好,簇大小均匀 | 偏向球形簇,计算量最大 |
👑 推荐:在大多数情况下,优先使用 Ward’s Method。如果你处理的是文本数据(余弦距离),则推荐 Average Linkage。
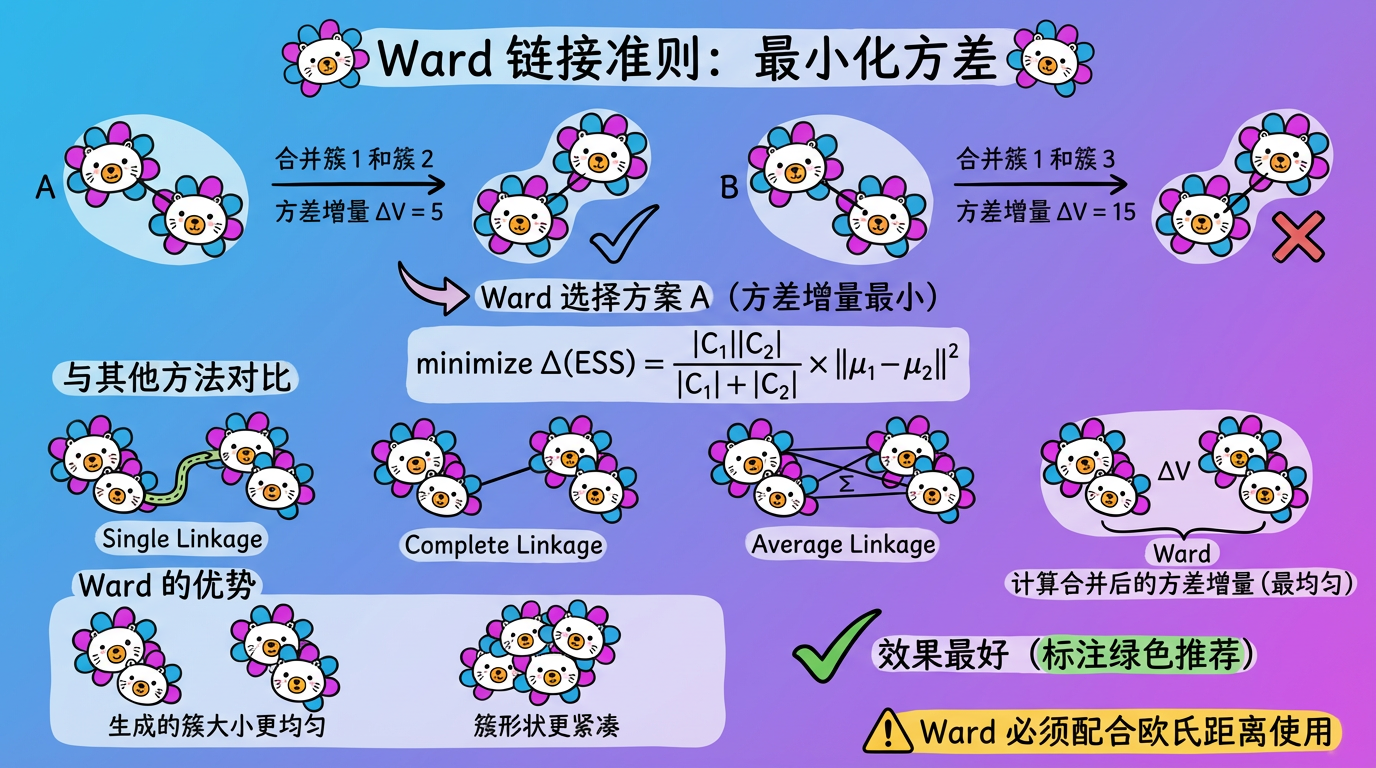
(图注:Ward 方法选择使簇内方差增量最小的合并方案,生成的簇更紧凑、大小更均匀。)
3. 代价:由于太贵,富人专用?
层次聚类虽然结构优美,逻辑清晰,但它有一个致命的缺点:计算复杂度 (Complexity) 太高。
| 算法 | 时间复杂度 | 空间复杂度 | 这种复杂度意味着什么? |
|---|---|---|---|
| K-Means | $O(N \cdot K \cdot I)$ | $O(N)$ | 线性增长。数据翻倍,时间翻倍。亲民。 |
| 层次聚类 | $O(N^2 \log N)$ | $O(N^2)$ | 平方级增长。数据翻倍,内存翻 4 倍。昂贵。 |
算一笔账:
为了知道谁和谁最近,层次聚类需要计算并存储所有点两两之间的距离(距离矩阵 Distance Matrix)。
- 如果你有 1 万个样本,距离矩阵有 $10^8$ 个格子 -> 约 400MB 内存。还能接受。
- 如果你有 10 万个样本,距离矩阵有 $10^{10}$ 个格子 -> 约 40GB - 80GB 内存。普通服务器直接爆炸。
结论:层次聚类通常只适用于小数据集(样本量 < 3万)。如果你有百万级数据,请出门左转找 K-Means 或 BIRCH(一种专门为大数据设计的层次聚类改进版)。
4. 商业价值:为什么我们还是需要它?
既然它这么慢,为什么没被淘汰?因为它的“多粒度视角”在商业分析中太值钱了。
场景:电商平台的动态风险分级
运营团队不仅想看 80 个具体的问题类型,还想看宏观的 5 大类。
- L1 (K=5):物流、商品、服务、支付、App体验。
- L2 (K=20):物流下面细分为:丢件、慢、破损…
- L3 (K=80):丢件下面细分为:虚假签收、驿站丢失、快递员偷吃…
如果你用 K-Means:你需要分别跑 K=5, K=20, K=80 三次模型。而且这三次的结果可能不兼容(K=20 里的某个簇,可能有一半人来自 K=5 的簇 A,另一半来自簇 B,乱套了)。
如果你用层次聚类:只需要训练一次树。然后像切蛋糕一样:
- 在树根附近横切一刀 -> 得到 5 大类。
- 往下一层横切一刀 -> 得到 20 中类。
- 再往下一层 -> 得到 80 小类。
这些类别是完美嵌套的(Sub-cluster),逻辑极其清晰,非常适合构建标签体系 (Tagging System)。
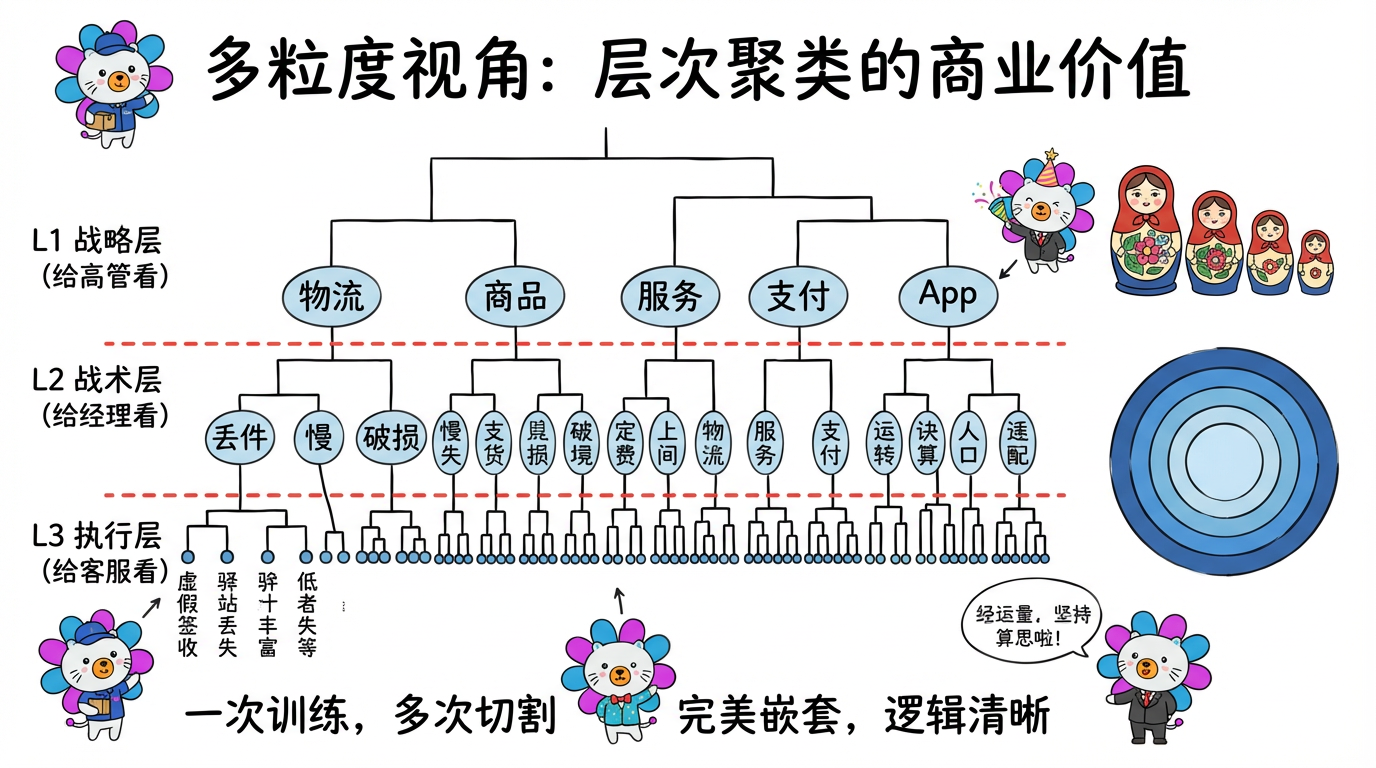
(图注:一次训练,多次切割。在不同高度横切,得到不同粒度的分类体系。)
5. 代码实战:画出家谱树
Python 的 scipy 库提供了非常棒的绘图工具。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
import matplotlib.pyplot as plt
import numpy as np
# 1. 准备数据
# 假设我们有 50 个样本,每个样本 2 维
X = np.random.rand(50, 2)
# 2. 训练:生成链接矩阵 (Linkage Matrix)
# 这一步是计算量最大的,Z 包含了树的所有合并历史
# method='ward' 是最推荐的默认参数
Z = linkage(X, method='ward')
# 3. 绘图:Dendrogram (树状图)
plt.figure(figsize=(10, 5))
dendrogram(Z)
# 画一条红色的横线,表示我们在哪里“剪了一刀”
# y=1.5 是一个假设的距离阈值
plt.axhline(y=1.5, c='r', ls='--', label='Cut Threshold')
plt.title('Hierarchical Clustering Dendrogram')
plt.xlabel('Sample Index')
plt.ylabel('Distance')
plt.legend()
plt.show()
# 4. 获取结果:这一刀剪下去,大家都属于哪个簇?
# t=1.5: 阈值
# criterion='distance': 按照距离来切
labels = fcluster(Z, t=1.5, criterion='distance')
print(f"在距离 1.5 处切割,我们得到了 {len(np.unique(labels))} 个簇。")
# 或者,你可以直接指定要几个簇(类似 K-Means)
# t=3: 我就要 3 个簇,你自己帮我找在哪里切
labels_k3 = fcluster(Z, t=3, criterion='maxclust')6. 实践要点
- 预处理:和 K-Means 一样,层次聚类对距离非常敏感,必须做归一化 (Normalization)。
- 大数据解决方案:
- 如果你真的想在 100 万数据上用层次结构,怎么办?
- 两阶段法 (Two-stage Clustering):先用 K-Means (K=1000) 把 100 万个点聚成 1000 个小簇中心。然后对这 1000 个中心点跑层次聚类。既快又有层次感。
- 度量选择:
- Ward 方法必须配合 欧氏距离 (Euclidean) 使用,这是数学原理决定的。
- 如果你处理的是文本(需要余弦距离),请使用 Average Linkage 或 Complete Linkage,配合
metric='cosine'。
下一章预告
到目前为止,我们介绍的 K-Means、DBSCAN、层次聚类,它们都有一个共同点:硬聚类 (Hard Clustering)。
意思是:一个样本,要么属于 A 组,要么属于 B 组,非黑即白。
但在现实世界,很多事情是模棱两可的。
- “这句话 70% 是在抱怨物流慢,但也有 30% 是在抱怨客服态度不好。”
- “这个用户既像高价值用户,又有点像流失用户。”
有没有一种算法,能给出一个概率值,而不是一个绝对的标签?告诉我们事物的不确定性?



