


“在拥挤的城市里,社区是由密度定义的,而不是由圆心定义的。”
想象一下,你站在上海的人民广场或者纽约的时代广场。你怎么判断哪些人是一伙的?
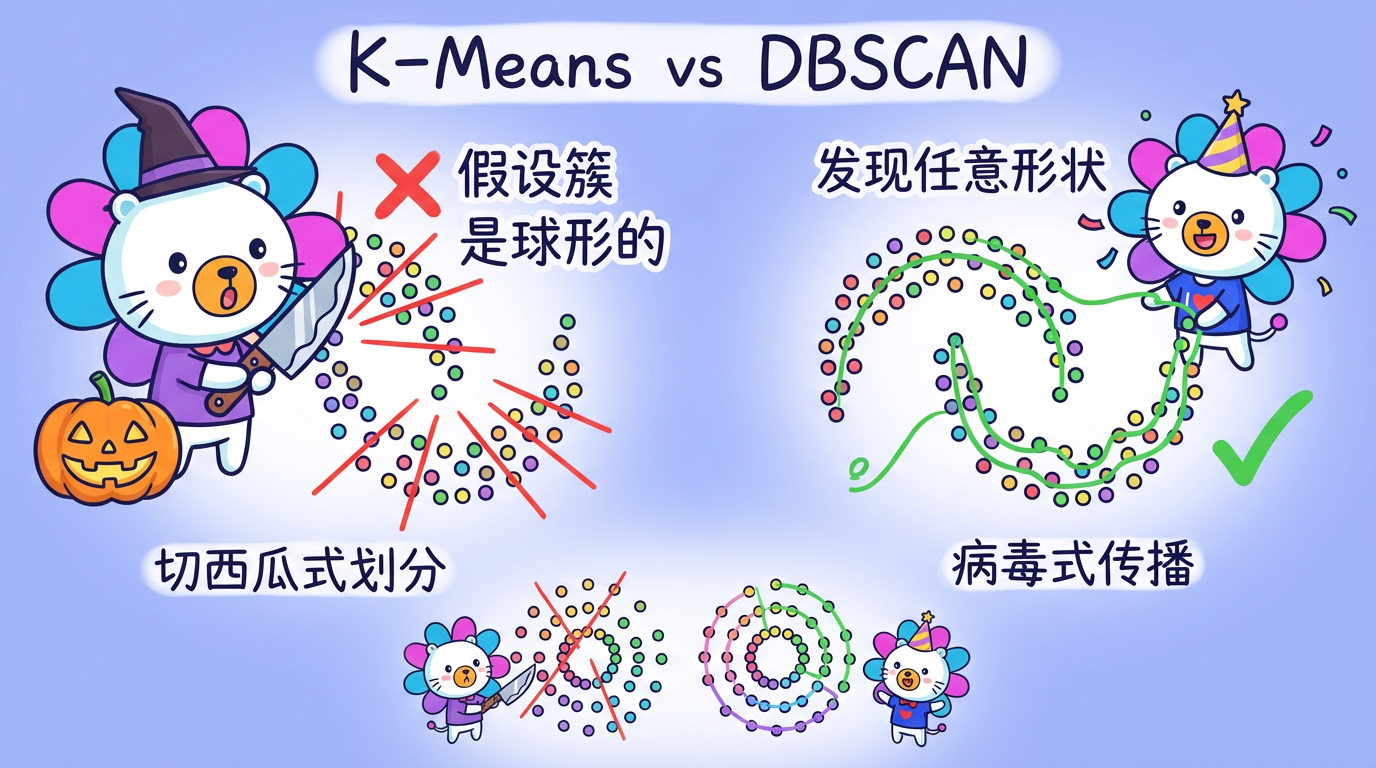
K-Means 算法像是一个拿着圆规的管理员。它假设大家都是以某个中心站成一个个圆圈。如果一群人排成了长长的贪吃蛇队伍(非凸形状),或者环绕着喷泉站成了一个甜甜圈形状,K-Means 就彻底傻眼了——它会强行把“贪吃蛇”切成几段,或者把“甜甜圈”切成几块蛋糕。
但在现实世界中,数据的形状千奇百怪。有些客户群体像细长的河流(比如随着时间推移的特定行为模式),有些像紧密的蜂巢。
本章我们将介绍 DBSCAN,一种基于密度的聚类算法。它不需要你预先告诉它“这里有 3 类人”,它更像是一场流感或者谣言的传播:只要人挨着人(密度够大),它就会一直蔓延下去,直到遇到空旷地带才会停止。它能自动发现那些蜿蜒曲折、形状古怪的“社区”。
(图注:左边是 K-Means,它笨拙地把笑脸形状切成了几块;右边是 DBSCAN,它完美地识别出了眼睛、嘴巴和脸庞轮廓。)
1. 核心概念:怎么才算“挤”?
DBSCAN 的全称是 Density-Based Spatial Clustering of Applications with Noise(带噪声的基于密度的空间聚类)。它的名字已经暴露了它的三个特性:基于密度、能处理噪声、空间聚类。
它只依赖两个核心参数,我们可以把它们想象成派对门槛:
- $\epsilon$ (Eps - $\epsilon$-neighborhood):邻域半径。也就是你伸手能摸到的范围(你的朋友圈半径)。
- MinPts (Minimum Points):最小点数。在这个 $\epsilon$ 半径的圈子里,至少得站多少个人(包括你自己),这里才算是一个高密度区域。
三种角色:派对上的众生相
基于这两个参数,DBSCAN 把世界上的每一个点(每个人)分成了三种角色:
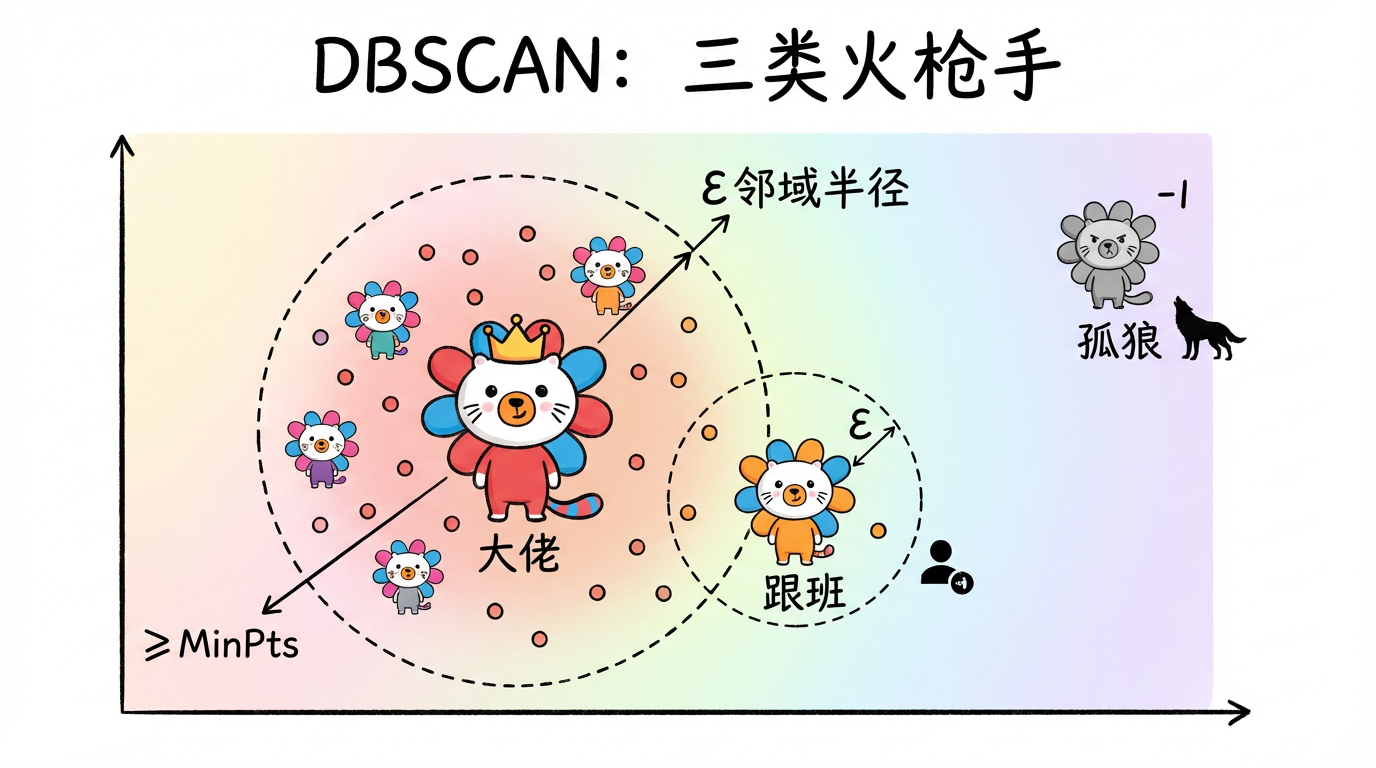
(图注:红色的是核心点,它们被人群包围;黄色的是边界点,它们在边缘蹭着核心点;蓝色的是噪声点,孤零零地在远处。)
核心点 (Core Object/Point)
- 定义:在他的 $\epsilon$ 半径邻域里,样本数 $\ge$ MinPts。
- 通俗解释:“派对发起人”。社交达人,人群的中心。他走到哪里,哪里就是聚落的核心。
边界点 (Border Object/Point)
- 定义:他自己的邻域里样本数 < MinPts,但是,他落在了某个“核心点”的邻域内。
- 通俗解释:“跟班”。虽然自己不够社牛(周围人不够多),但他紧紧跟着社牛(在核心点的圈子里)。他属于这个簇,但处于簇的边缘。
噪声点 (Noise/Outlier)
- 定义:既不是核心点,也不是边界点。
- 通俗解释:“孤狼”。特立独行,离谁都远。在数据分析中,这通常代表异常值或者脏数据。
专业术语小贴士
在阅读文献时,你还会看到这几个词,它们描述了点之间的关系:
- 直接密度可达 (Directly Density-Reachable):如果 A 是核心点,B 在 A 的 $\epsilon$ 邻域里,那么 B 从 A 直接密度可达。
- 密度可达 (Density-Reachable):如果有一连串的点 $P_1, P_2, …, P_n$,其中 $P_1$ 是 A, $P_n$ 是 B,且每一个点都能“直接密度可达”下一个点,那么 B 从 A 密度可达。(像传声筒一样)。
- 密度相连 (Density-Connected):如果存在一个核心点 O,使得 A 和 B 都能从 O 密度可达,那么 A 和 B 就是密度相连的。(我们有共同的朋友)。
2. 聚类过程:传染病模型
DBSCAN 找簇的过程,不需要复杂的迭代优化(如 K-Means 的 EM 算法),完全就是一个“传帮带”的遍历过程。
- 随机点名:随机选择一个未访问过的点 P。
- 核酸检测 (区域查询):
- 计算 P 的 $\epsilon$ 邻域内有多少个点。
- 情况一:密度不足。如果点数 < MinPts,P 暂时标记为 噪声。(注意:如果后面它被某个核心点圈进去了,它可以“平反”为边界点)。
- 情况二:密度达标。如果点数 $\ge$ MinPts,P 确诊为 核心点。创建一个新簇 $C$,把 P 和它邻域里的所有点都加入 $C$。
- 病毒扩散 (区域生长):
- 对于刚被拉进 $C$ 的每个邻居 Q,继续检查:
- 如果 Q 也是核心点,那么把 Q 的邻居们也都拉进 $C$(密度可达的传递性)。
- 如果 Q 是边界点,传播链条在 Q 这里终止。
- 对于刚被拉进 $C$ 的每个邻居 Q,继续检查:
- 循环:重复上述过程,直到所有点都被访问过。
结果:所有密度相连的点集构成了一个个簇,剩下的就是噪声。
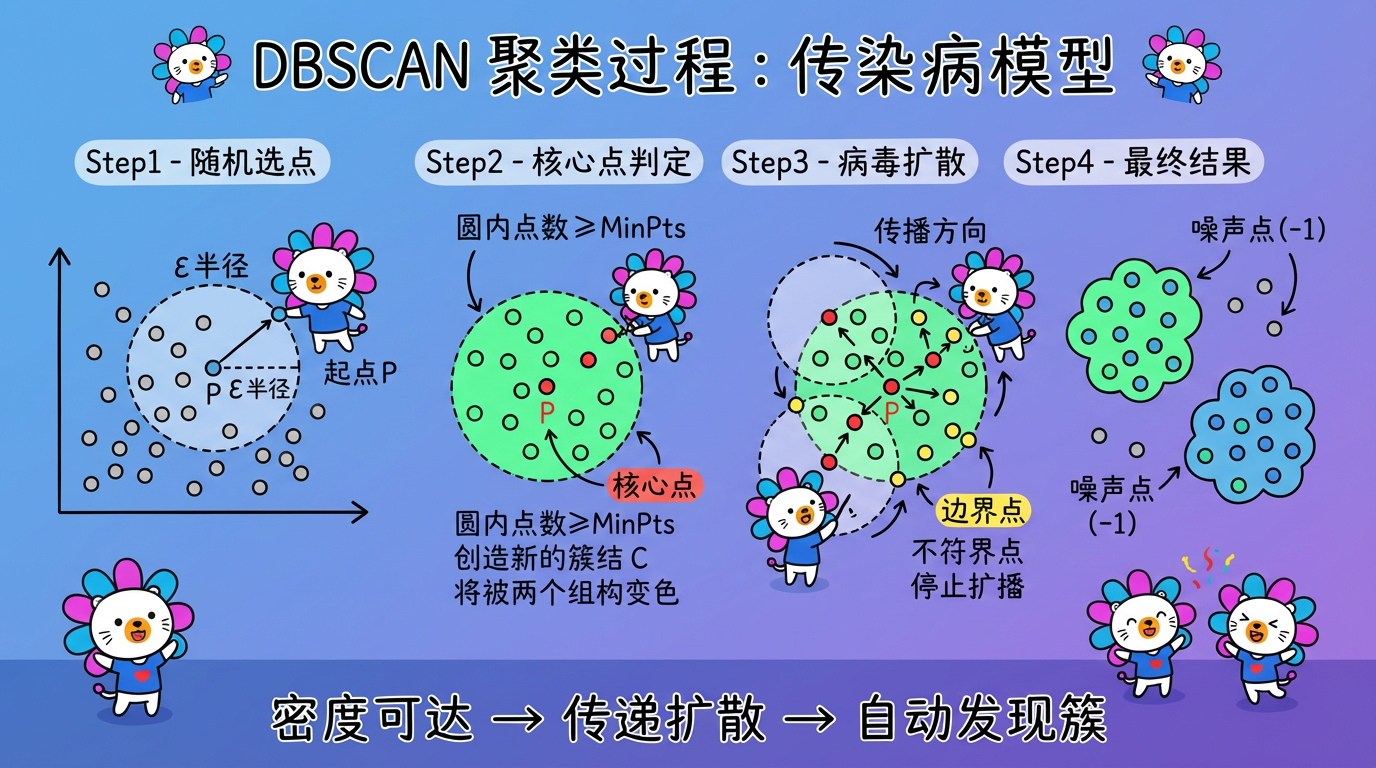
(图注:DBSCAN 像传染病一样扩散,核心点不断传播,边界点终止传播,噪声点被孤立。)
3. 技术对比:密度聚类家族谱系
DBSCAN 是密度聚类的鼻祖,但它也有软肋。为了解决它的问题,学术界衍生出了一个庞大的家族。了解这些变体,能让你在选型时更专业。
| 算法 | 核心痛点解决 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| DBSCAN | (基准) | 无需 K,发现任意形状,自带异常检测 | 参数极难调 ($\epsilon$),无法处理密度不均 | 低维、形状复杂的数据 |
| OPTICS | $\epsilon$ 难确定 | 对 $\epsilon$ 不敏感,生成可达距离图 (Reachability Plot) | 计算量大,不直接出簇 (需二次处理) | 探索性数据分析,观察数据结构 |
| HDBSCAN | 层次化 + 密度 | 无需 $\epsilon$,自动选择最优簇数,最鲁棒 | 算法复杂,解释性略差 | 目前最佳的密度聚类算法 |
| Mean-Shift | 核密度估计 | 无需参数,自适应 | 极慢 ($O(N^2)$),主要用于图像 | 图像分割,低维平滑数据 |
4. 为什么它是数据科学家的“备胎”?
尽管有上述家族成员,但在实际的工业界项目中(尤其是文本挖掘、用户分层),我们往往首选 K-Means,而把 DBSCAN 当作备选方案。为什么?
痛点 1:参数 $\epsilon$ 极其难调
选 K 值(聚成几类)虽然难,但也就是在 5 到 100 之间猜。但 $\epsilon$ 是一个连续的距离值,且对数据分布非常敏感。
- $\epsilon$ 太小:数据稍微稀疏一点,就被判为噪声。结果:产生大量的簇和大量的噪声点。
- $\epsilon$ 太大:不同密度的簇被合并。结果:所有点都归为一个巨型簇。
痛点 2:维度灾难 (The Curse of Dimensionality)
这是最致命的。在文本向量(如 768 维 BERT 向量)的高维空间里:
- 距离失效:根据距离集中效应,高维空间中任意两点的距离都趋于一致。
- 稀疏性:高维空间极度空旷,很难满足 MinPts 的密度要求。
- 结论:在未经降维的高维数据上直接跑 DBSCAN,效果通常极差。
痛点 3:密度不均 (Varying Density)
如果数据集包含不同密度的簇(例如:市中心的人群非常密集,而郊区的聚落相对稀疏)。
- DBSCAN 只有一组全局参数 ($\epsilon$, MinPts)。
- 如果参数适应了高密度区,低密度区就会变成噪声。
- 如果参数适应了低密度区,高密度区就会被合并成一个大块。
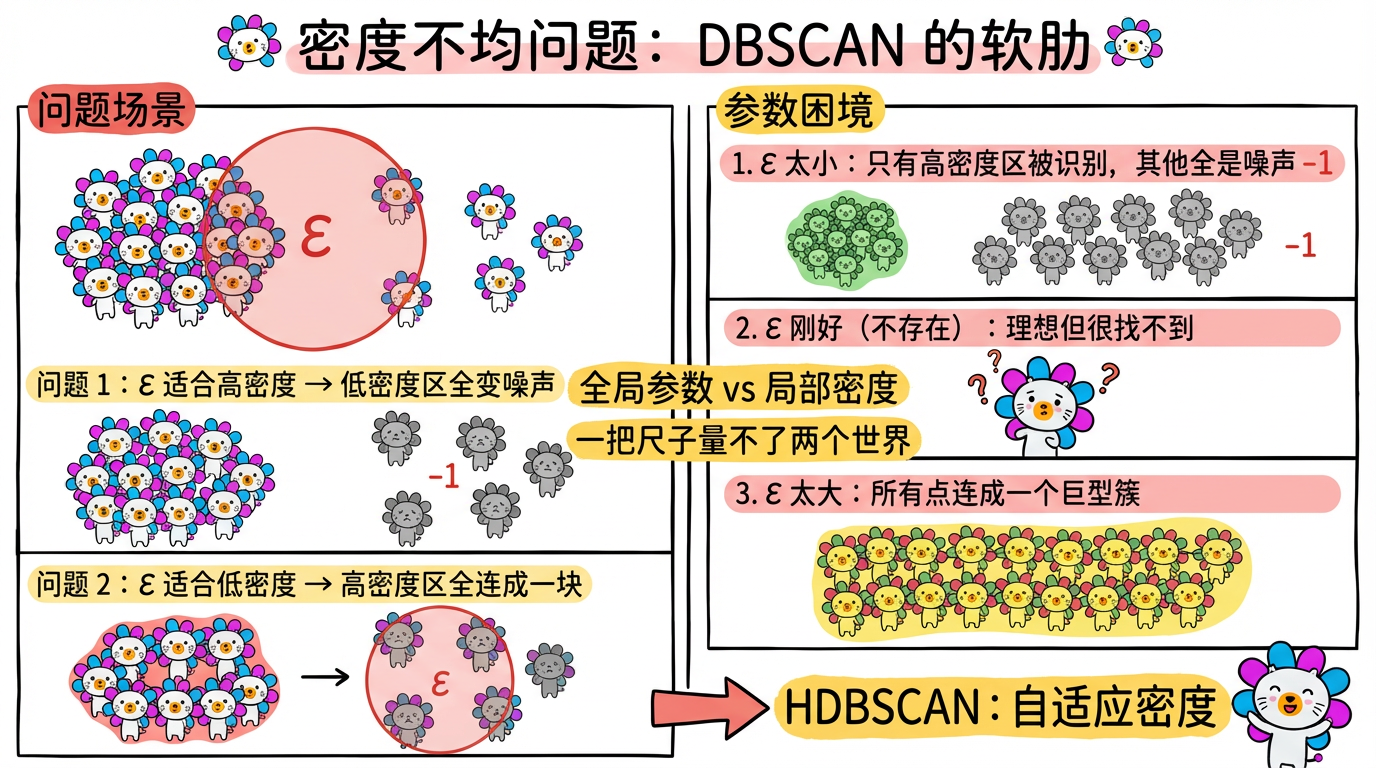
(图注:一把尺子量不了两个世界。HDBSCAN 通过自适应密度解决了这个问题。)
5. 什么时候非用它不可?
尽管有上述缺点,DBSCAN 在以下场景是无可替代的:
- 地理位置数据 (Geo-Spatial Data):
- 经纬度只有 2 维,不存在维度灾难。
- 物理世界的聚落(商圈、住宅区)本身就是基于密度的自然分布。
- 异常检测 (Anomaly Detection):
- 有时候我们的目的不是聚类,而是抓坏人。DBSCAN 跑完后,那些标记为 -1 的点,往往就是信用卡欺诈、网络攻击或者设备故障的数据。
- 非球形簇:
- 如果你用 UMAP/t-SNE 降维后,发现数据明显呈现出弯曲的长条状,K-Means 切不开,这时候必须上 DBSCAN。
6. 代码实战:DBSCAN vs HDBSCAN
为了解决 DBSCAN 调参难和密度不均的问题,Campello 等人在 2013 年提出了 HDBSCAN (Hierarchical DBSCAN)。
- DBSCAN:静态的截断。必须指定固定的 $\epsilon$。
- HDBSCAN:结合了层次聚类和密度聚类。它把 $\epsilon$ 看作一个变化的变量,构建一棵聚类稳定性树,自动选择最稳定的簇。
强烈推荐:在 Python 中,尽可能优先使用 hdbscan 库,而不是 sklearn 自带的 DBSCAN。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
import hdbscan # 需要安装: pip install hdbscan
from sklearn.datasets import make_moons
# 1. 制造数据:生成两个“新月”形状的数据
# 这种非凸形状是 K-Means 的噩梦
X, _ = make_moons(n_samples=500, noise=0.1, random_state=42)
# ==========================================
# 方法 A: 传统 DBSCAN (Sklearn)
# ==========================================
# 痛点:你需要反复尝试 eps 的值。0.1? 0.2? 0.15?
# 这里的 0.15 是我们试出来的“上帝视角”最优解
db = DBSCAN(eps=0.15, min_samples=5).fit(X)
labels_db = db.labels_
# ==========================================
# 方法 B: HDBSCAN (推荐)
# ==========================================
# 优点:只需要思考业务逻辑——“哪怕最小的群体,也不能少于 10 人吧?”
# 不需要关心具体的距离数值,它能自适应不同密度的簇。
hdb = hdbscan.HDBSCAN(min_cluster_size=10).fit(X)
labels_hdb = hdb.labels_
# 打印结果
# -1 代表噪声 (Noise)
n_noise_db = list(labels_db).count(-1)
n_noise_hdb = list(labels_hdb).count(-1)
print(f"DBSCAN 发现噪声点数: {n_noise_db}")
print(f"HDBSCAN 发现噪声点数: {n_noise_hdb}")实用技巧:如何确定 DBSCAN 的 eps?
如果你必须用传统的 DBSCAN(比如为了兼容性),这里有一个“膝盖法则” (Knee Method / k-distance graph) 来找最佳 $\epsilon$:
- 计算每个点到它第 k 个最近邻居的距离(通常取 k=MinPts)。
- 把这些距离从大到小排序。
- 画出曲线图。
- 找到曲线急剧弯曲的那个“拐点”(膝盖位置)。该位置对应的距离值,就是不错的 $\epsilon$ 初始值。
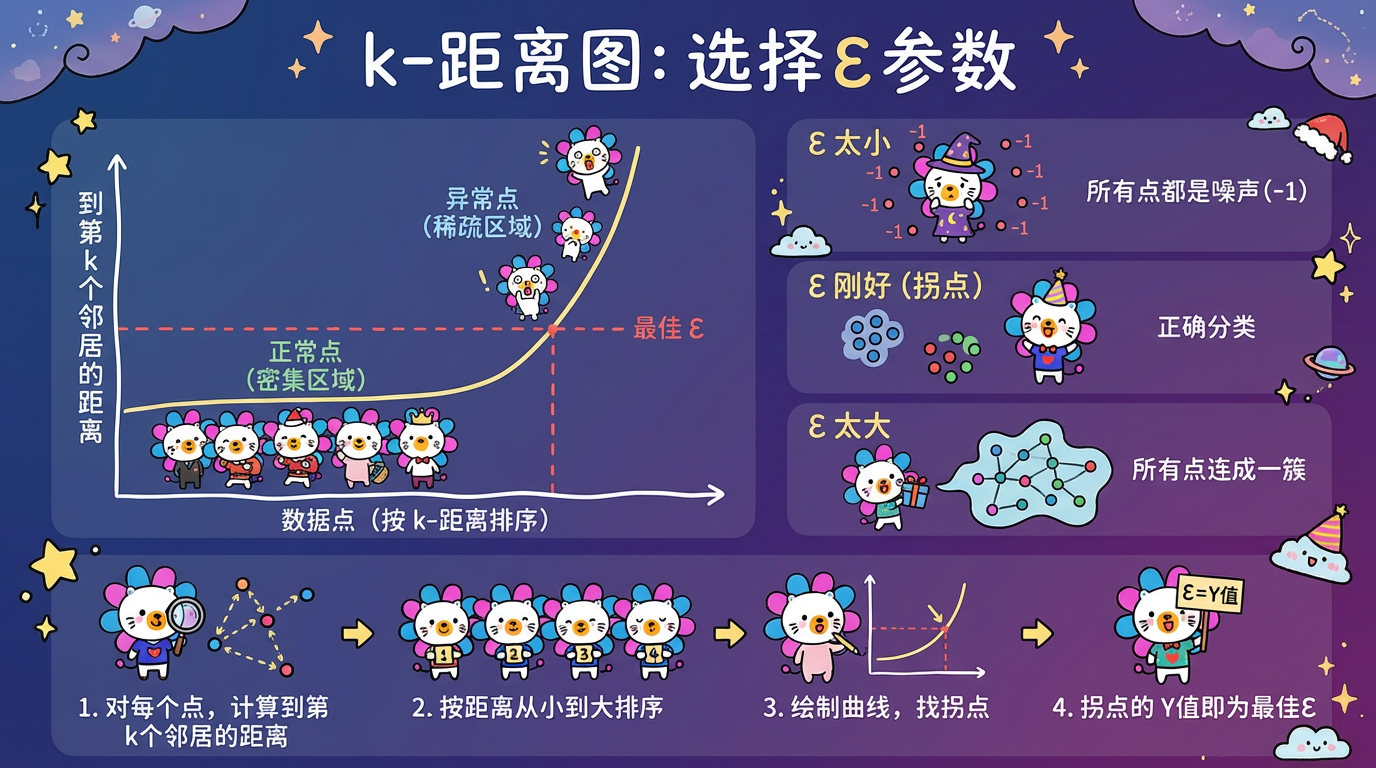
(图注:横轴是点的序号,纵轴是 k-dist。在曲线突然陡峭上升的地方,意味着点开始变得稀疏,这正是簇的边界。)
7. 总结与预告
| 特性 | K-Means | DBSCAN | HDBSCAN |
|---|---|---|---|
| 核心思想 | 距离划分 (Partitioning) | 密度传播 (Density) | 层次密度 (Hierarchical Density) |
| 形状假设 | 凸形/球形 (Convex) | 任意形状 | 任意形状 |
| 参数 | K (簇数) | $\epsilon$ (半径), MinPts | MinPts (最小簇大小) |
| 噪声处理 | 无 (强行归类) | 识别并剔除 | 识别并剔除 |
| 密度敏感度 | 均一密度 | 均一密度 | 自适应不同密度 |
DBSCAN 告诉我们,聚类不一定是切蛋糕,也可以是病毒传播。它让我们看到了数据中更自然的拓扑结构。
然而,无论是 K-Means 还是 DBSCAN,它们都有一个共同的局限性:它们都是“扁平”的。它们给你的是一张这一刻的世界地图。
但生物学家会告诉你,世界不是扁平的,而是分层的 (Hierarchical):从动物界到脊索动物门,再到哺乳纲、灵长目……
如果我们想从数据中得到这种树状的家谱,该怎么办?



