


“虽然它诞生于 1957 年,但它依然是数据挖掘界的 AK-47——简单、粗暴、有效。”
1. 导言:牧羊人的智慧
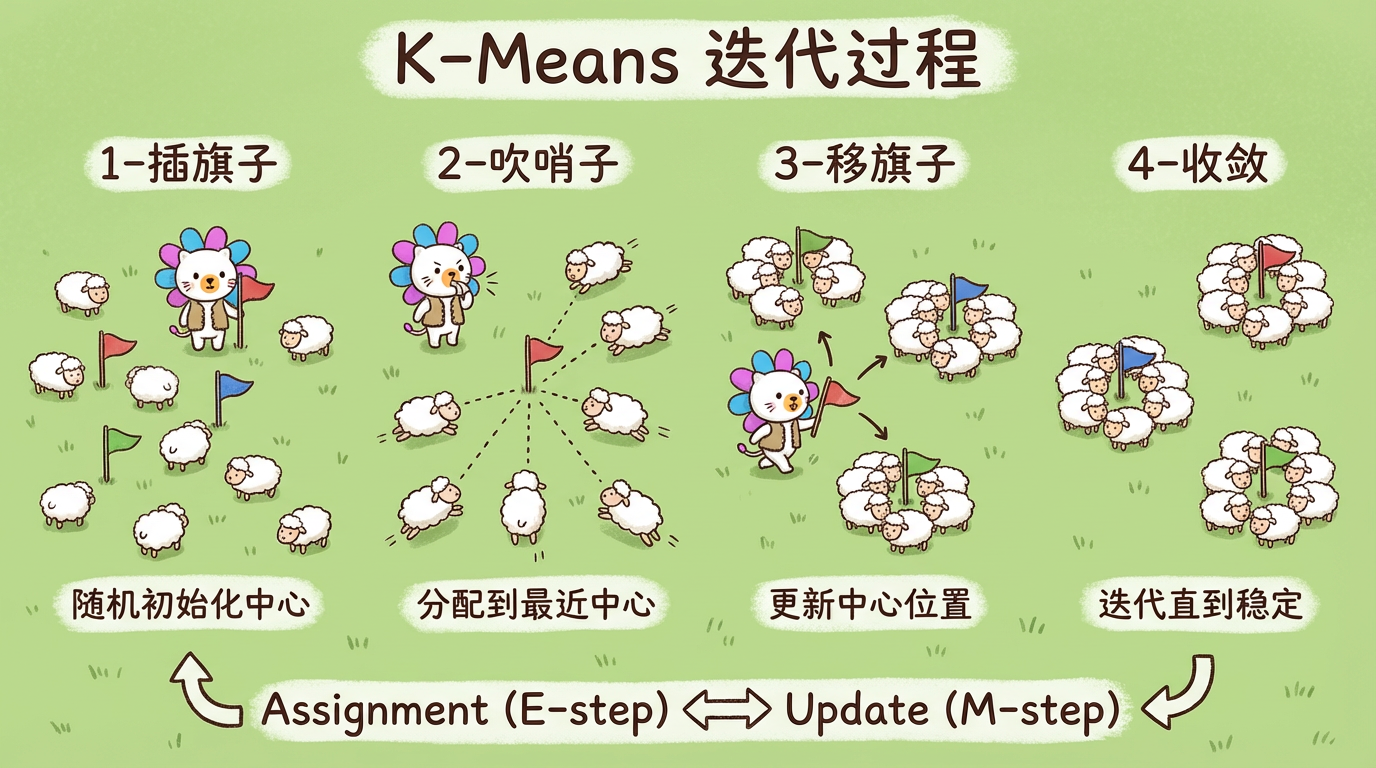
如果把你扔到一个大草原上,给你 1000 只羊,让你把它们分成 3 群,你会怎么做?
你可能会插 3 根旗子,然后吹哨子让羊跑到离自己最近的旗子那里去。
然后你发现,某个旗子插歪了,羊群并不集中。于是你拔起旗子,走到羊群的中心重新插下。
再吹哨子,羊群微调位置。
重复几次,羊群就分得整整齐齐了。
这就是 K-Means 算法的直觉:选中心 -> 分组 -> 移中心 -> 再分组。
这种将数据划分为互不重叠的子集的方法,称为 划分式聚类 (Partitional Clustering)。
2. 核心概念:K-Means 的数学之美
2.1 目标函数 (Inertia)
K-Means 的目标非常单纯:让每个点到它老大的距离之和最小。
数学上,我们要最小化 簇内平方和 (Within-Cluster Sum of Squares, WCSS):
$$ J = \sum_{k=1}^K \sum_{x \in C_k} ||x - \mu_k||^2 $$
- $K$:簇的数量(比如 80)。
- $\mu_k$:第 $k$ 个簇的中心点 (Centroid)。
- $x$:样本点。
2.2 Lloyd 算法:两步走
为了解这个方程,我们使用迭代法(Lloyd 算法):
- Assignment (E-step):固定中心 $\mu$,把每个点 $x$ 分配给最近的中心。
$$ C_k = {x : ||x - \mu_k|| \le ||x - \mu_j||, \forall j} $$ - Update (M-step):固定分组 $C$,重新计算中心 $\mu$(取平均值)。
$$ \mu_k = \frac{1}{|C_k|} \sum_{x \in C_k} x $$
重复这两步,直到中心不再移动。数学证明,这个过程一定会收敛(虽然可能收敛到局部最优)。
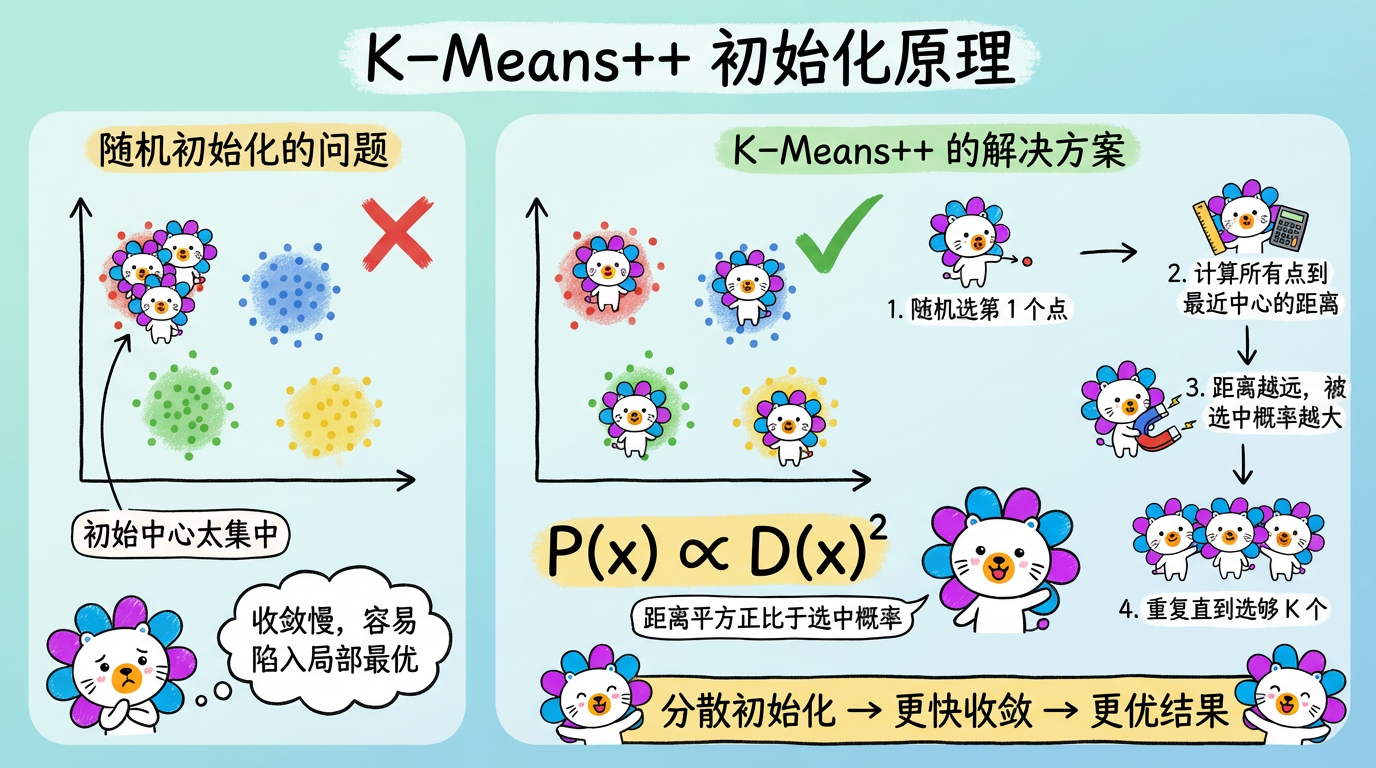
2.3 初始化陷阱:K-Means++
最原始的 K-Means 是随机选 3 个点做中心。
但这有个大坑:如果运气不好,选的 3 个点挤在一起怎么办?
K-Means++ 提出了一种聪明的策略:
- 第 1 个点:随机选。
- 第 2 个点:离第 1 个点越远,越容易被选中(概率正比于距离平方)。
- …
这样能保证初始中心尽可能分散,大大提升了算法的稳定性和速度。
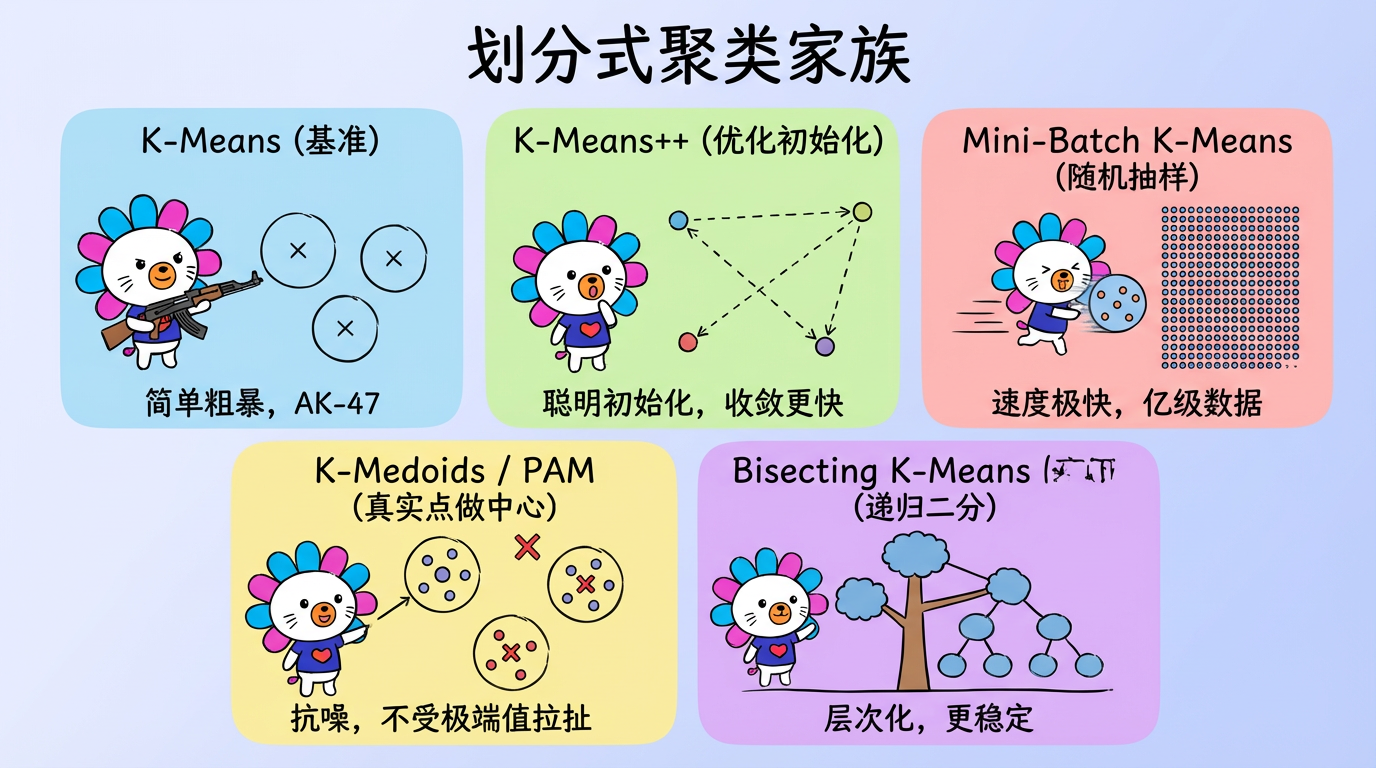
3. 技术对比:K-Means 家族
虽然 K-Means 是老大哥,但它也有很多表亲,分别解决了它的不同弱点。
| 算法 | 核心改进 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| K-Means | 基准 | 简单,可解释,适合球形簇 | 对离群点敏感,需指定 K | 通用场景 |
| K-Means++ | 优化初始化 | 收敛更快,结果更优 | 初始化略慢 | 默认首选 |
| Mini-Batch K-Means | 随机抽样更新 | 速度极快,支持海量数据流 | 精度略有下降 | 亿级数据,实时流处理 |
| K-Medoids (PAM) | 选真实点做中心 | 抗噪(不受极端值拉扯) | 慢 ($O(N^2)$) | 数据脏、有离群点的小数据集 |
| Bisecting K-Means | 递归二分 | 层次化,更稳定 | 无法回溯 | 需要层级结构的场景 |
4. 代码实战:从原理到 Scikit-Learn
4.1 手写 K-Means (Python)
为了理解原理,我们写一个极简版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import numpy as np
def simple_kmeans(X, k, max_iters=100):
# 1. 随机初始化中心
centroids = X[np.random.choice(X.shape[0], k, replace=False)]
for _ in range(max_iters):
# 2. Assignment: 计算距离并分组
# distances shape: (N, k)
distances = np.linalg.norm(X[:, np.newaxis] - centroids, axis=2)
labels = np.argmin(distances, axis=1)
# 3. Update: 2025-12-22 09:20:00
new_centroids = np.array([X[labels == i].mean(axis=0) for i in range(k)])
# 收敛检测
if np.all(centroids == new_centroids):
break
centroids = new_centroids
return labels, centroids4.2 工程实践中的应用
在实际项目中,通常使用成熟的 sklearn.cluster.KMeans。
1
2
3
4
5
6
7
8
# 代码引用: cluster_analysis.py
kmeans = KMeans(
n_clusters=80, # 这是一个很大的 K,我们采用了“过聚类”策略
init='k-means++', # 使用聪明初始化
n_init=10, # 跑 10 次取最好,防止局部最优
random_state=42 # 保证结果可复现
)
cluster_labels = kmeans.fit_predict(embeddings)工程思考:为什么选 80?
在无监督学习中,K 值的选择往往不是数学问题,而是业务问题。
- 如果 K=5,虽然数学指标(如轮廓系数)可能很高,但业务上没法用(“物流问题”太笼统了)。
- 如果 K=80,我们能把“物流”拆解为“丢件”、“慢”、“态度差”、“破损”等具体问题。
- 宁可分碎,不可分错。后续我们可以通过合并相似簇来减少数量,但如果一开始就混在一起了,后面就分不开了。
5. 实践要点
- 数据标准化:K-Means 对距离极其敏感。如果你的特征一个是“年龄(0-100)”,一个是“收入(0-10000)”,K-Means 会完全被收入主导。必须先做 StandardScaler。当然,Embedding 向量通常已经 Normalized 了,所以可以直接跑。
- 异常值处理:一个离群点可能会把中心拉偏十万八千里。建议先剔除异常值,或者使用 K-Medoids。
- K 的选择:不要迷信“手肘法 (Elbow Method)”。在工业界,通常根据运营人力来定 K。如果你有 5 个运营小组,K=50 可能比较合适(每组看 10 类)。
下一章预告:
K-Means 有个致命弱点:它假设簇是凸的(球形的)。
如果数据长得像新月形,或者环形(同心圆),K-Means 会切得乱七八糟。
这时候,我们需要一种不依赖距离,而是依赖密度的算法——DBSCAN。



