


“在高维空间里,每个人都是孤独的。”
欢迎来到 1536 维的世界。这里是 Embedding 的家园,也是直觉的坟墓。
我们的大脑是为三维世界进化的。我们很难想象,当维度增加到 1000 以上时,几何规则会发生怎样翻天覆地的变化。
这一章我们将揭示一个可怕的现象——维度灾难 (The Curse of Dimensionality),以及一个美好的奇迹——维度祝福。
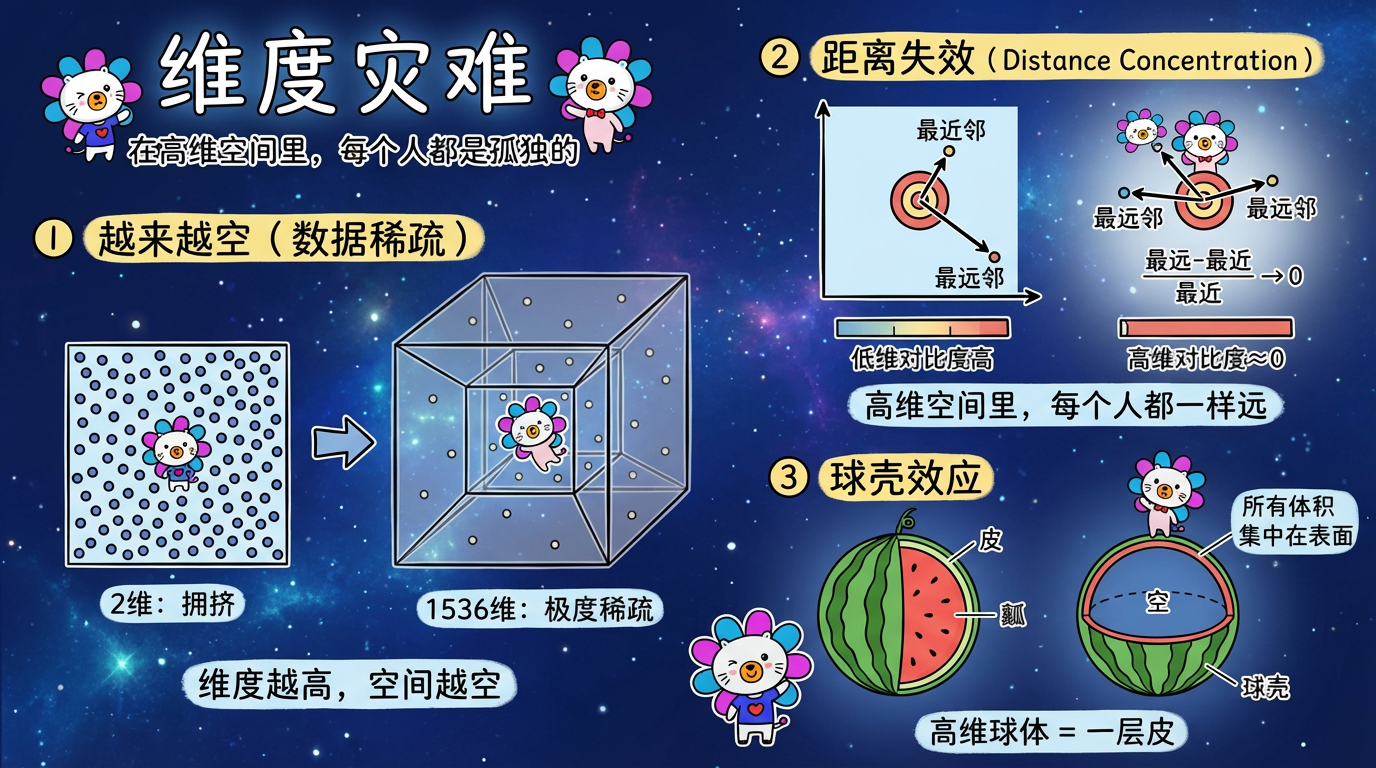
1. 维度灾难:空旷的宇宙
1.1 越来越空
想象一个边长为 1 的正方形(2维)。如果你往里面撒 100 个点,它会显得很拥挤。
现在,保持边长为 1,把它变成一个 1536 维的超立方体。
虽然边长没变,但它的“体积”(超体积)指数级膨胀了。
如果你还想保持同样的拥挤程度,你需要撒多少个点?
答案是 $100^{1536/2}$。这个数字比宇宙中所有原子的总和还要大亿万倍。
结论:在高维空间中,任何有限的数据集(哪怕你有 10 亿条数据)都是极度稀疏的。所有的样本点都像是在真空中漂浮的尘埃,彼此相距光年之远。
1.2 距离失效 (Distance Concentration)
这是对聚类算法最致命的打击。
数学推导证明:随着维度 $D \to \infty$,任意两个随机点之间的距离会趋向于常数。
$$ \frac{\text{最远距离} - \text{最近距离}}{\text{最近距离}} \to 0 $$
这意味着:在高维空间里,最近的邻居和最远的陌生人,距离其实差不多!
如果所有人都离你一样远,K-Means 怎么找最近的中心?KNN 怎么找邻居?算法会彻底迷失。
这就是为什么文本分析项目必须在聚类之前或之后进行降维,或者使用余弦相似度(它受维度影响相对较小)。
1.3 球壳效应
在高维球体中,几乎所有的体积都集中在表面(球壳)上,球心是空的。
就像一个西瓜,皮越来越厚,瓤越来越小,最后只剩下一层皮。
所以,我们的 Embedding 向量,本质上都分布在一个 1536 维的超球面上。
2. 维度祝福:Johnson-Lindenstrauss 引理
既然高维这么可怕,为什么现在的 AI 还要用 1536 维,甚至 4096 维?
因为高维空间有一个神奇的祝福:它足够大,大到可以容纳任何形状的流形。
同时,有一个数学定理拯救了我们:Johnson-Lindenstrauss (JL) 引理。
JL 引理:一个在高维空间里的点集,可以被线性投影到一个低得多的维度(比如几百维),而点与点之间的距离关系几乎不变。

直观理解:
想象天空中有一个复杂的星座(3维)。当你把它拍成照片(2维)时,星星之间的相对位置(谁离谁近)通常还是保持得不错的。
这就是随机投影的原理。它告诉我们:我们可以放心地降维,不用担心丢失太多信息。
3. 工业项目的应对策略
面对维度灾难,现代文本分析系统通常采取以下策略:
- 特征提取用高维 (1536D):
利用 Transformer 的高维能力,把语义分得尽可能细。在高维空间里,复杂的语义是线性可分的(容易切开)。 - 距离计算用 Cosine:
避开欧氏距离在高维失效的坑,使用方向来度量相似。 - 可视化用低维 (2D):
利用 UMAP 算法,把高维流形“展开”铺平到 2D 屏幕上。JL 引理保证了这种操作在数学上是靠谱的。
4. 动手时刻:验证距离失效
我们可以写一段代码,亲眼看看随着维度增加,距离是怎么“崩坏”的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import numpy as np
from scipy.spatial.distance import pdist, squareform
import matplotlib.pyplot as plt
def get_contrast(dim):
# 生成 100 个随机点
X = np.random.rand(100, dim)
# 计算两两距离
dists = pdist(X)
# 计算对比度:(最大-最小)/最小
return (dists.max() - dists.min()) / dists.min()
dims = [2, 10, 100, 1000, 5000]
contrasts = [get_contrast(d) for d in dims]
# 你会看到 output 急剧下降
for d, c in zip(dims, contrasts):
print(f"维度: {d:<5} | 距离对比度: {c:.2f}")
# Output 示例:
# 维度: 2 | 距离对比度: 28.5 (很容易区分远近)
# 维度: 1000 | 距离对比度: 0.3 (几乎无法区分)5. 实践要点
- 降维是必选项:处理 Embedding 数据时,如果想做可视化或密度估计,必须降维(PCA/UMAP)。
- 不要在高维空间跑 DBSCAN:DBSCAN 依赖
eps距离阈值。在高维空间,所有点的距离都差不多,你很难找到一个合适的eps。要么全连在一起,要么全散开。 - 向量数据库 (Vector DB):现在的 Milvus, Pinecone 等向量数据库,底层都在做一件事——近似最近邻 (ANN)。它们通过构建图索引(HNSW),在不遍历所有点的情况下,快速找到邻居,从而绕过高维计算的瓶颈。
下一章预告:
理论铺垫终于结束了!我们理解了向量,选择了距离,也知道了维度的坑。
现在,让我们进入算法的核心战场。
最经典的 K-Means 算法,究竟是如何在几万个点中,像牧羊犬一样把羊群赶进羊圈的?



