


“如果不定义‘近’,我们就无法定义‘类’。”
在第 2 章中,我们成功把“投诉”变成了“向量”。
现在,文本分析系统面临一个核心问题:如何判断两条投诉是不是在说同一件事?
- A: “My package is lost.” (向量 $v_A$)
- B: “I haven’t received my item.” (向量 $v_B$)
我们需要一把数学“尺子”来量一量 $v_A$ 和 $v_B$ 之间的距离。
距离越近 $\rightarrow$ 越相似 $\rightarrow$ 应该聚为一类。
但是,数学世界里有无数种尺子。用哪一把?这决定了聚类的生死。
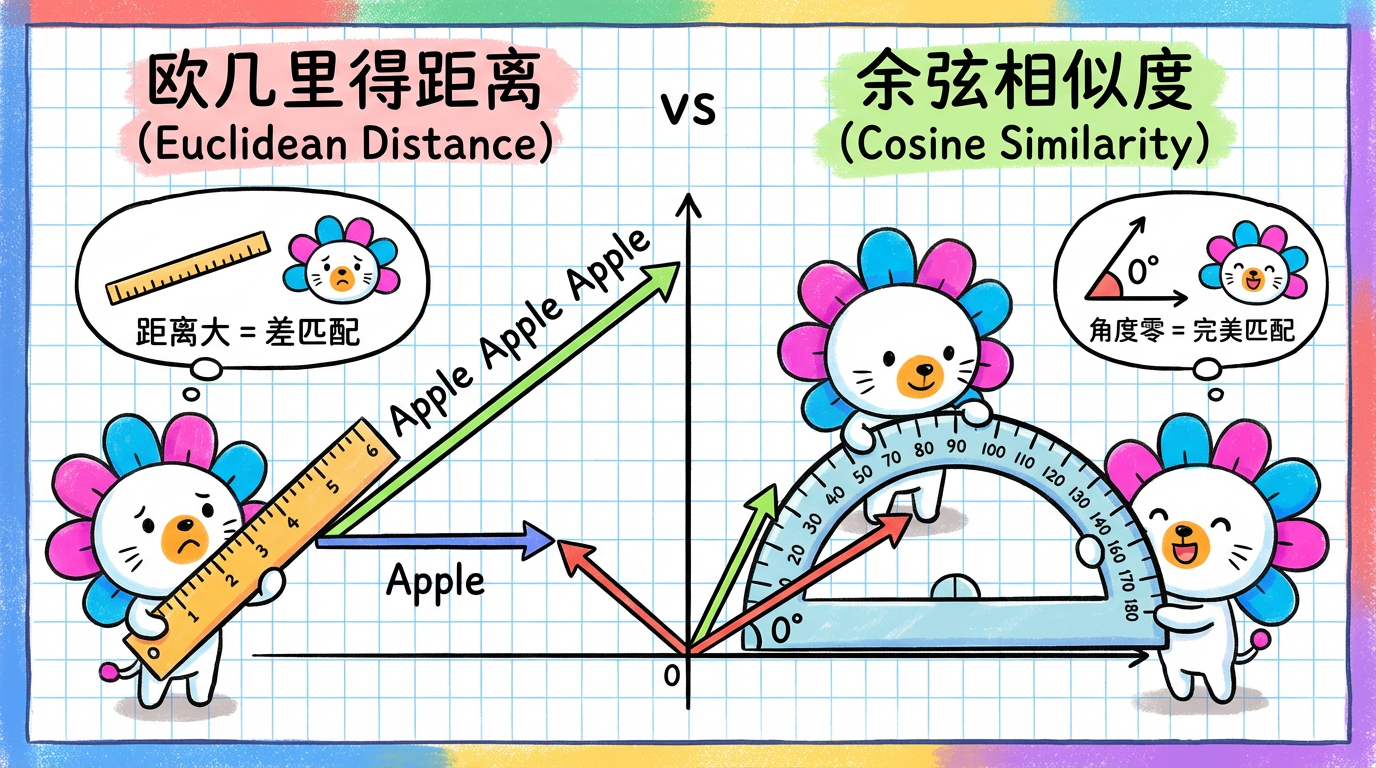
1. 核心概念:常用的几把尺子
1.1 欧氏距离 (Euclidean Distance):直线连接
这是我们最熟悉的尺子,也就是两点间的直线距离。
$$ d(x, y) = \sqrt{\sum (x_i - y_i)^2} $$
- 特点:它对数值的大小非常敏感。
- Bug:在文本分析中,这通常是个灾难。
- 文本 A: “Good” (向量长度短)
- 文本 B: “Good Good Good” (向量长度长,因为词多)
- 文本 C: “Bad” (向量长度短)
- 虽然 A 和 B 意思完全一样,但在欧氏空间里,A 和 B 的距离可能比 A 和 C 还远!因为 B 飞到了空间很远的地方。
1.2 余弦相似度 (Cosine Similarity):看方向,不看长短
这是 NLP (自然语言处理) 领域的黄金标准。它不关心向量有多长,只关心向量指向哪里(夹角)。
$$ \text{Similarity} = \cos(\theta) = \frac{A \cdot B}{||A|| \times ||B||} $$
- 夹角 0 度:完全重合 ($\cos=1$)。比如 “Good” 和 “Good Good Good”。
- 夹角 90 度:完全无关 ($\cos=0$)。比如 “Apple” 和 “Car”。
- 夹角 180 度:截然相反 ($\cos=-1$)。
在文本分析项目中,通常全程使用余弦相似度。因为我们只在乎语义的方向(是物流问题还是支付问题),不在乎用户啰嗦了多少个词(向量长度)。
1.3 曼哈顿距离 (Manhattan Distance):出租车路线
想象在一个方格状的城市里开车,你不能横穿建筑,只能走横竖的街道。
$$ d(x, y) = \sum |x_i - y_i| $$
- 用途:在高维稀疏数据(如推荐系统的用户特征)中,有时比欧氏距离更有效。
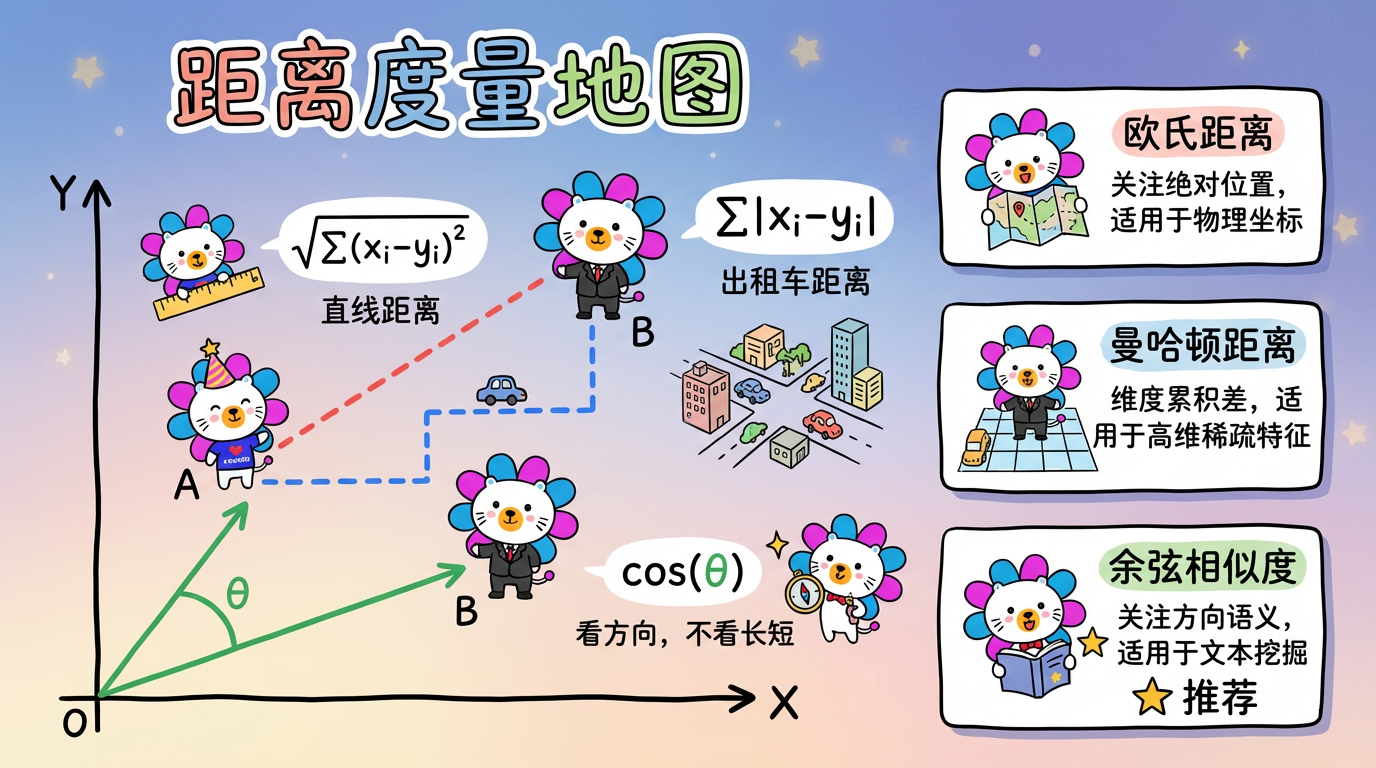
2. 技术对比:什么时候用什么?
| 度量 | 关注点 | 适用场景 | 致命弱点 |
|---|---|---|---|
| 欧氏距离 | 绝对位置 | 物理坐标(GPS)、图像像素、身高体重聚类 | 对量纲敏感(必须先归一化),受向量长度影响大 |
| 余弦相似度 | 方向 (语义) | 文本挖掘、推荐系统、用户兴趣画像 | 不满足三角不等式(严格来说不是“距离”) |
| 曼哈顿距离 | 维度累积差 | 高维稀疏特征(如用户标签匹配) | 旋转不具备不变性(坐标轴旋转后距离会变) |
| Jaccard | 集合重叠度 | 两个集合是否相似(如两个用户买了多少相同的商品) | 忽略了元素的具体数值(只看有无,不看多少) |
3. 工程实战:混合双打
有趣的是,在实际工程中,可以同时使用余弦相似度和欧氏距离,分别用于不同的阶段。这体现了极高的工程技巧。
第一阶段:UMAP 降维 —— 用 Cosine
1
2
3
4
5
# 代码示例
reducer = umap.UMAP(
metric='cosine', # <--- 这里用余弦!
# ...
)理由:在 1536 维的语义空间里,只有方向代表语义。所以降维算法必须依据方向来把相似的点拉近。
第二阶段:异常检测 —— 用 Euclidean
1
2
# 代码示例:计算 UMAP 2D 空间中的局部密度
nbrs = NearestNeighbors(metric='euclidean').fit(coords_2d)理由:当 UMAP 把数据降维到 2D 平面后,数据已经变成了几何坐标 (x, y)。此时,语义已经转化为了位置。在 2D 平面上算密度,当然要用直观的欧氏距离(画圆圈)!
4. 动手时刻:自己算一算
我们用 Numpy 来验证一下 “Good” 和 “Good Good” 的区别。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import numpy as np
from scipy.spatial.distance import euclidean, cosine
# 假设 'Good' 的向量是 [1, 1]
v1 = np.array([1, 1])
# 'Good Good' 只是把词频翻倍,向量变为 [2, 2]
v2 = np.array([2, 2])
# 一个完全不同的词 'Bad',向量是 [-1, 1]
v3 = np.array([-1, 1])
print(f"Good vs GoodGood (欧氏距离): {euclidean(v1, v2):.2f}") # 1.41 (居然有距离!)
print(f"Good vs GoodGood (余弦距离): {cosine(v1, v2):.2f}") # 0.00 (完全一样!这是我们想要的)
print(f"Good vs Bad (余弦距离): {cosine(v1, v3):.2f}") # 1.00 (完全正交/相反)看到没?如果你用欧氏距离,算法会认为“好”和“很好”是两回事。用余弦距离,它们就是一回事。
5. 实践要点
- 归一化 (Normalization):如果你非要用欧氏距离算文本,请务必先对向量做 L2 归一化(把长度都变成 1)。归一化后,欧氏距离的排名就和余弦距离一样了。
- 维度灾难预警:在高维空间(比如 10000 维),欧氏距离会失效(所有点之间的距离都差不多,详见下一章)。而余弦相似度在高维空间依然相对鲁棒。
下一章预告:
我们一直在说“高维空间”。1536 维到底是什么概念?
在那个世界里,发生着一些违反人类直觉的怪事——维度灾难。这直接决定了为什么我们需要降维。



