


“语言是人类思想的密码,Embedding 是解开这道密码的钥匙。”
1. 导言:计算机不懂泰语
在多语言文本分析场景中,我们面临的第一个挑战是语言的巴别塔。
用户的抱怨五花八门:
- 英文: “Where is my package?”
- 泰文: “พัสดุอยู่ที่ไหน?”
- 印尼文: “Di mana paket saya?”
虽然字面完全不同,但它们的意思是一模一样的。
如果我们直接把这些字符串丢给聚类算法,算法会认为它们是完全不相关的东西。因为它只能看到字符 W-h-e-r-e 和 พ-ั-ส-ด-ุ 的区别。
我们需要一种通用语言,把所有人类的语言翻译成计算机能理解的数学语言。
这个过程,就是 文本表示 (Text Representation),或者更时髦的叫法——Embedding。
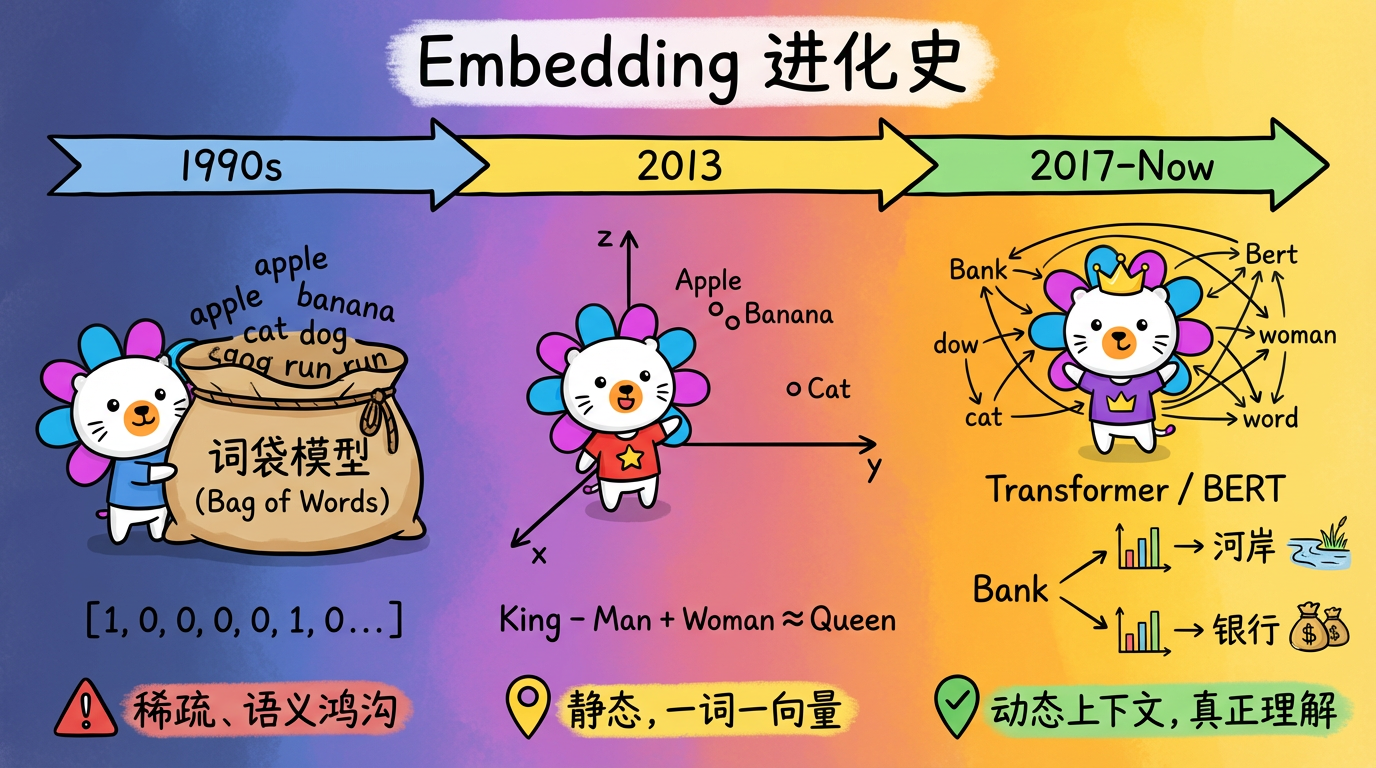
2. 核心概念:进化的三个阶段
文本表示技术经历了三个时代的跨越,每一次跨越都让机器离“理解”更近一步。
阶段一:词袋模型 (Bag of Words) —— 极其笨拙的翻译
这是最早期的做法。假设我们有一个词典 {'apple', 'banana', 'cat'}。
- 句子 “I have an apple” ->
[1, 0, 0](假设只关注关键词) - 句子 “I have a banana” ->
[0, 1, 0]
致命缺陷:
- 稀疏 (Sparse):词典可能有 10 万个词,你的向量就是 10 万维,全是 0。这极度浪费内存。
- 语义鸿沟:在数学上,
[1,0,0]和[0,1,0]是正交的(垂直的),没有任何相似性。但在现实中,苹果和香蕉都是水果,应该很相似才对。
阶段二:静态词向量 (Word2Vec) —— 捕捉到了语义
2013 年,Google 提出了 Word2Vec。它做了一件惊天动地的事:把词映射到低维稠密空间。
- Apple:
[0.8, 0.2, 0.1] - Banana:
[0.7, 0.3, 0.1] - Cat:
[-0.5, 0.1, 0.9]
在这个空间里,神奇的事情发生了:
- $\text{Apple} \approx \text{Banana}$ (向量距离很近)
- $\vec{King} - \vec{Man} + \vec{Woman} \approx \vec{Queen}$ (居然能做加减法!)
致命缺陷:
它是静态的。单词 “Bank” 在 “River Bank” (河岸) 和 “Bank Account” (银行) 中,用的是同一个向量。机器依然是个脸盲。
阶段三:动态上下文向量 (Transformer / BERT) —— 真正的理解
这是目前最先进的技术(也是大多数现代工业系统的选择)。
Transformer 模型(如 BERT, GPT)引入了 Self-Attention (自注意力机制)。
在生成向量时,它会看整句话。
- 当它看到 “River Bank” 时,它会给 “Bank” 一个代表【地理位置】的向量。
- 当它看到 “Bank Account” 时,它会给 “Bank” 一个代表【金融机构】的向量。
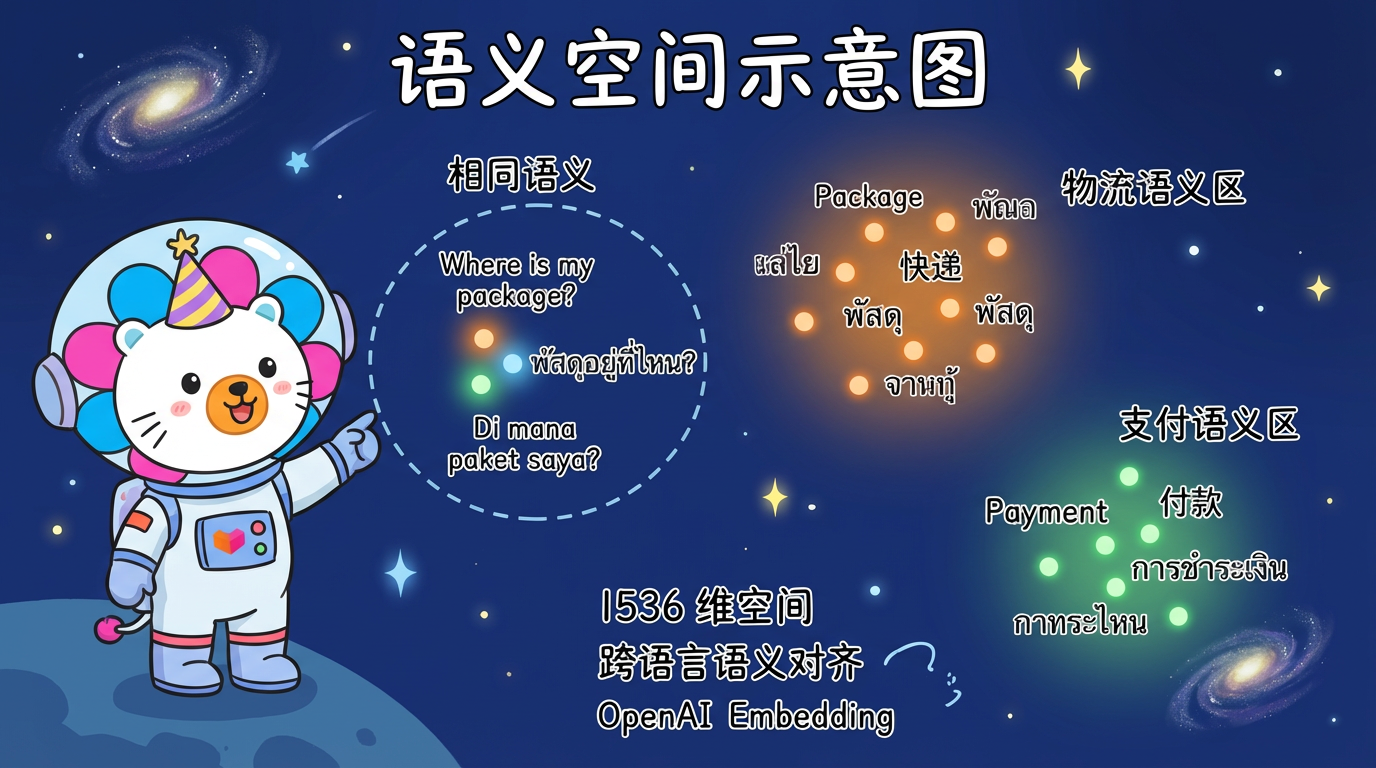
这就是为什么现代 Embedding 模型能听懂多国语言:
OpenAI 的 Embedding 模型经过了海量多语言语料的训练。它不仅理解了上下文,还理解了跨语言的对应关系。
- English “Package” 的向量 $\approx$ Thai “พัสดุ” 的向量。
- 在 1536 维的空间里,它们几乎重叠在一起。
3. 技术对比:主流 Embedding 方案
在工业界,选择哪种 Embedding 方案取决于你的钱包和需求。
| 方案 | 代表模型 | 优点 | 缺点 | 工业界常见选择 |
|---|---|---|---|---|
| 开源小模型 | BERT, RoBERTa | 免费,可私有化部署,速度快 | 维度低 (768),语义理解能力有限,多语言支持弱 | ❌ |
| 开源大模型 | E5, BGE (MTEB 榜单前列) | 效果极好,目前 SOTA | 需要昂贵的 GPU 显存,部署维护麻烦 | ❌ |
| 商业 API | OpenAI, Cohere, Google PaLM | 效果顶级,多语言无敌,无需运维 | 收费,数据隐私(需传云端) | ✅ |
决策思考:
对于需要处理小语种(如泰语、越南语、印尼语等)的项目,开源模型的支持通常较弱。而 OpenAI 的模型在多语言对齐上具有统治级优势。虽然要花钱,但相比于自己雇人清洗数据、训练模型的成本,调用 API 反而是最省钱的。
4. 代码实战:调用 OpenAI Embedding
在 cluster_analysis.py 中,我们封装了一个函数来获取向量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 通用实现:假设你有一个 API Key
import openai
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return openai.embeddings.create(input = [text], model=model).data[0].embedding
# 工业实践:使用 requests 库直接调用 REST API,并增加重试机制
def get_single_embedding_with_retry(session, text, index):
# ... (省略重试逻辑)
response = session.post(
f"{OPENAI_BASE_URL}/v1/embeddings",
json={
"model": "text-embedding-3-small", # OpenAI 的 Embedding 模型
"input": text
}
)
# 返回一个 list,长度为 1536
return result['data'][0]['embedding']得到的这个 [0.12, -0.45, ...] 长度为 1536 的数组,就是那句话的数字灵魂。
5. 实践要点
- 文本清洗:虽然 Transformer 很强,但不要给它喂垃圾。
- 去掉无意义的 HTML 标签 (
<br>,<div>)。 - 截断超长文本(OpenAI 通常限制 8191 tokens,但为了效果,建议只取前 512 个 token)。
- 去掉无意义的 HTML 标签 (
- 加权策略:
- 在实际项目中,可以把
category(分类) 字段重复拼接到description前面。 "Logistics | Logistics | Package lost"- 这就相当于告诉 Attention 机制:“嘿,这是物流相关的,请重点关注物流这个词!”这是一种隐式的特征加权。
- 在实际项目中,可以把
- 缓存 (Caching):
- API 是要钱的!而且很慢!
- 务必把跑过的文本 Hash 一下,存到本地文件里。下次跑同一句话,直接读缓存,别再调 API 了。这是降低成本的关键策略。
下一章预告:
现在我们手里有了一堆向量。
我们该如何判断两个向量是不是“相似”的?是用尺子量距离?还是用量角器量角度?
在高维空间里,这可是个大问题。



