


“如果智能是一块蛋糕,无监督学习就是蛋糕胚,监督学习只是上面的糖霜。” —— Yann LeCun (图灵奖得主)
1. 导言:寻找数据的”潜规则”
想象一下,你是一个刚到地球的外星人,手里只有一堆没有任何标签的照片。没人告诉你什么是”猫”,什么是”狗”。但你依然可以通过观察发现:有些照片里的小动物长着尖耳朵、瞳孔竖直(我们将它归为 A 类);有些照片里的动物体型较大、伸着舌头(归为 B 类)。
你不知道它们叫什么,但你已经学会了区分它们。这就是 无监督学习 (Unsupervised Learning) 的本质:在没有老师教导的情况下,自我发现数据背后的结构和规律。
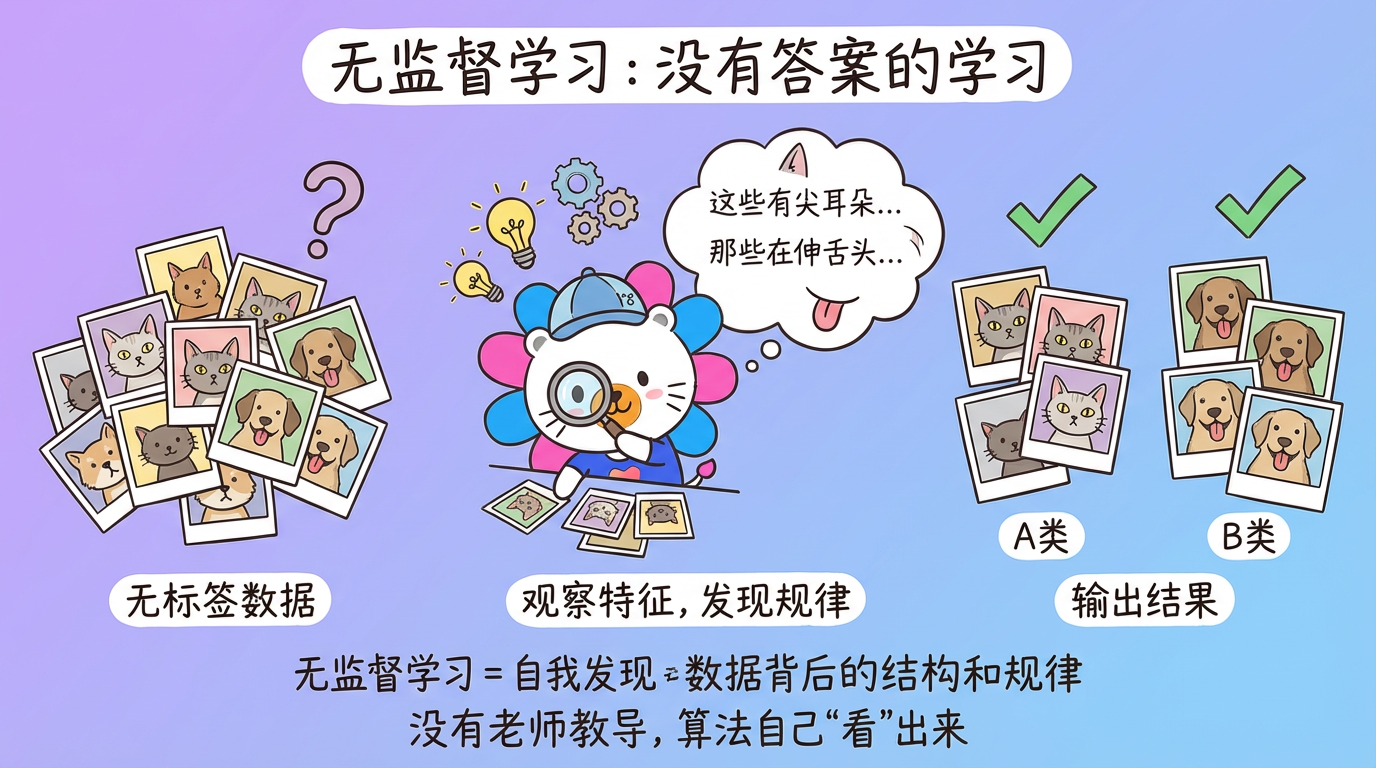
本章我们将推开这扇大门,看看在这个没有标准答案的世界里,算法是如何工作的。我们将以一个典型的工业场景——电商客服工单分析系统——作为案例,看看如何用无监督学习从海量用户抱怨中挖掘出未知的风险。
2. 核心概念:四大支柱
无监督学习并非单一的技术,而是支撑现代 AI 的四根支柱。
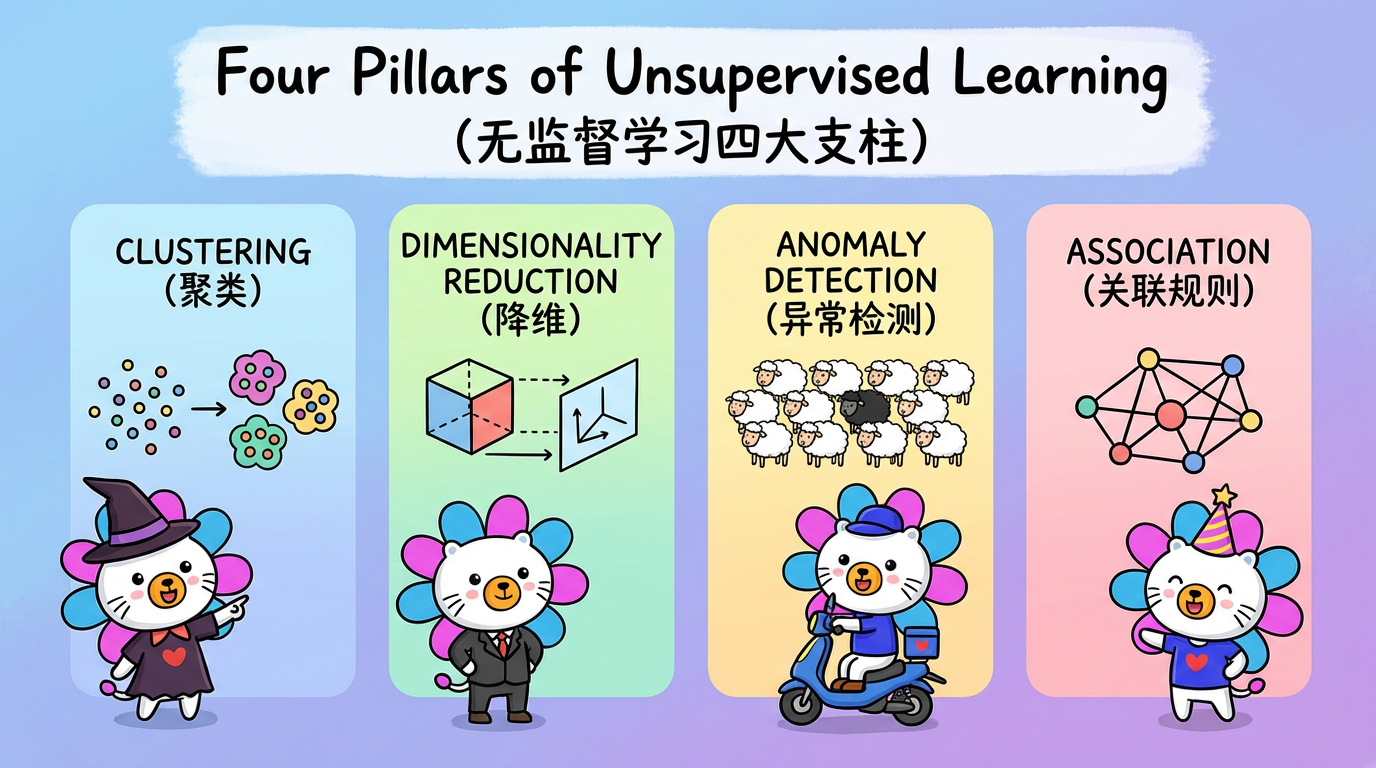
2.1 聚类 (Clustering):物以类聚
这是最直观的任务。
- 任务:将相似的数据归为一堆。
- 例子:新闻网站自动将”姆巴佩转会”和”皇马引援”归为【体育新闻】,将”美联储加息”归为【财经新闻】。
- 实际应用:在电商客服场景中,可以将数万条杂乱无章的工单(”快递慢”、”不发货”、”态度差”)自动聚成 80 个特定的业务场景簇,帮助运营团队快速识别主要问题。
2.2 降维 (Dimensionality Reduction):化繁为简
现实世界是高维的,但人类的理解力是低维的。
- 任务:在保留主要信息的前提下,减少数据的变量数量。
- 例子:用一张二维的地球投影图来表示三维的地球。虽然有变形,但我们能看清七大洲的位置关系。
- 实际应用:在文本分析中,可以将 1536 个维度的复杂语义向量,压缩到 2 维平面上,绘制出直观的可视化图表,让业务人员能够一眼看出数据的分布模式和聚集区域。
2.3 异常检测 (Anomaly Detection):寻找黑羊
在一群白羊中,那只黑羊是如此显眼。
- 任务:识别出与大众格格不入的数据点。
- 例子:银行的风控系统。绝大多数刷卡都是几十块几百块,突然有一笔凌晨 3 点在异国他乡的 5 万块消费,这就是异常。
- 实际应用:在客服工单分析中,可以利用异常检测发现全新的问题类型(如突然出现的产品缺陷投诉、罕见的配送事故等),这类问题从未大量出现过,因此在数据空间中显得极度稀疏和离群,但往往代表着需要紧急关注的风险信号。
2.4 关联规则 (Association):隐形连接
- 任务:发现数据项之间的共现关系。
- 经典案例:沃尔玛发现买了啤酒的男性通常也会买尿布。
- 注意:在深度学习时代,这一任务逐渐被 Embedding 技术(计算向量相似度)所吸纳。
3. 典型应用场景:多语言客服工单分析
为了避免枯燥的理论堆砌,我们将以一个典型的工业场景为例进行分析。
场景设定:
一个跨国电商平台每天会收到数百万条来自多个国家、使用多种语言的客服工单。
业务挑战:
运营人员想知道:”最近发生了什么?”
- 如果用监督学习(分类器),你必须先定义好类别(如”物流”、”支付”)。但如果明天突然出现了一个新问题(如”App 闪退”),分类器就瞎了,因为它没学过这个类别。
- 无监督学习是唯一的出路。我们不预设任何类别,把所有工单丢进算法的熔炉,让算法告诉我们:”老板,最近有一大波人在讨论’验证码收不到’,这似乎是个新问题。”
4. 技术栈概览
在开始深入之前,让我们先鸟瞰一下我们将要学习的武器库。
| 环节 | 传统方法 (统计学派) | 现代方法 (深度学习派) | 工业界常见选择 |
|---|---|---|---|
| 数据表示 | 词袋模型 (Bag of Words) | Embedding (Transformer) | Embedding (第2章) |
| 距离度量 | 欧氏距离 | 余弦相似度 | 余弦相似度 (第3章) |
| 降维 | PCA | UMAP, t-SNE | UMAP (第13章) |
| 聚类 | K-Means, GMM | Deep Clustering | K-Means (第5章) |
| 解释 | 人工看关键词 | LLM (大语言模型) | LLM (第18章) |
你会发现,现代工业系统通常采用一套混合架构:用最先进的深度学习做特征提取(Embedding)和解释(LLM),但中间的计算环节却回归了经典的统计学算法(K-Means, UMAP)。
为什么?
这是一个非常深刻的工程哲学:用重模型(AI)做感知,用轻模型(数学)做逻辑。
深度学习虽然强大,但它像个黑盒。而 K-Means 这种数学算法,简单、透明、可控。在工业界,可控性往往比那 1% 的精度提升更重要。
5. 动手时刻:你的第一个无监督模型
别光听不练。让我们用几行 Python 代码,体验一下无监督学习的魔法。
我们将生成两堆随机数据,假装不知道它们的标签,看看 K-Means 能不能把它们找回来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# 1. 上帝视角:生成数据
# 我们生成了 300 个点,隐式地分为 4 堆
X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 2. 凡人视角:无监督学习
# 假装我们不知道 y_true,只把 X 丢给算法
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
# 3. 见证奇迹
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5)
plt.title("K-Means 自动发现的 4 个簇")
plt.show()运行这段代码,你会看到算法准确地给数据涂上了四种颜色。没人告诉它哪是哪,它自己”看”出来的。
下一章预告:
数据挖掘的第一步是把现实世界变成数字。在多语言文本分析中,最大的挑战是:如何把不同语言的文本(如泰语、越南语、英语的抱怨),都变成计算机能理解和比较的数字?
这将引出 NLP 领域最伟大的发明之一:Embedding。



