


“在数据可视化的世界里,t-SNE 就是那个把乱麻理顺的魔术师。”
如果你在 Kaggle 上看过别人的 Kernel,你一定见过那种把 MNIST 手写数字完美分成 10 堆彩色小岛的图。
这种令人惊叹的“分堆”效果,90% 都是 t-SNE (t-分布随机邻域嵌入) 的功劳。
它不是在做数学投影(像 PCA 那些线性代数游戏),而是在做概率匹配。它强迫低维空间中的点,必须模仿高维空间中的社交关系。
本章我们将深入这个稍微有点复杂的算法内部,掰开揉碎了讲讲它是如何利用“学生 t 分布”来解决拥挤问题的。
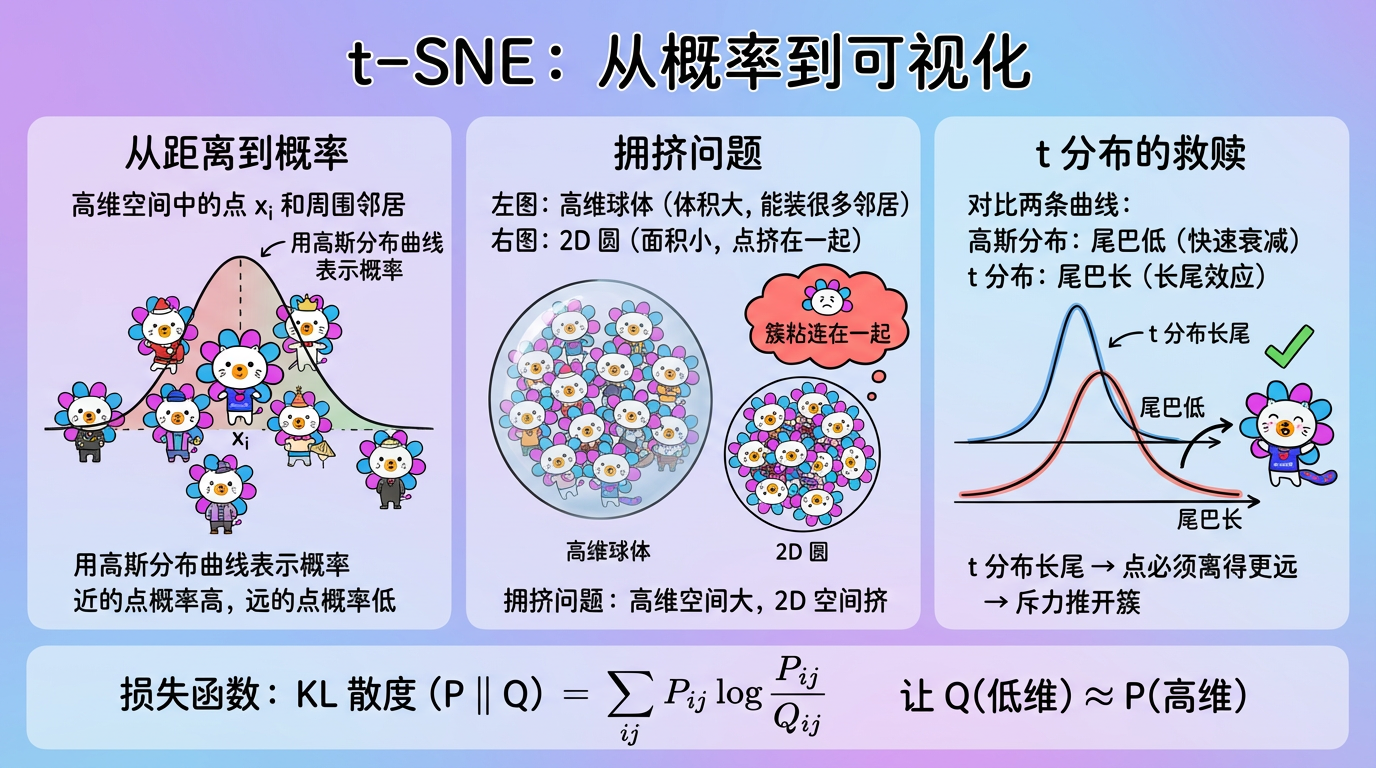
(图注:上图是高维空间,下图是低维空间。t-SNE 通过梯度下降,不断移动下图中的点,让两边的“邻居关系”尽可能一致。)
1. 第一步:高维空间的社交圈 (SNE)
首先,我们要量化在高维空间里,谁和谁是邻居。t-SNE 说:别算死板的距离了,算概率吧。
1.1 条件概率:选邻居
对于点 $x_i$,它选择 $x_j$ 作为邻居的概率 $p_{j|i}$ 是多少?
这取决于 $x_j$ 离它有多近。t-SNE 假设这种关系服从高斯分布(正态分布)。
$$ p_{j|i} = \frac{\exp(-||x_i - x_j||^2 / 2\sigma_i^2)}{\sum_{k \neq i} \exp(-||x_i - x_k||^2 / 2\sigma_i^2)} $$
- 分子:距离越近 ($||x_i - x_j||$ 小),指数值越大,概率越高。
- 分母:所有其他点对 $x_i$ 的“吸引力”总和。这是一个归一化项,确保所有概率加起来等于 1。
- 直觉:这就像你在派对上选朋友。你选 $x_j$ 的概率,取决于他离你有多近,以及派对上有多少其他人(分母)。
1.2 动态半径:$\sigma_i$ 的秘密
公式里有个 $\sigma_i$,它是每个点独有的方差。这意味着每个点都有自己的“社交半径”。
- 稠密区域(市中心):周围人很多。$\sigma_i$ 会自动变小。只关注身边 1 米的人,远一点的都不算邻居。
- 稀疏区域(郊区):周围没几个人。$\sigma_i$ 会自动变大。哪怕离我 10 米远的人,也算我的邻居(因为没别的选择了)。
这种自适应密度的能力,是 t-SNE 优于 PCA 的关键原因之一。它是通过二分查找来确定的,目标是满足用户设定的 Perplexity(困惑度)。
2. 第二步:低维空间的模仿秀
现在,我们在 2D 屏幕上随机撒一堆点 $y_i$。我们要让这些 $y$ 模仿 $x$ 的社交关系。
2.1 长尾分布:为什么要用 t 分布?
在低维空间,我们不用高斯分布了,改用学生 t 分布 (Student’s t-distribution)(自由度为 1 的 t 分布,也就是柯西分布)。
公式长这样:
$$ q_{ij} = \frac{(1 + ||y_i - y_j||^2)^{-1}}{\sum_{k \neq l} (1 + ||y_k - y_l||^2)^{-1}} $$
为什么要换?(这是 t-SNE 的灵魂!)
这就是为了解决著名的 拥挤问题 (Crowding Problem)。
- 几何事实:在高维空间(比如 100 维),球的体积随着半径指数级增长,能容纳海量的邻居。但在 2D 平面上,圆的面积增长很慢,根本挤不下那么多邻居。
- 后果:如果低维也用高斯分布,中等距离的点会没地方站,只好被迫挤在中心,导致所有簇都粘连成一团。
- t 分布的救赎:t 分布是长尾的(尾巴比高斯分布高)。
- 这意味着:为了表示同样的概率(同样的亲密度),t 分布允许点与点之间离得更远。
- 效果:这就像一种斥力。它把原本必须挤在一起的簇,强行推开了。并在簇与簇之间留出了明显的空白(Ghost Space)。
2.2 损失函数:KL 散度
我们要让低维概率 $Q$ 尽可能接近高维概率 $P$。衡量两个分布差异的标准工具是 KL 散度。
$$ C = KL(P || Q) = \sum_i \sum_j p_{ij} \log \frac{p_{ij}}{q_{ij}} $$
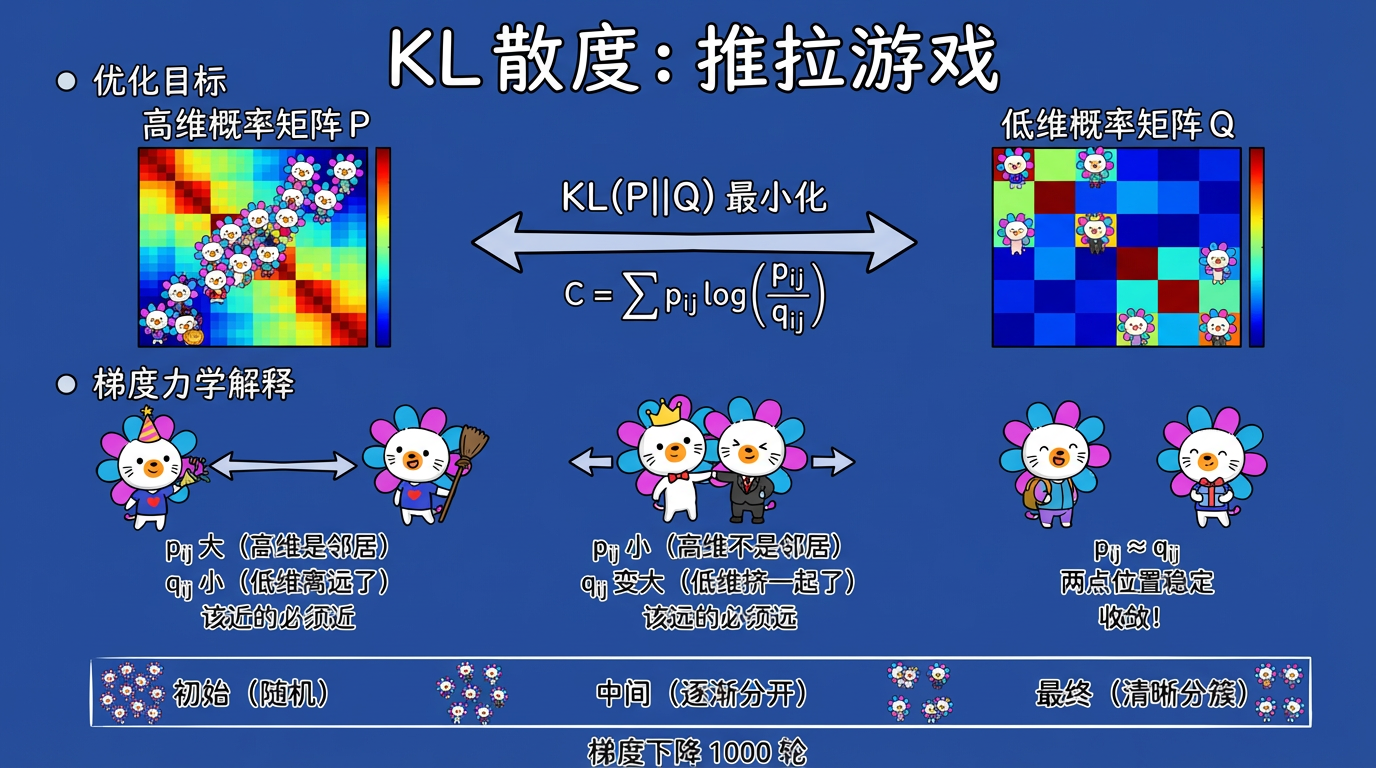
(图注:KL 散度驱动梯度下降,吸引力拉近邻居,排斥力推开非邻居。)
2.3 梯度下降:推拉游戏
t-SNE 的优化过程就是不断移动 $y_i$ 的位置。梯度的物理意义非常直观:
- 吸引力:如果 $p_{ij}$ 很大(原本是邻居)但 $q_{ij}$ 很小(现在离远了),梯度会把它们拉近。
- 排斥力:t 分布的长尾提供了一种自然的排斥力,防止大家挤在一起。
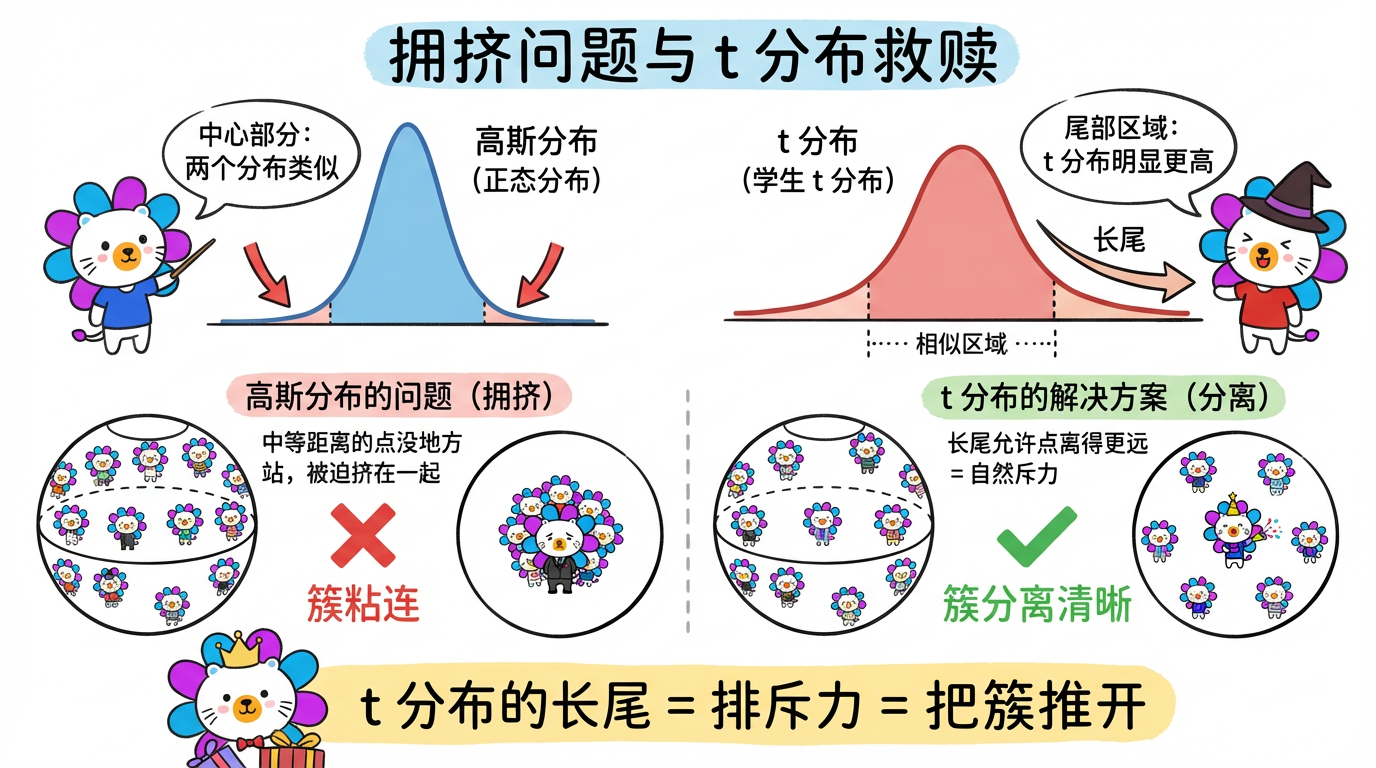
(图注:高斯分布导致簇粘连(左),t 分布的长尾提供斥力,把簇推开(右)。)
3. 关键参数:Perplexity (困惑度)
t-SNE 只有一个核心参数,但它至关重要,能决定图的生死:Perplexity。
它大致相当于“每个点应该关注多少个有效邻居”。
- Perplexity = 5:微观视角。每个点只在乎身边那几个人。结果:数据会碎成很多小块,像一盘散沙。
- Perplexity = 50:中观视角。每个点会看更远一点。结果:簇会更完整,甚至能看到一些全局形状。
- Perplexity = 100:宏观视角。开始关注全局结构。
经验法则:
- 通常设在 5 到 50 之间。
- 默认值 30 通常是个不错的起点。
- 对于大数据集(> 10万),设大一点(如 50-100)有助于保持全局结构。
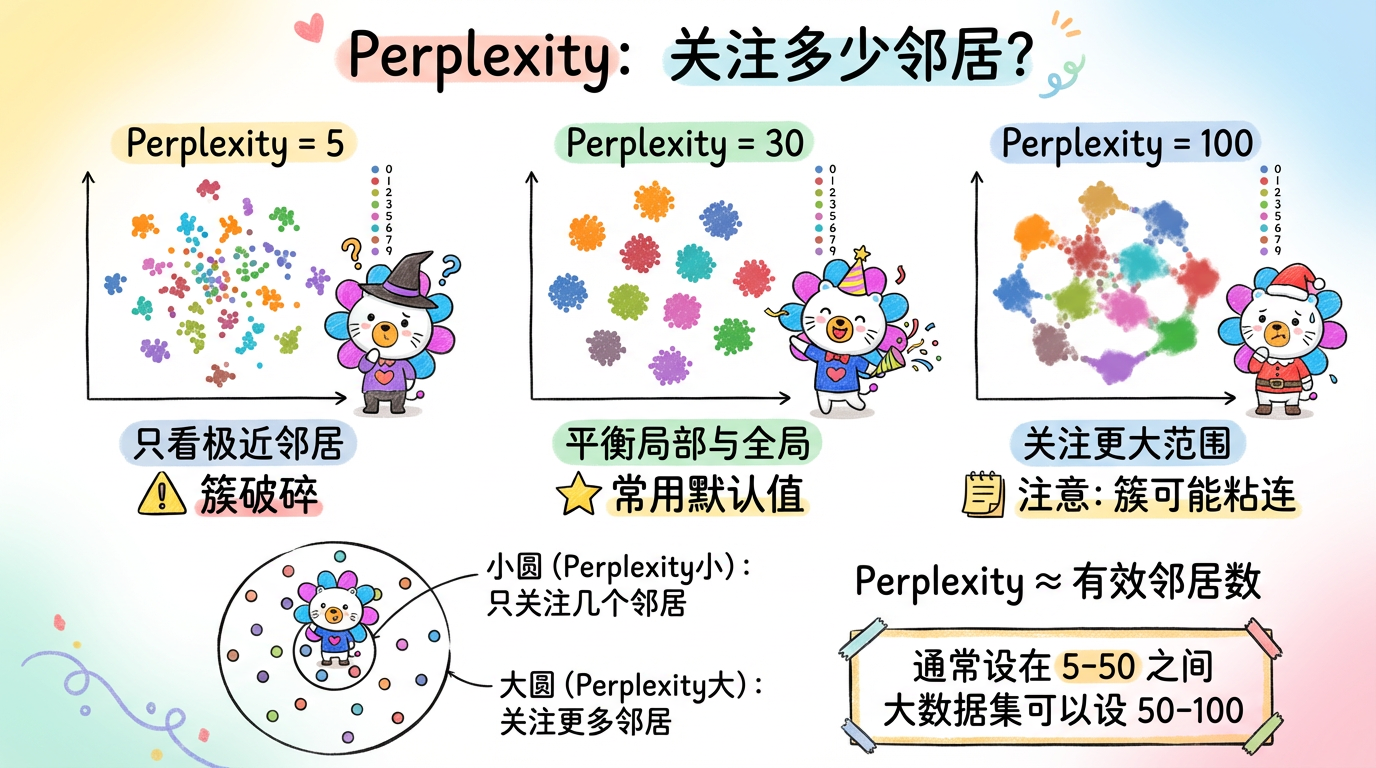
(图注:左图 Perplexity=2,簇支离破碎;右图 Perplexity=30,数字 0-9 分得清清楚楚。)
4. 技术对比:t-SNE 的阿喀琉斯之踵
虽然 t-SNE 效果惊艳,但它有几个致命弱点,这也是为什么后来 UMAP 能挑战它的原因。
| 特性 | PCA | t-SNE | 评价 |
|---|---|---|---|
| 原理 | 线性投影 | 非线性概率匹配 | t-SNE 更强力 |
| 全局结构 | 保持极好 | 丢失 | t-SNE 图上的簇间距离没有意义。相隔很远的两个簇,可能在高维空间是挨着的。 |
| 局部结构 | 一般 | 极好 | t-SNE 擅长把同一类分在一起。 |
| 确定性 | 确定 | 随机 | 每次跑结果都不一样,必须固定 random_state。 |
| 速度 | 极快 | 慢 | 即使有 Barnes-Hut 加速,跑 10 万数据也要好久。 |
| 新数据 | 可以 Transform | 无法直接 Transform | 这是最大痛点。来了新数据,必须把旧数据加进去重新跑一遍。无法用于线上实时推断。 |
5. 代码实战:手写数字可视化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
from sklearn import datasets
from sklearn.manifold import TSNE
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import time
# 1. 加载手写数字数据 (1797 张图片,64 维)
digits = datasets.load_digits()
X = digits.data
y = digits.target
print(f"原始维度: {X.shape}")
# 2. 预处理 (强烈推荐!)
# t-SNE 在高维数据上计算距离很慢,且容易受噪声影响。
# 先用 PCA 降到 50 维,既去噪又加速。
print("正在进行 PCA 降维...")
X_pca = PCA(n_components=50).fit_transform(X)
# 3. 运行 t-SNE
# init='pca': 用 PCA 结果初始化,而不是随机初始化。
# 这能让 t-SNE 收敛更快,且保留更多全局结构,结果更稳定。
print("正在运行 t-SNE...")
start_time = time.time()
tsne = TSNE(n_components=2, perplexity=30, init='pca', random_state=42)
X_tsne = tsne.fit_transform(X_pca)
print(f"t-SNE 耗时: {time.time() - start_time:.2f} 秒")
# 4. 绘图
plt.figure(figsize=(10, 8))
# 使用 tab10 调色板,区分 10 个数字
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='tab10', alpha=0.6, s=10)
plt.legend(*scatter.legend_elements(), title="Digits")
plt.title("t-SNE visualization of MNIST Digits")
plt.axis('off') # t-SNE 的坐标轴刻度没有意义,关掉它
plt.show()6. 实践避坑指南
- 别信簇间距离:千万别看着图说:“簇 A 和簇 B 离得远,说明它们很不相似。” 不一定!可能只是 t-SNE 为了把它们分开,随机推到了两边。
- 别信簇的大小:t-SNE 会膨胀密集的簇,收缩稀疏的簇。图上两个簇看起来一样大,实际上密度可能差 100 倍。
- 先降维:如果你的特征超过 50 维(比如本项目的 1536 维),千万别直接跑 t-SNE。先用 PCA 降到 50 维,效果更好且速度更快。
- 学习率 (Learning Rate):通常在 [10, 1000] 之间。如果图看起来像一个球,可能是学习率太大了;如果点都挤在一起,可能是学习率太小了。
下一章预告
t-SNE 虽好,但太慢了,而且它只能做“事后分析”(可视化),不能做“在线服务”(因为不能 transform 新数据)。
有没有一种算法,既能像 t-SNE 一样分堆,又能像 PCA 一样保持全局关系,速度快,还支持 transform?
有。它就是降维界的新皇——UMAP。



