
第 08 章:概率模型聚类
“上帝不掷骰子,但数据科学家掷。” —— 改编自爱因斯坦
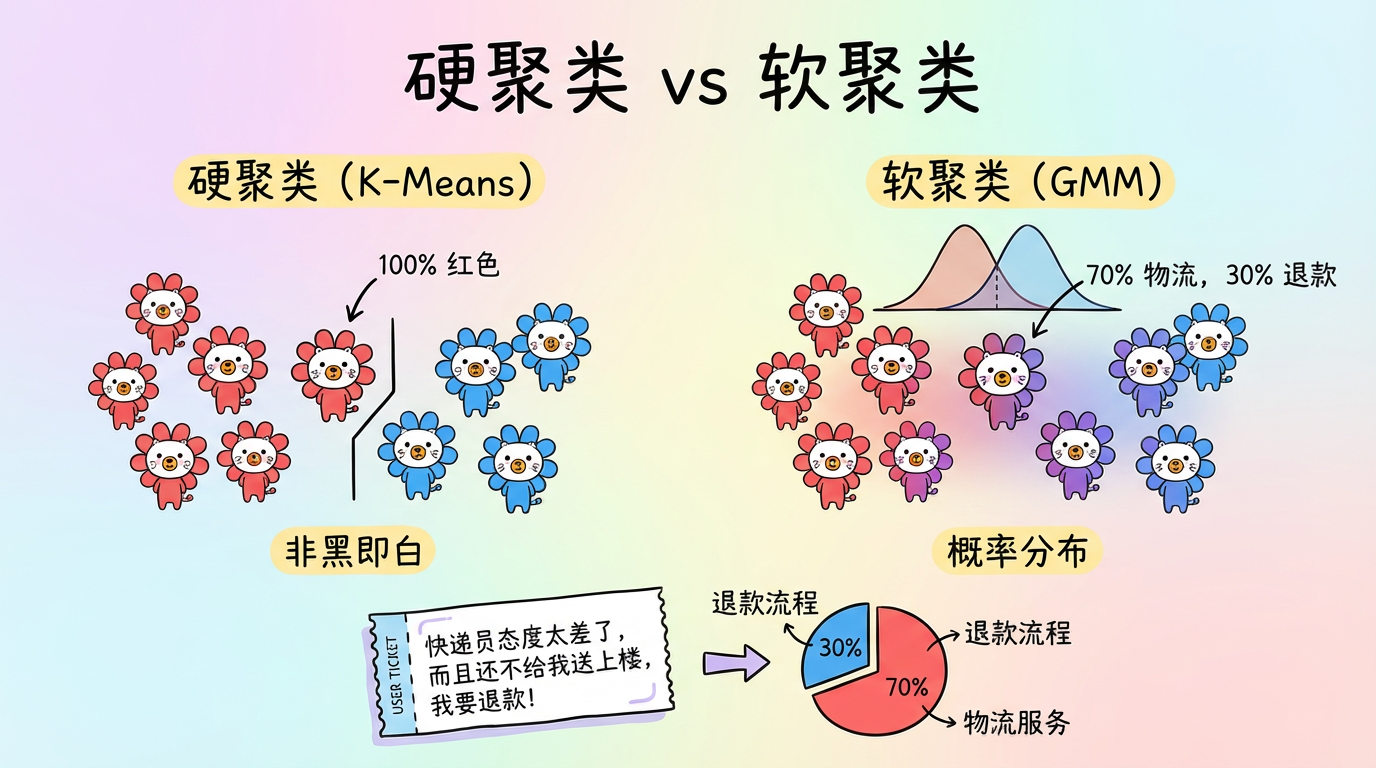
之前的聚类算法(K-Means, DBSCAN)都有一个共同特征:硬聚类 (Hard Clustering)。
一个样本要么属于 A,要么属于 B,没有中间地带。
这就像把人简单分为“好人”和“坏人”,丢失了人性的复杂灰度。
在实际的文本分析场景中,我们经常遇到这种情况:
用户工单:”快递员态度太差了,而且还不给我送上楼,我要退款!”
这句话既涉及【物流服务】,又涉及【退款流程】。如果硬把它归为某一类,就会丢失另一半信息。
本章我们将介绍 高斯混合模型 (GMM, Gaussian Mixture Model),它引入了 软聚类
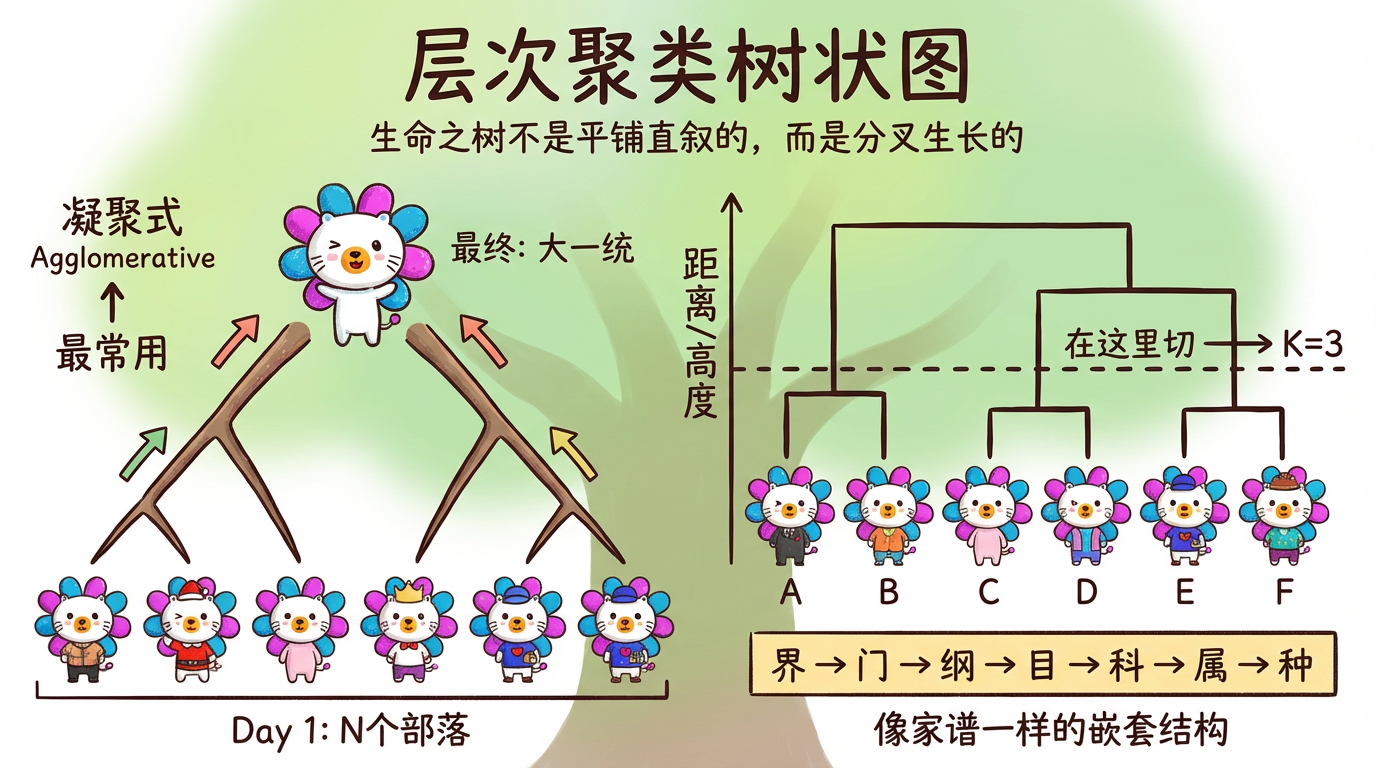
第 07 章:层次聚类
“生命之树不是平铺直叙的,而是分叉生长的。”
K-Means 给了我们一张扁平的地图:这一块是中国,那一块是美国。在地图上,北京和上海是平级的城市。
但生物学家看世界的眼光不一样。他们会给你画一棵树:
* 所有动物 -> 脊索动物 -> 哺乳动物 -> 食肉目 -> 猫科 -> 家猫。
这种层层嵌套的结构,往往比扁平的分组包含了更丰富的信息。比如,我们不仅想知道“这个客户属于高价值客户”,我们可能还想知道“在高价值客户里,他又属于偏爱理财的那一小撮”。
本章我们将介绍 层次聚类 (Hierarchical Clustering)。它不需要你痛苦地纠结 K 到底是 5 还是 6。它会
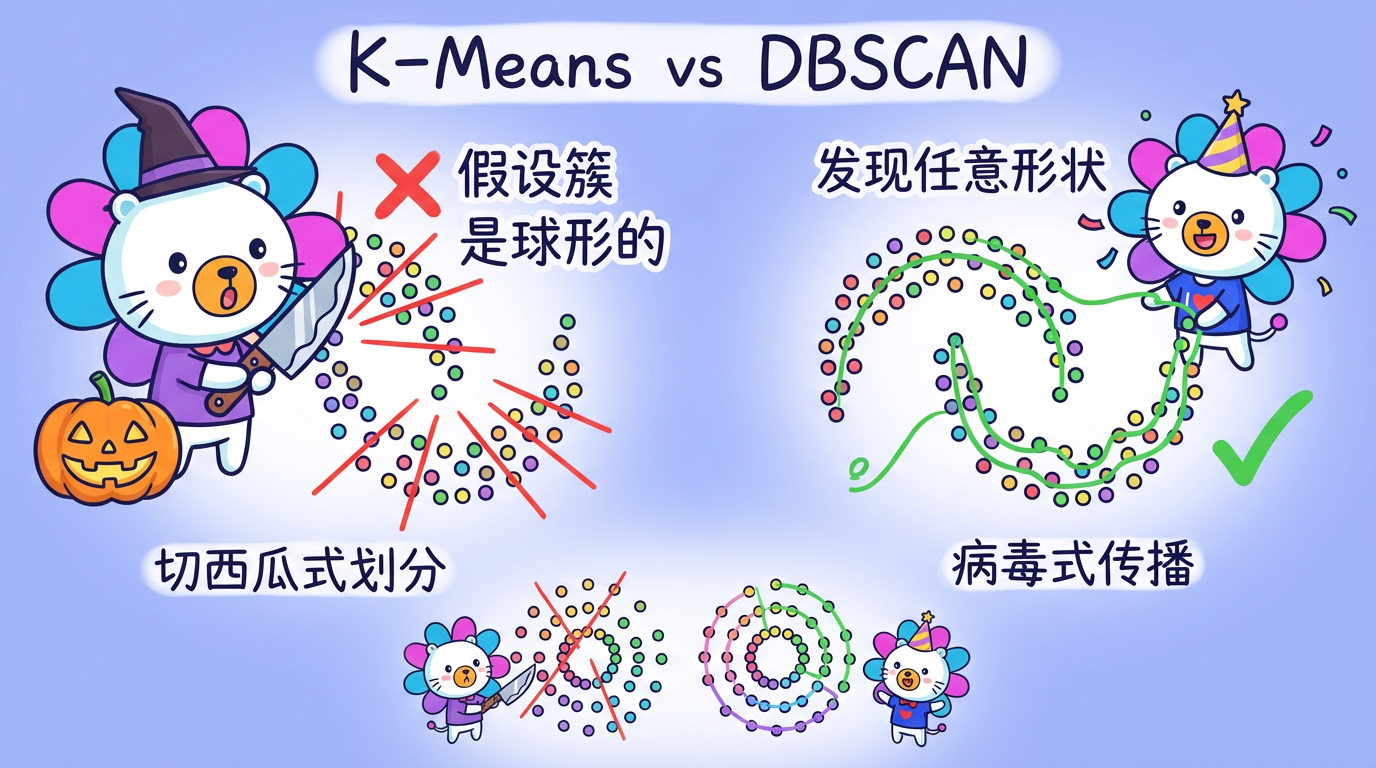
第 06 章:密度聚类
“在拥挤的城市里,社区是由密度定义的,而不是由圆心定义的。”
想象一下,你站在上海的人民广场或者纽约的时代广场。你怎么判断哪些人是一伙的?
K-Means 算法像是一个拿着圆规的管理员。它假设大家都是以某个中心站成一个个圆圈。如果一群人排成了长长的贪吃蛇队伍(非凸形状),或者环绕着喷泉站成了一个甜甜圈形状,K-Means 就彻底傻眼了——它会强行把“贪吃蛇”切成几段,或者把“甜甜圈”切成几块蛋糕。
但在现实世界中,数据的形状千奇百怪。有些客户群体像细长的河流(比如随着时间推移的特定行为模式),有些像紧密的蜂巢。
本章我们将介绍 DBSCAN,一种基于密度的聚类算法。它不需要你预先告诉它
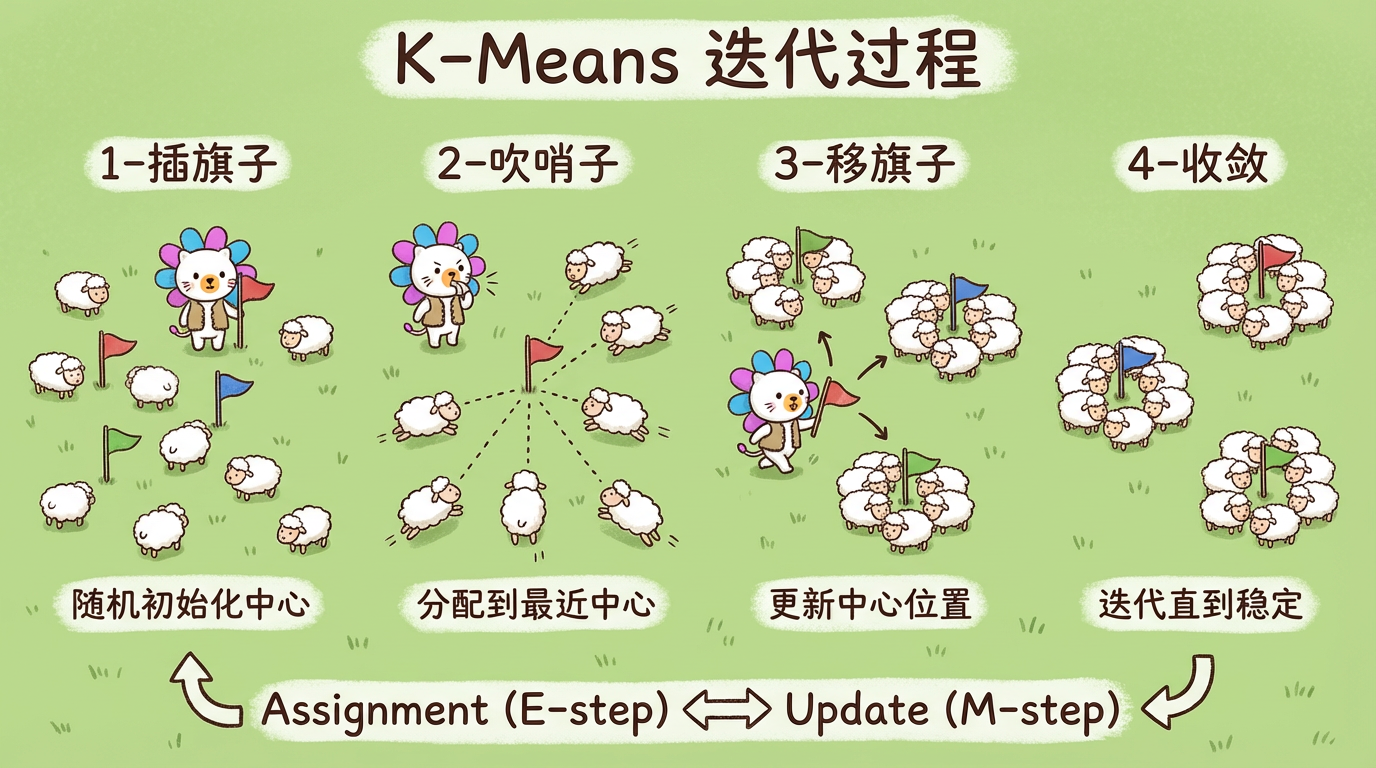
第 05 章:划分式聚类
“虽然它诞生于 1957 年,但它依然是数据挖掘界的 AK-47——简单、粗暴、有效。”
1. 导言:牧羊人的智慧
如果把你扔到一个大草原上,给你 1000 只羊,让你把它们分成 3 群,你会怎么做?
你可能会插 3 根旗子,然后吹哨子让羊跑到离自己最近的旗子那里去。
然后你发现,某个旗子插歪了,羊群并不集中。于是你拔起旗子,走到羊群的中心重新插下。
再吹哨子,羊群微调位置。
重复几次,羊群就分得整整齐齐了。
这就是 K-Means 算法的直觉:选中心 -> 分组 -> 移中心 -> 再分组。
这种将数据划分为互不重叠的子集的方法,称为 划分式聚类 (Partitional Cluster
第 04 章:高维数据的几何特性
“在高维空间里,每个人都是孤独的。”
欢迎来到 1536 维的世界。这里是 Embedding 的家园,也是直觉的坟墓。
我们的大脑是为三维世界进化的。我们很难想象,当维度增加到 1000 以上时,几何规则会发生怎样翻天覆地的变化。
这一章我们将揭示一个可怕的现象——维度灾难 (The Curse of Dimensionality),以及一个美好的奇迹——维度祝福。
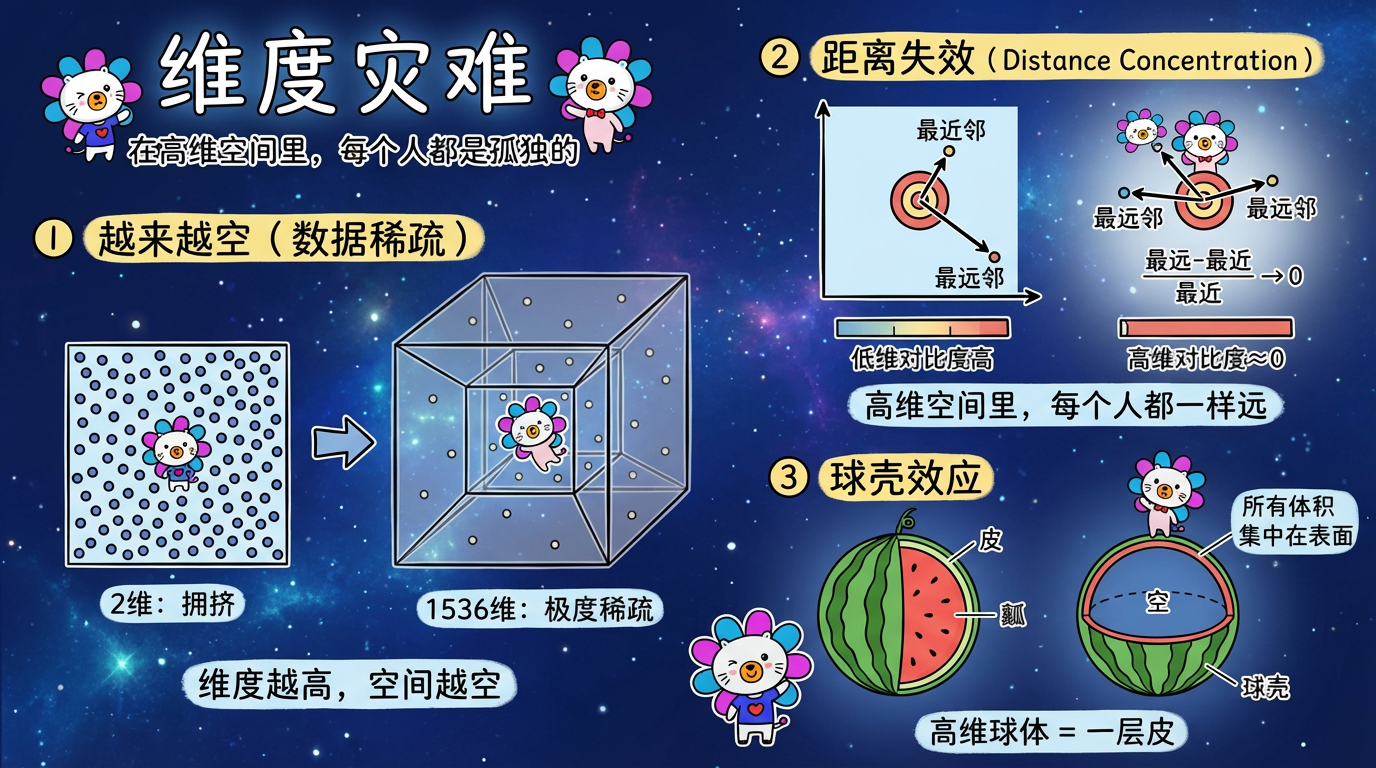
1. 维度灾难:空旷的宇宙
1.1 越来越空
想象一个边长为 1 的正方形(2维)。如果你往里面撒 100 个点,它会显得很拥挤。
现在,保持边长为 1,把它变成一个 1536 维的超立方体。
虽然边长没变,但它的“体
第 03 章:相似度与距离度量
“如果不定义‘近’,我们就无法定义‘类’。”
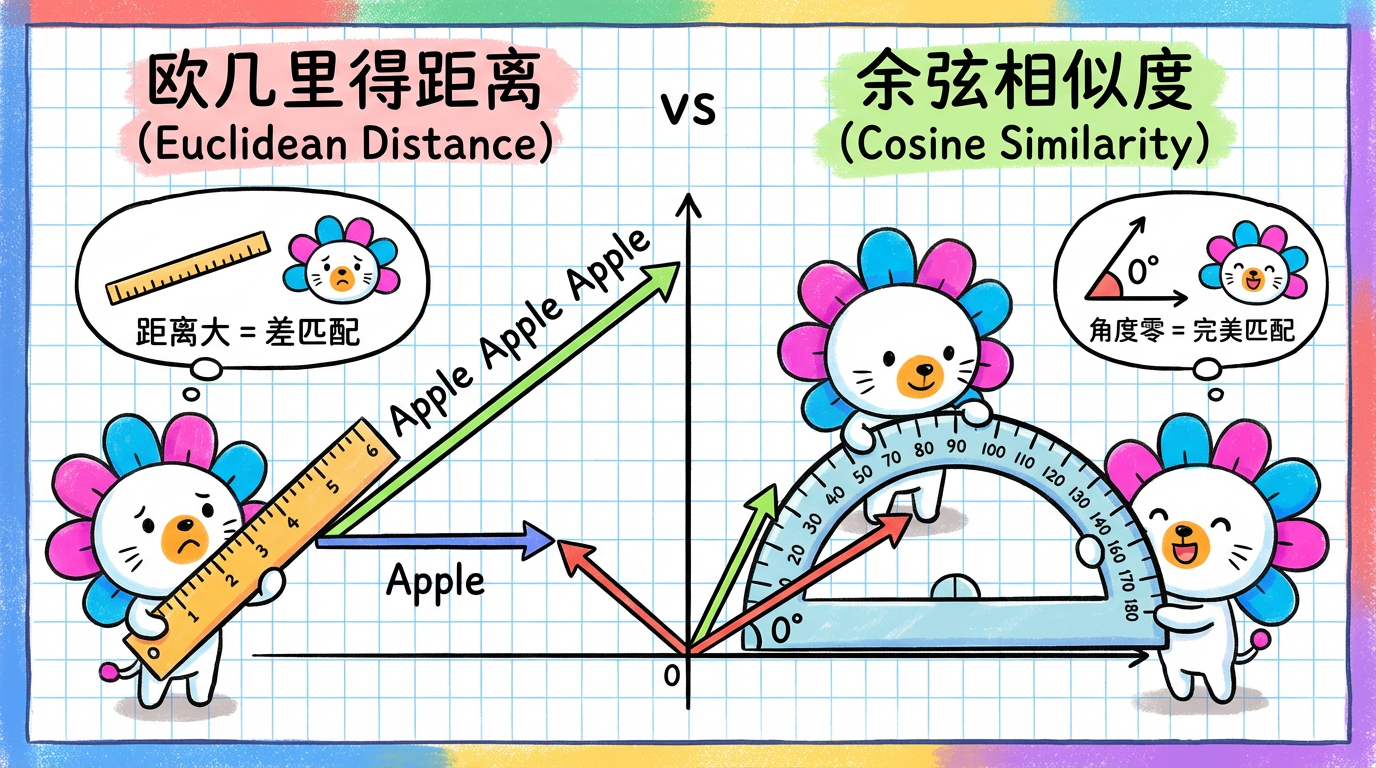
在第 2 章中,我们成功把“投诉”变成了“向量”。
现在,文本分析系统面临一个核心问题:如何判断两条投诉是不是在说同一件事?
* A: “My package is lost.” (向量 $v_A$)
* B: “I haven’t received my item.” (向量 $v_B$)
我们需要一把数学“尺子”来量一量 $v_A$ 和 $v_B$ 之间的距离。
距离越近 $\rightarrow$ 越相似 $\rightarrow$ 应该聚为一类。
但是,数学世界里有无数种尺子。用哪一把?这决定了聚类的生死。
1. 核心概念
第 02 章:文本表示学习:从词袋到Transformer
“语言是人类思想的密码,Embedding 是解开这道密码的钥匙。”
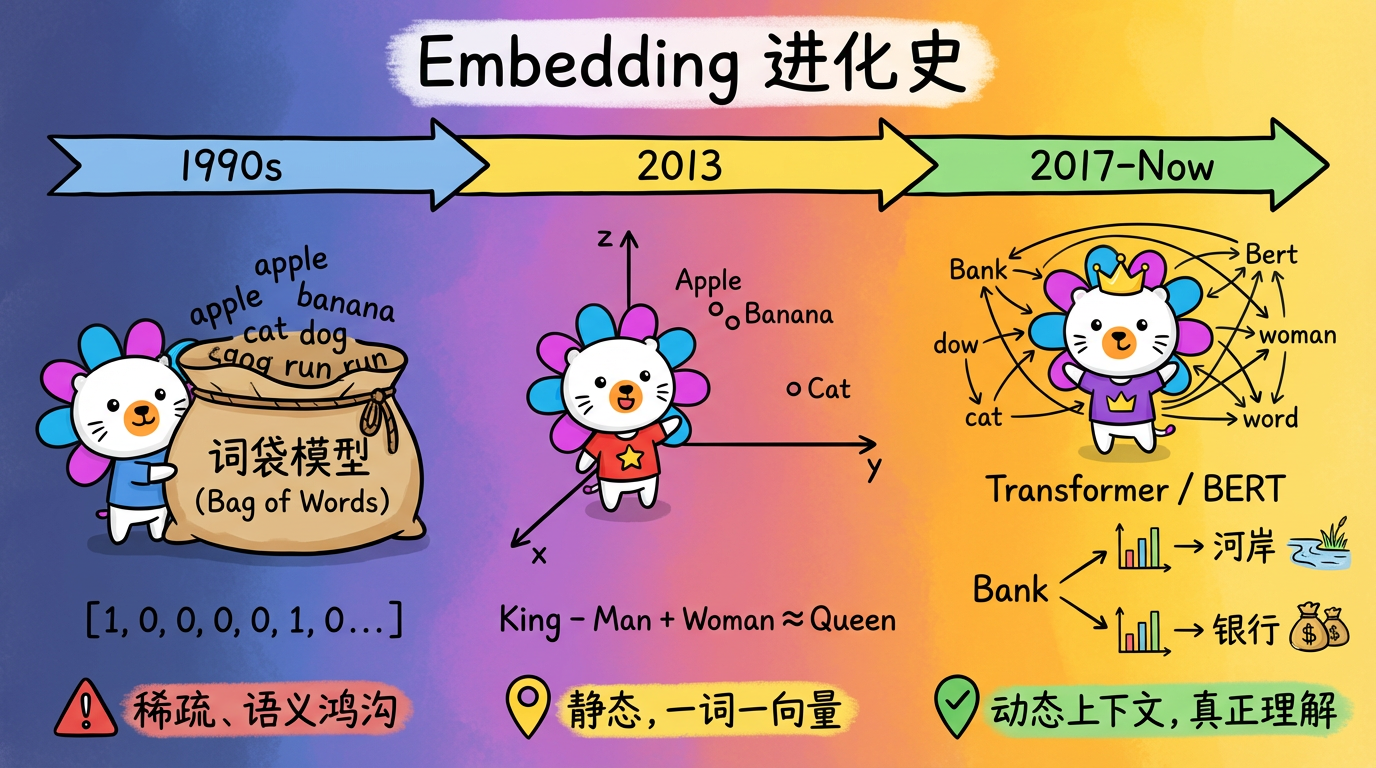
1. 导言:计算机不懂泰语
在多语言文本分析场景中,我们面临的第一个挑战是语言的巴别塔。
用户的抱怨五花八门:
* 英文: “Where is my package?”
* 泰文: “พัสดุอยู่ที่ไหน?”
* 印尼文: “Di mana paket saya?”
虽然字面完全不同,但它们的意思是一模一样的。
如果我们直接把这些字符串丢给聚类算法,算法会认为它们是完全不相关的东西。因为它只能看到字符 W-h-e-r-e 和 พ-ั-ส-ด-ุ 的区别。
我们需要一种通用语言,把所有人类的语言翻译成计
第 01 章:无监督学习导论
“如果智能是一块蛋糕,无监督学习就是蛋糕胚,监督学习只是上面的糖霜。” —— Yann LeCun (图灵奖得主)
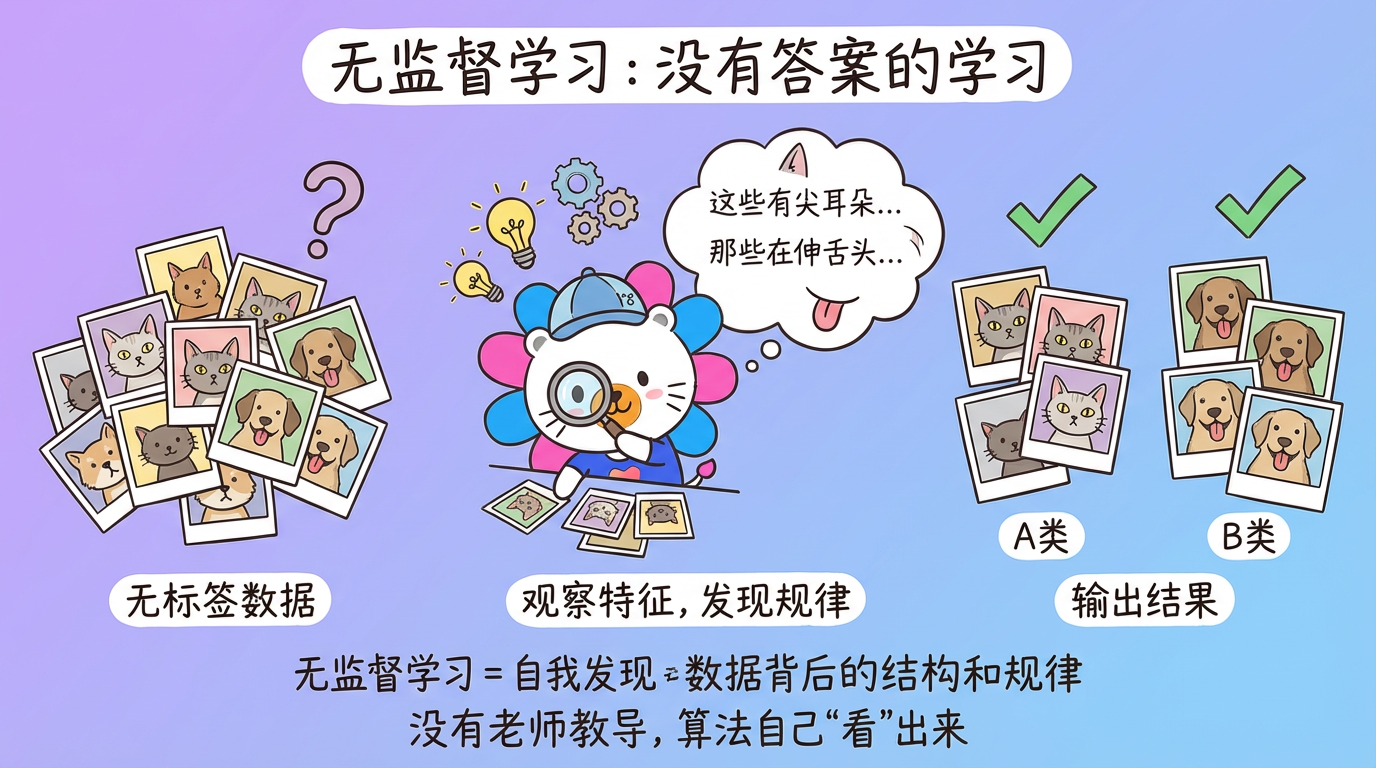
1. 导言:寻找数据的”潜规则”
想象一下,你是一个刚到地球的外星人,手里只有一堆没有任何标签的照片。没人告诉你什么是”猫”,什么是”狗”。但你依然可以通过观察发现:有些照片里的小动物长着尖耳朵、瞳孔竖直(我们将它归为 A 类);有些照片里的动物体型较大、伸着舌头(归为 B 类)。
你不知道它们叫什么,但你已经学会了区分它们。这就是 无监督学习 (Unsupervised Learning) 的本质:在没有老师教导的情况下,自我发现数据背后的结构和规律。
本章我们将推开



