

第 11 章:非线性降维基础
“地球是圆的,但地图是平的。把球面画成平面的过程,就是流形学习。”
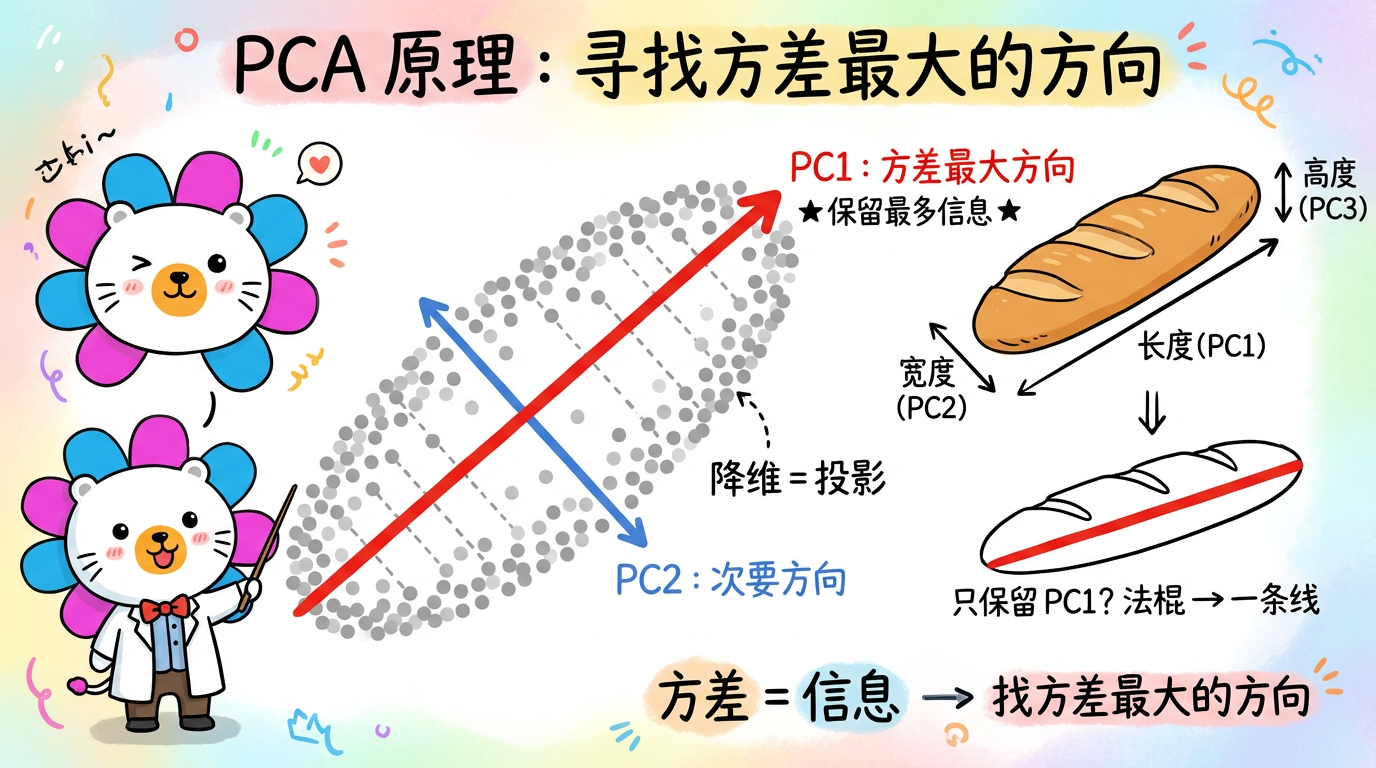
PCA 假设数据分布在一个平坦的超平面上。但现实世界的数据往往是卷曲的、扭曲的。
经典的例子是 “瑞士卷” (Swiss Roll) 数据集。数据像一块卷起来的地毯。
如果你直接用 PCA 从侧面压扁它(线性投影),原本相隔很远的两层会叠在一起,红色的点和蓝色的点就混淆了。这就叫投影混叠。
我们需要把这个卷小心翼翼地展开,就像把地毯铺平一样。这叫 流形学习 (Manifold Learning)。
1. 核心概念:流形假设 (Manifold Hypothesis)
流形学习基于一个大胆的假设:
虽然数据看起来维数
第 10 章:线性降维:PCA
“最好的数据压缩算法,不是 zip,而是理解数据的结构。”
我们生活在一个高维数据爆炸的时代。
* 图像:一张 100x100 像素的小头像,如果展平,就是 10,000 维的向量。
* 文本:一段包含 512 个 token 的文本,如果用 Embedding 表示,通常是 768 维或 1536 维。
* 用户画像:一个电商用户的特征,可能包含点击历史、购买力、地理位置等几千个指标。
在这些成千上万的维度中,往往充斥着冗余(比如“出生年份”和“年龄”完全相关)和噪声(比如图片边缘的随机噪点)。
降维 (Dimensionality Reduction) 的目标很简单:去粗取精。
第 09 章:聚类评估方法
“没有标准答案的考试,该怎么评分?”
在监督学习(如猫狗分类)中,评估很简单:你猜对了多少个?Accuracy = 95%。
但在无监督学习中,我们没有 Ground Truth(真实标签)。
机器把数据分成了 3 堆,你怎么知道分得对不对?也许实际上应该是 4 堆?或者那两个点不该在一起?
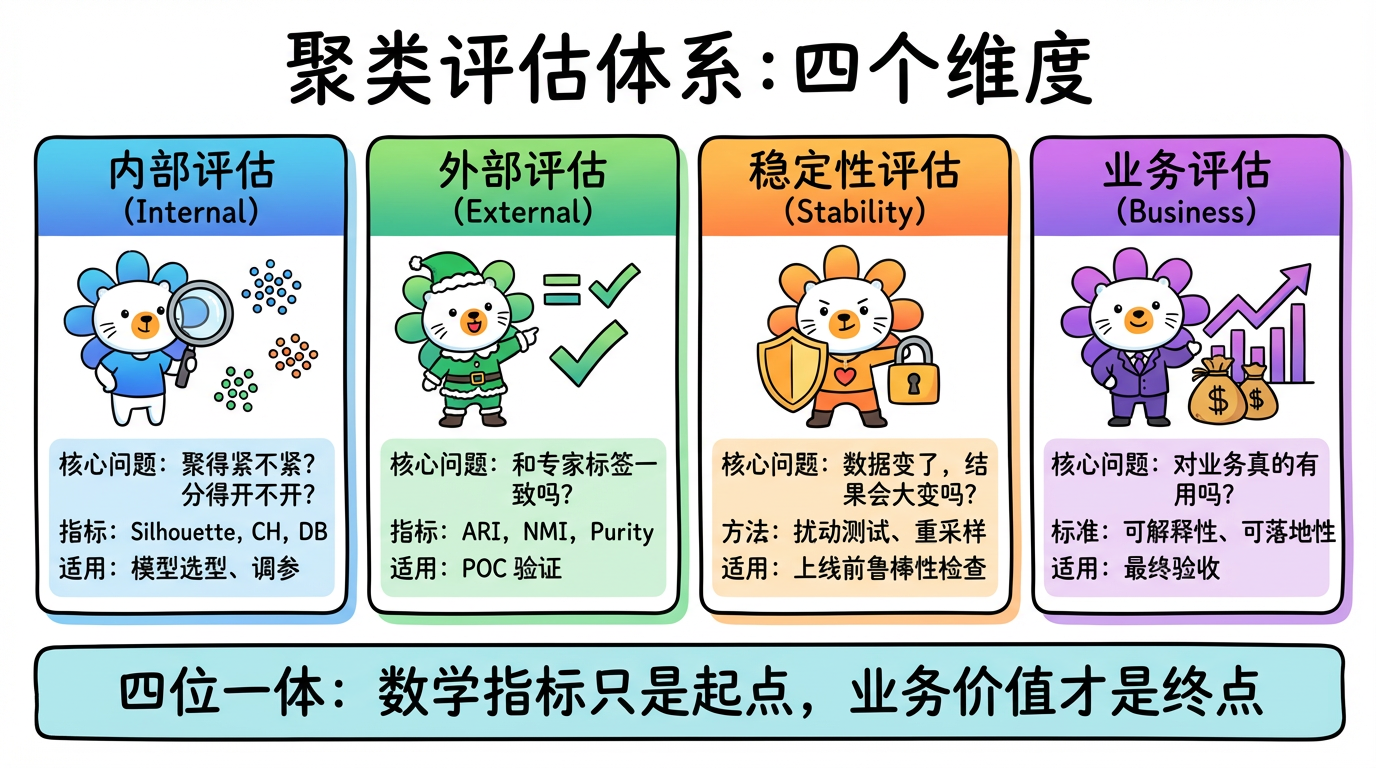
本章我们将介绍一套系统化的评估体系。既然没有外部答案,我们就从内部结构、稳定性、业务价值等多个维度来审视聚类结果。
(图注:聚类评估的四个维度:内部评估、外部评估、稳定性评估、业务评估。)
1. 评估体系概览 (The Evaluation Taxonomy)
聚类评估不仅仅是算一个分数,
第 08 章:概率模型聚类
“上帝不掷骰子,但数据科学家掷。” —— 改编自爱因斯坦
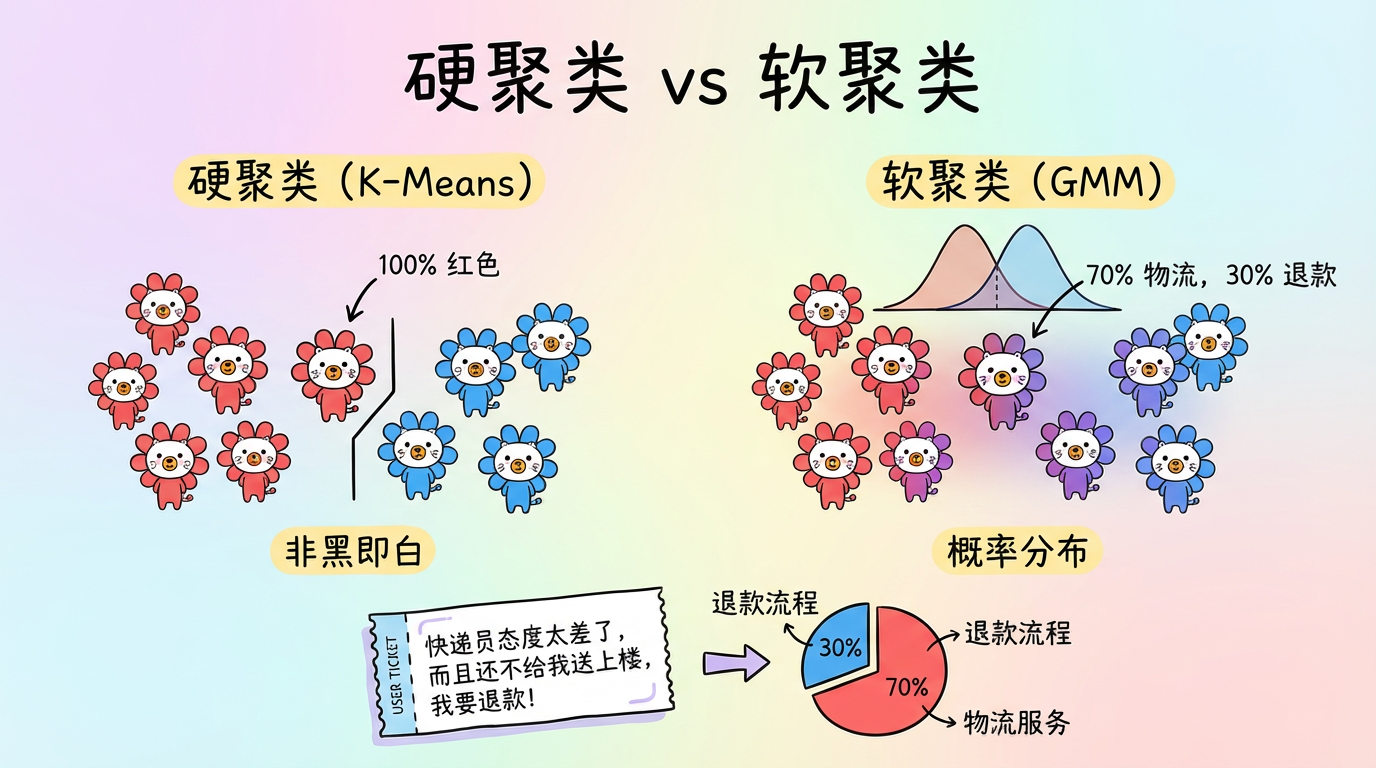
之前的聚类算法(K-Means, DBSCAN)都有一个共同特征:硬聚类 (Hard Clustering)。
一个样本要么属于 A,要么属于 B,没有中间地带。
这就像把人简单分为“好人”和“坏人”,丢失了人性的复杂灰度。
在实际的文本分析场景中,我们经常遇到这种情况:
用户工单:”快递员态度太差了,而且还不给我送上楼,我要退款!”
这句话既涉及【物流服务】,又涉及【退款流程】。如果硬把它归为某一类,就会丢失另一半信息。
本章我们将介绍 高斯混合模型 (GMM, Gaussian Mixture Model),它引入了 软聚类
第 07 章:层次聚类
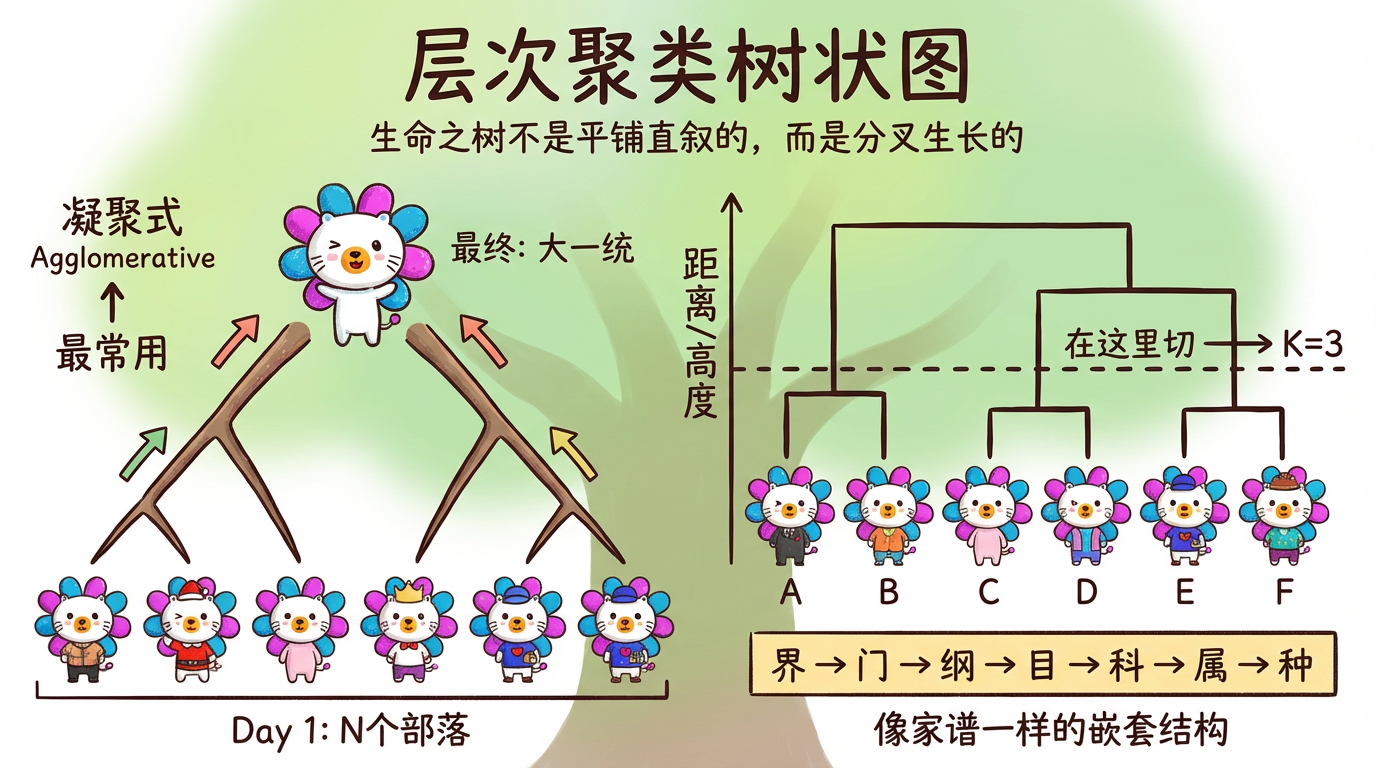
“生命之树不是平铺直叙的,而是分叉生长的。”
K-Means 给了我们一张扁平的地图:这一块是中国,那一块是美国。在地图上,北京和上海是平级的城市。
但生物学家看世界的眼光不一样。他们会给你画一棵树:
* 所有动物 -> 脊索动物 -> 哺乳动物 -> 食肉目 -> 猫科 -> 家猫。
这种层层嵌套的结构,往往比扁平的分组包含了更丰富的信息。比如,我们不仅想知道“这个客户属于高价值客户”,我们可能还想知道“在高价值客户里,他又属于偏爱理财的那一小撮”。
本章我们将介绍 层次聚类 (Hierarchical Clustering)。它不需要你痛苦地纠结 K 到底是 5 还是 6。它会



