
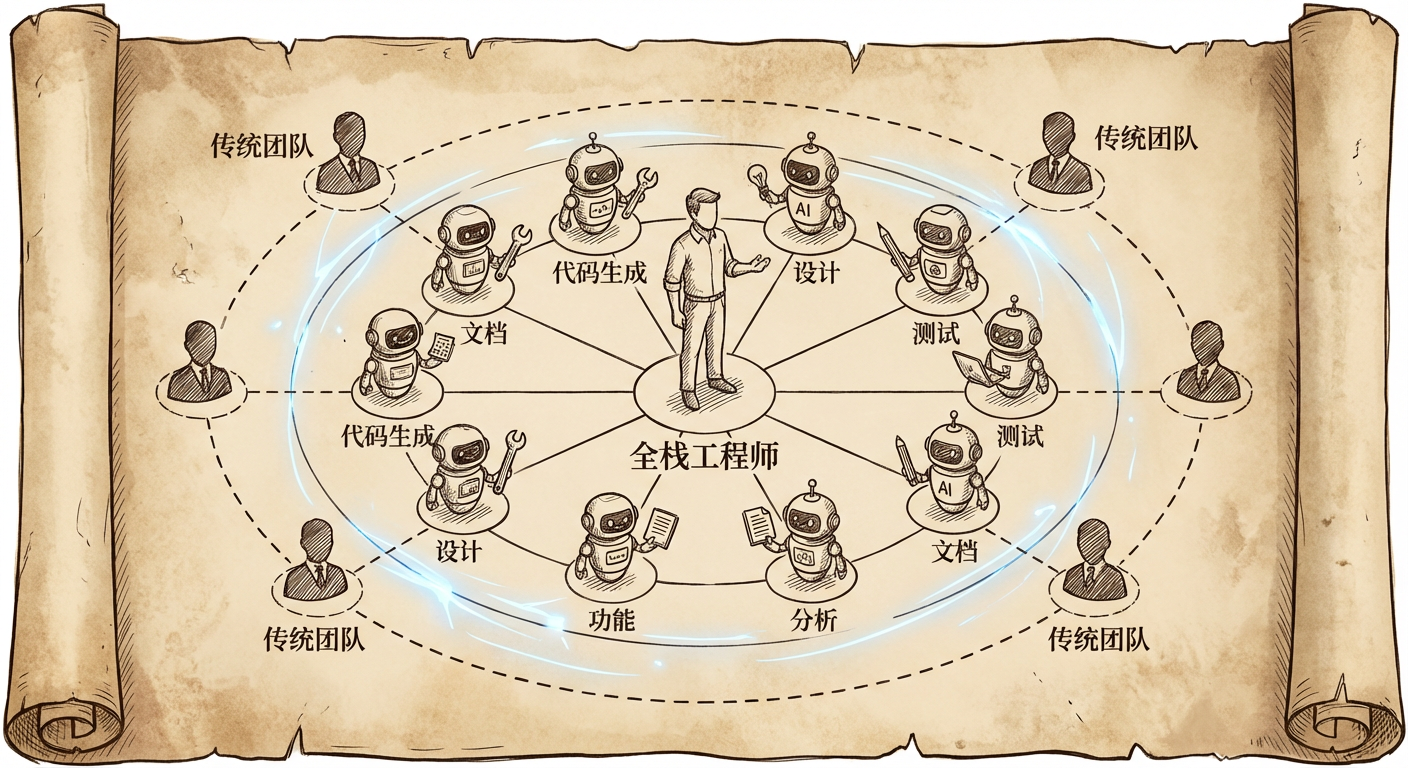
10X AI 全栈工程师的进化之路
内网文档 - 全栈手册)
👆🏻 全栈手册,是我在近期全栈化转型过程汇总梳理的较为结构化、系统性的知识库手册,希望能够对后来人有所帮助。
自我介绍:
1. 还是前端的我,目前负责 Lazada B 端前端基建,Merlion UI (UI 框架)) 作者,LAGO (页面发布平台))、Lazada Material (物料平台)) 等平台主要设计者及维护人,维护 Lazada 商家工作台 Node.js 应用(1000+ QPS)。
2. 开始转 Java 全栈的我,不到 4 个月被紧急成长完成了 Java 迭代需求 30+,主导大型重点项目 —— 智能审核(40 人日以上)交付
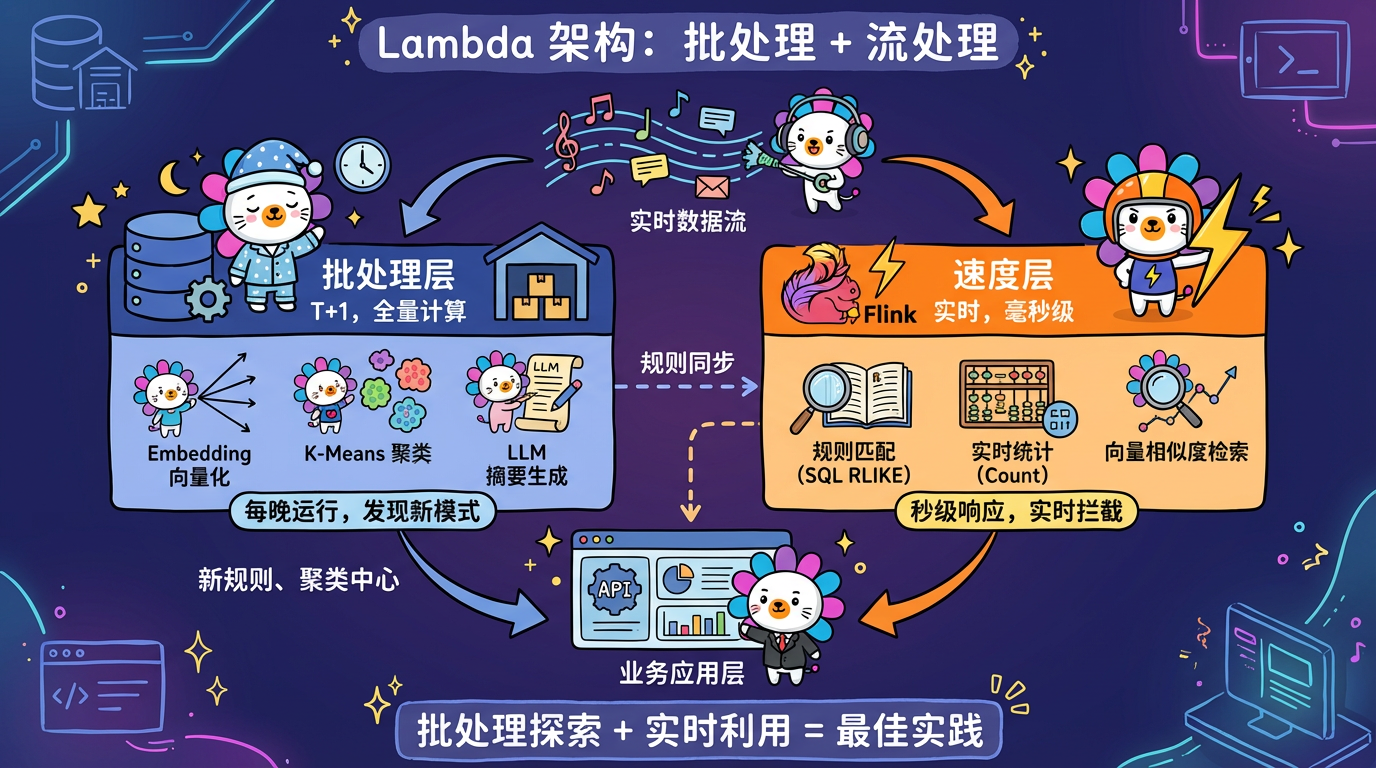
第 20 章:系统架构与工程实践
“算法只是冰山一角,工程才是水面下的巨兽。”
恭喜你,你已经掌握了无监督学习的所有核心算法。
但在实际工作中,写出算法代码可能只占 10% 的时间。
剩下的 90% 时间,你在处理:数据管道、异常恢复、性能优化、成本控制。
本章将以一个典型的文本分析系统为例,剖析工业级数据挖掘系统的架构设计。
1. 核心概念:批处理 vs 流处理
1.1 批处理 (Batch Processing)
* 模式:T+1。每天凌晨把昨天的数据全量跑一遍。
* 适用:Embedding, KMeans, LLM 总结。这些算法很重,没法实时跑。
* 常见选择:文本分析系统通常采用批处理。因为”风险挖
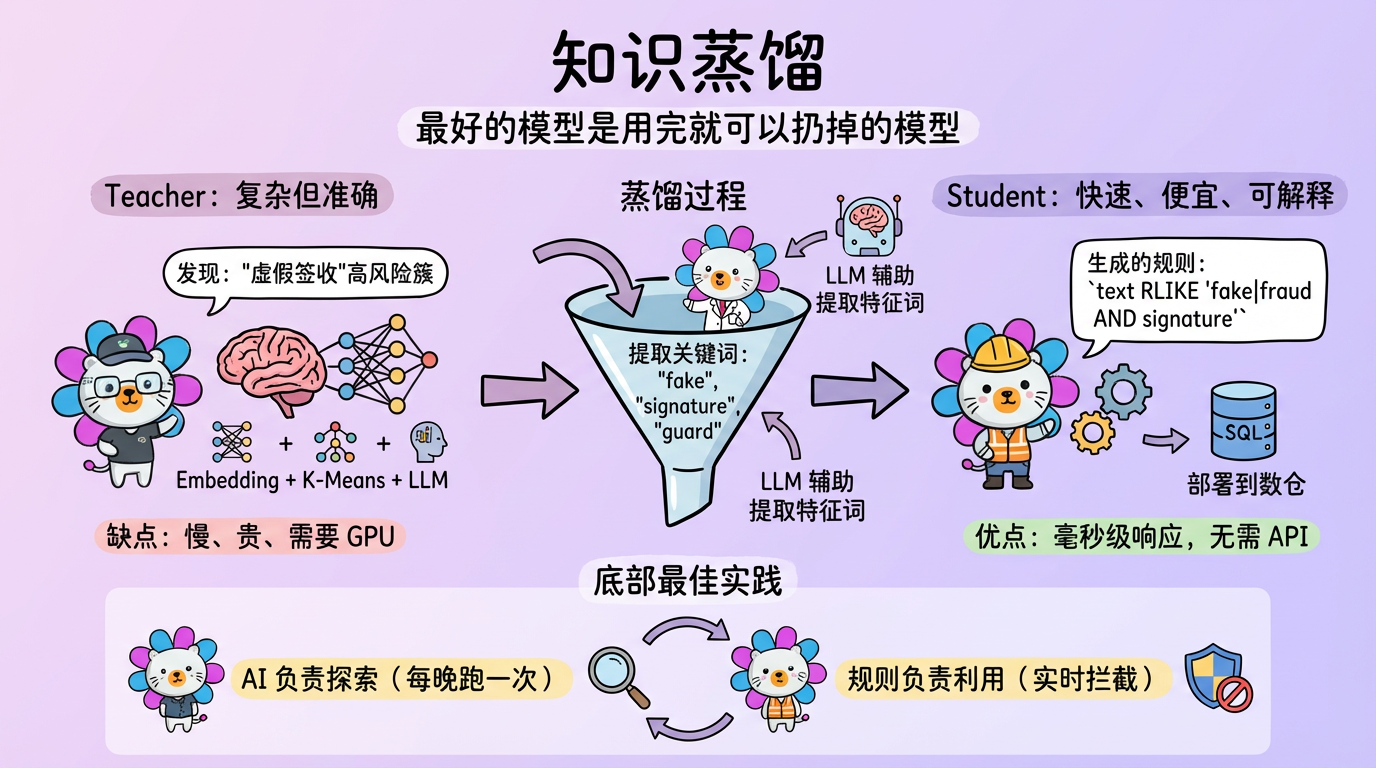
第 19 章:从模型到规则:知识蒸馏
“最好的模型,是用完了就可以扔掉的模型。”
在 Python 里跑完聚类和 LLM 之后,我们得到了深刻的洞察。
但 Python 脚本难以处理亿级的实时数据流。
我们需要把 Python/AI 学到的知识,转移到更轻量级、更高效的系统(如 SQL 引擎、规则引擎)中去。
这一过程被称为 知识蒸馏 (Knowledge Distillation),或者更具体地说,规则提取 (Rule Extraction)。
1. 核心概念:Model-to-Rule
1.1 为什么需要规则?
1. 性能:SQL RLIKE 比 Embedding 快一万倍。
2. 成本:不需要调 API,不需
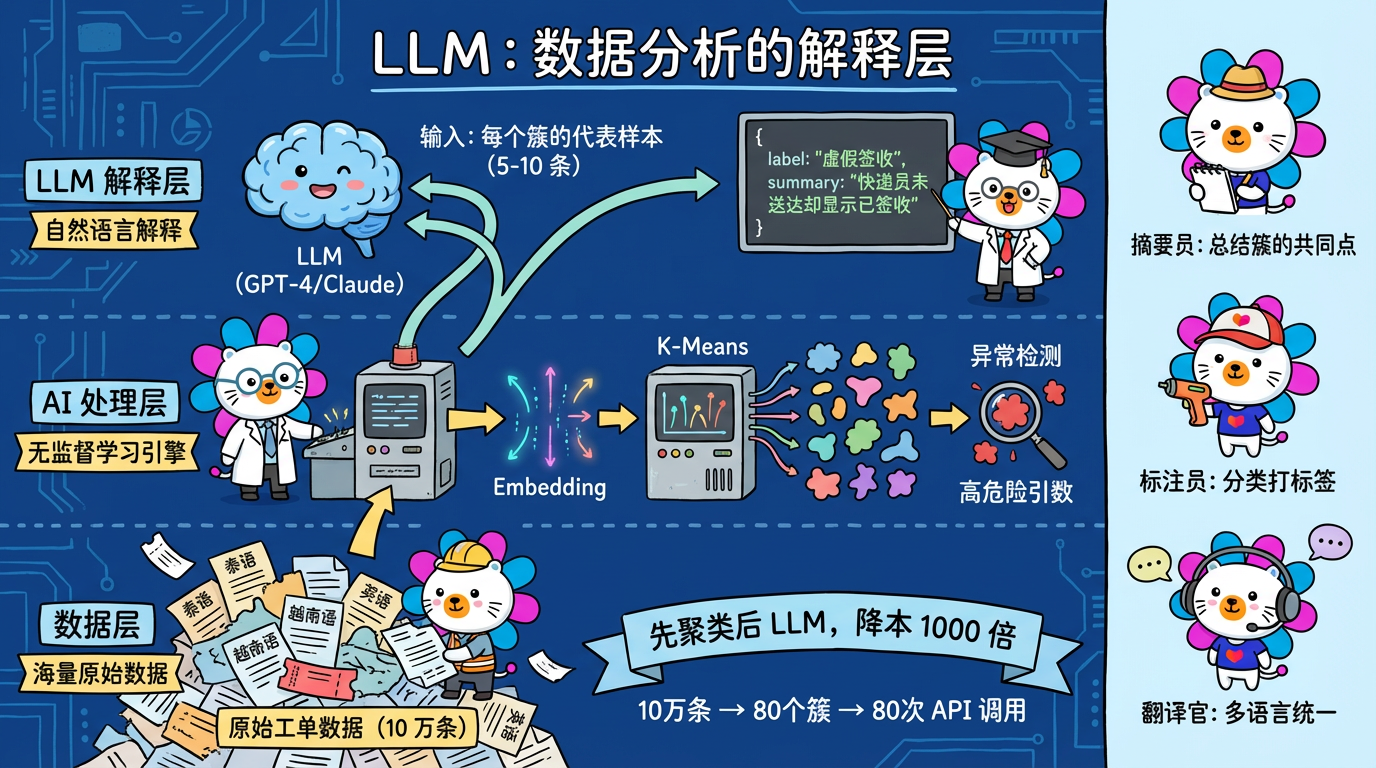
第 18 章:大语言模型在数据分析中的应用
“以前我们教机器学数学,现在我们教机器读课文。”
在传统的无监督学习流程中,最大的痛点是“结果不可读”。
* 聚类结果:Cluster_42。
* 异常结果:Anomaly_Score = 98.5。
* 业务人员:???
在大模型 (LLM) 时代,我们有了一种全新的范式:使用 LLM 作为这一流程的“解释层” (Interpretation Layer)。
1. 核心概念:LLM 的三种角色
在数据分析链路中,LLM 可以扮演三种角色:
1.1 摘要员 (Summarizer)
这是最基础的用法。
* 输入:Cluster 42 中的 50 条工单文本。
* Pr
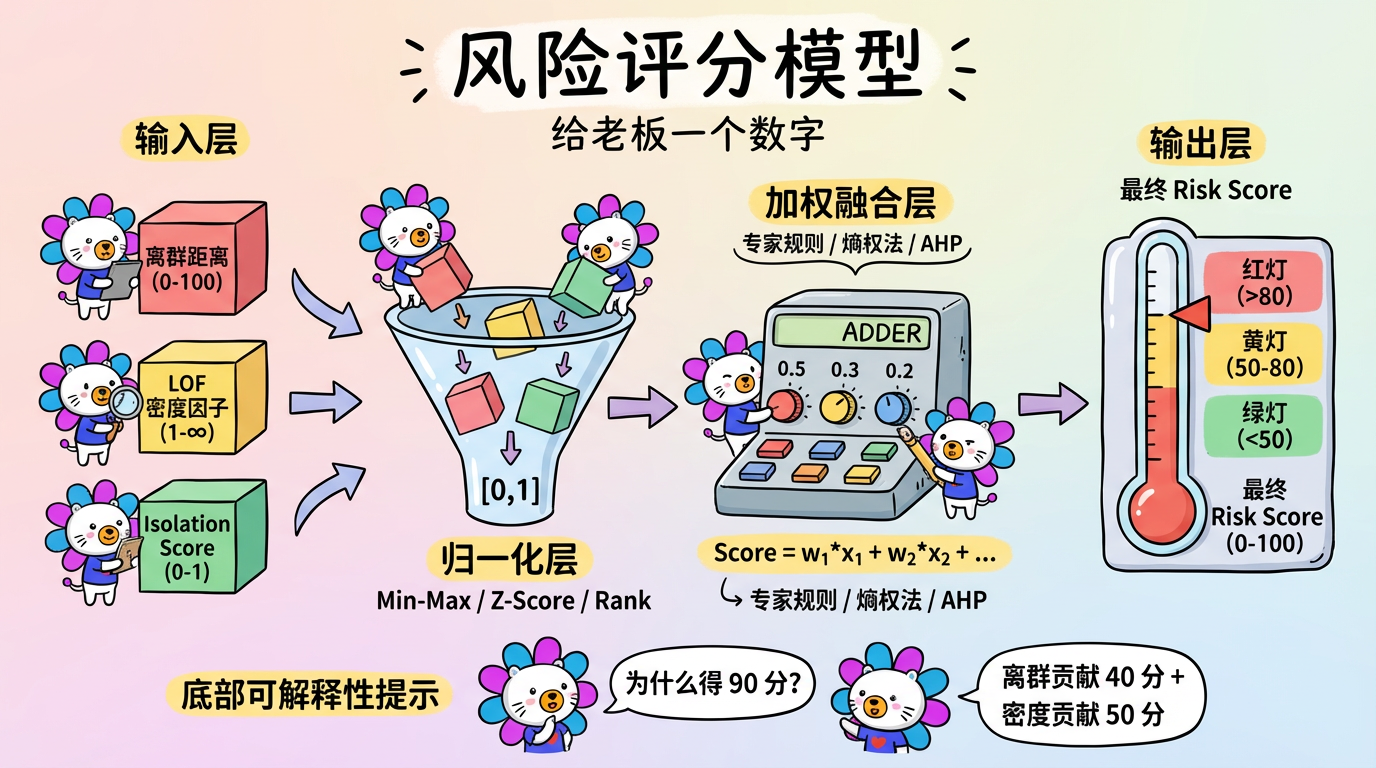
第 17 章:风险评分模型设计
“给我一个数字,我就能撬动地球。—— 前提是这个数字已经归一化了。”
在前面的章节中,我们学习了各式各样的异常检测算法,它们会吐出各种数字:
* K-Means:离群距离 (Distance)。单位可能是米、元、或者抽象的欧氏距离。
* LOF:局部离群因子 (Factor)。通常大于 1,没有上限。
* Isolation Forest:异常概率/分数 (Score)。通常在 0 到 1 之间。
但老板和业务方不想看这些天书。他们只想知道:
“这个用户的风险是 85 分(高危),还是 20 分(安全)?”
这就需要我们构建一个 风险评分模型 (Risk Scoring Mode



