
第 02 章:文本表示学习:从词袋到Transformer
“语言是人类思想的密码,Embedding 是解开这道密码的钥匙。”
1. 导言:计算机不懂泰语
在多语言文本分析场景中,我们面临的第一个挑战是语言的巴别塔。
用户的抱怨五花八门:
* 英文: “Where is my package?”
* 泰文: “พัสดุอยู่ที่ไหน?”
* 印尼文: “Di mana paket saya?”
虽然字面完全不同,但它们的意思是一模一样的。
如果我们直接把这些字符串丢给聚类算法,算法会认为它们是完全不相关的东西。因为它只能看到字符 W-h-e-r-e 和 พ-ั-ส-ด-ุ 的区别。
我们需要一种通用语言,把所有人类的语言翻译成计
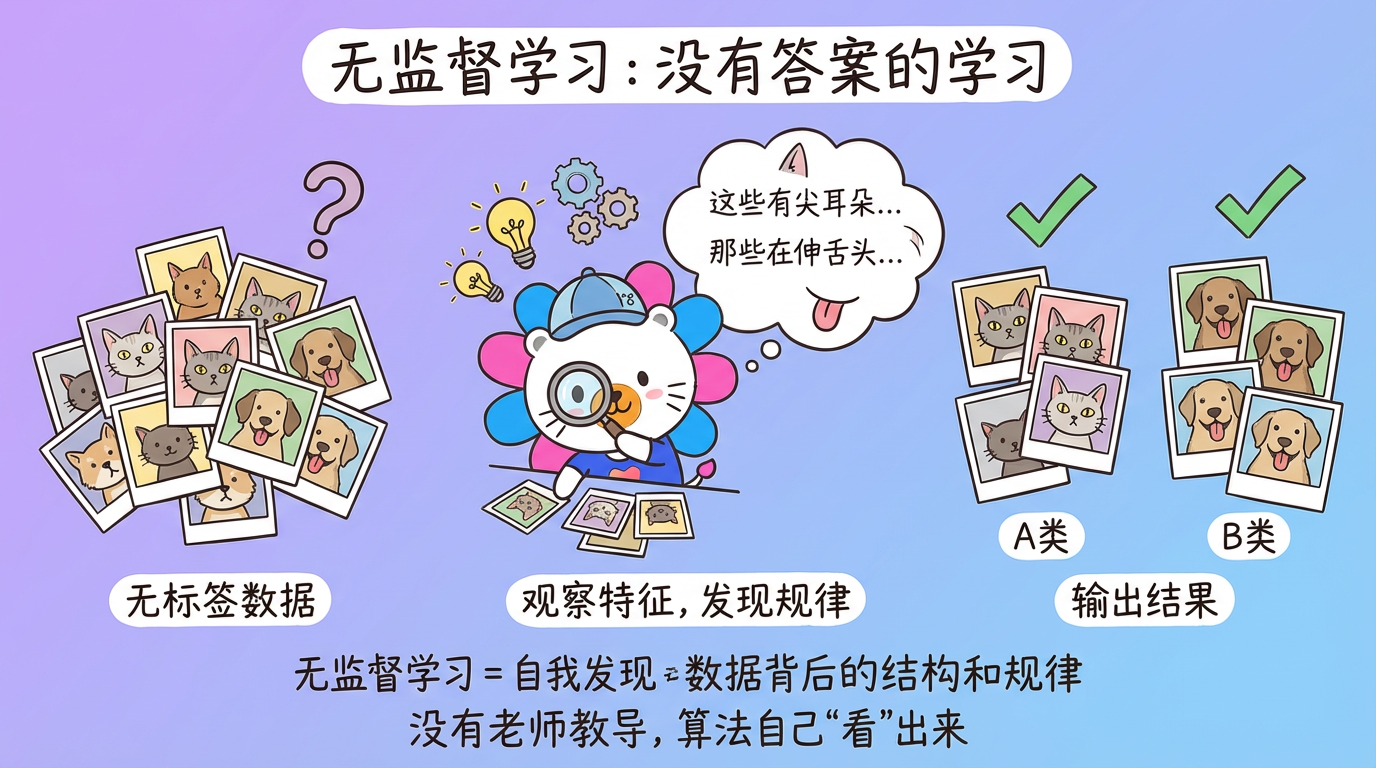
第 01 章:无监督学习导论
“如果智能是一块蛋糕,无监督学习就是蛋糕胚,监督学习只是上面的糖霜。” —— Yann LeCun (图灵奖得主)
1. 导言:寻找数据的”潜规则”
想象一下,你是一个刚到地球的外星人,手里只有一堆没有任何标签的照片。没人告诉你什么是”猫”,什么是”狗”。但你依然可以通过观察发现:有些照片里的小动物长着尖耳朵、瞳孔竖直(我们将它归为 A 类);有些照片里的动物体型较大、伸着舌头(归为 B 类)。
你不知道它们叫什么,但你已经学会了区分它们。这就是 无监督学习 (Unsupervised Learning) 的本质:在没有老师教导的情况下,自我发现数据背后的结构和规律。
本章我们将推开

现代前端演变
本文 500%+ 内容来自 AI 撰写,但绝不口水
现代前端开发体系远比传统网页制作流程复杂,已从最初的静态页面演变为高度模块化、工程化、自动化的开发范式。本文系统梳理现代前端渲染的基本原理,主要围绕:开发环境为何需要本地服务(如 Node.js)、现代前端框架(如 React)的技术演进与核心价值、代码编译与构建工具(如 Vite)的作用、热更新机制、代理与调试流程,并对比传统前端方案的弊端,明确现代前端复杂性的源头及其带来的显著优势。
1. 传统前端开发模式的局限性
1.1 技术架构概览
典型的技术栈包括:服务端采用 JSP/PHP/ASP.NET 等模板引擎,配合 Strut

琢磨一下 Monorepo
Monorepo 不是一个新话题了,这个概念最早被 Google 提出,指的是将所有项目代码(无论是前端、后端、库、工具等)集中存放到同一个仓库中,打个比喻就是把我们现在的 Java 应用、前端 JS 和组件库都放在同一个仓库中,再通过工程自动化在发布过程做分离。
发展到如今已经有非常多的公司采用这种方式进行该种方式管理代码,随后也发展出来非常多针对 Monorepo 场景下的工具链,如:Nx、Lerna、Turborepo
使用现状
Monorepo 在我们团队内部其实已经有许多项目已经在应用,为此我们还专门做过一期当前 Monorepo 解决方案的对比分享(😑 很遗憾没有做视频录制,

谈谈国内前端的三大怪啖
因为工作的原因,我和一些国外的工程师们有些交流。他们对于国内环境不了解,有时候会问出一些有趣的问题,大概是这些问题的启发,让我反复在思考一些更为深入的问题。
今天聊三个事情:
* 小程序
* 微前端
* 模块加载
小程序
每个行业都有一把银座,当坐上那把银座时,做什么便都是对的。
“ 我们为什么需要小程序?”
第一次被问到这个问题,是因为一个法国的同事。他被派去做一个移动端业务,刚好那个业务是采用小程序在做。于是一个法国小哥就在被痛苦的中文文档和黑盒逻辑中来回折磨着 🤦。
于是,当我们在有一次交流中,他问出了我这个问题:我们为什么需要小程序?
说实话,我试图解释了 19



