



核心观点:在 AI 的眼里,万物皆是坐标。RAG(检索增强生成)的本质,就是把用户的自然语言问题,映射到知识库的坐标系中,寻找最近的”邻居”。
1. 引言:计算机不懂中文,它只懂数学
你问 AI:”苹果怎么卖?”
在计算机底层,它根本不知道”苹果”是水果还是手机。
但如果你告诉它:”苹果”的坐标是 [0.8, 0.2],”香蕉”的坐标是 [0.85, 0.1],”卡车”的坐标是 [-0.5, 0.9]。
它会立刻计算出:苹果和香蕉很近,离卡车很远。
这就是 Embedding(向量化) —— 它是 RAG 系统地基中的地基。
2. 核心概念:Embedding Space (向量空间)
2.1 把意义数字化
Embedding 就是把一段文字变成一串数字(向量)。
这串数字厉害的地方在于,它捕获了语义(Meaning)。
💡 比喻:想象一个巨大的宇宙图书馆。
这里的书不是按字母排列的,而是按内容相似度悬浮在空中的。
- 讲”烹饪”的书聚成一个星云。
- 讲”编程”的书聚成另一个星云。
Embedding 模型就是一个图书管理员,它读完一句话,就给它贴上一个 GPS 坐标
(x, y, z...)。
3. 技术解析:向量数据库与检索
3.1 怎么找得快?(ANN Search)
当你有 100 万条文档时,如果每一条都去算距离(暴力计算),速度会慢到不可接受。
我们需要 ANN (Approximate Nearest Neighbor,近似最近邻搜索)。
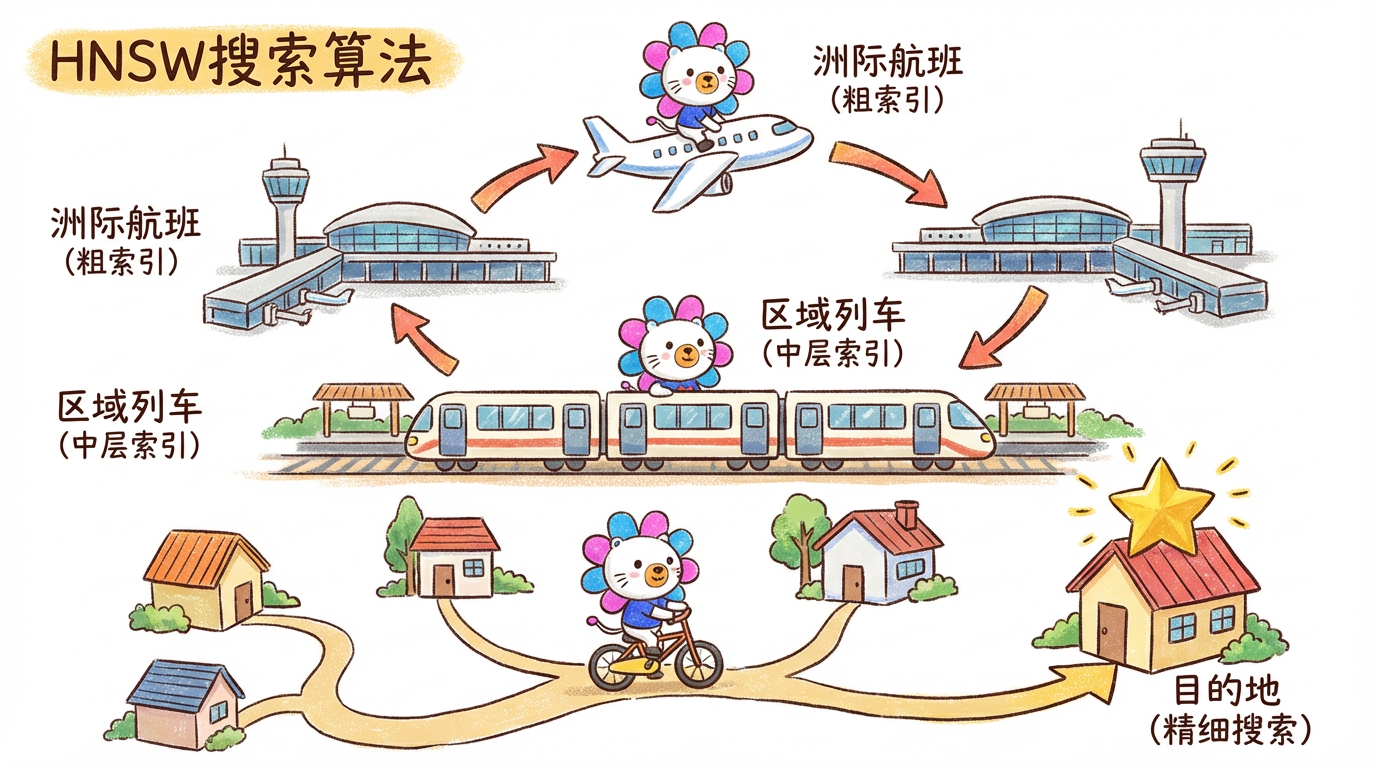
HNSW (Hierarchical Navigable Small World) 是目前的王者算法。
- 原理:跳表(Skip List)+ 图结构。
- 比喻:坐高铁。先做洲际高铁(顶层索引)快速到达区域,再换城际列车(中层),最后骑共享单车(底层)找到具体的门牌号。
3.2 文本切分 (Chunking) 的艺术
存入向量库前,必须把长文档切成小块(Chunk)。
切分策略直接决定 RAG 的生死。
- Fixed Size: 机械地按 500 字一刀切。简单,但容易把一句话切断。
- Recursive: 按段落、句子层级递归切分。推荐。
- Semantic: 按语义变化切分(高级)。
4. 工业实战:选型与避坑
4.1 Embedding 模型选型
不要只盯着 OpenAI 的 text-embedding-3。中文场景下,开源模型往往更强。
| 模型 | 厂商 | 特点 | 适用场景 |
| :— | :— | :— | :— |
| BGE-M3 | BAAI (智源) | 多语言、多功能、长文本。目前的六边形战士。支持 Dense/Sparse/ColBERT 三种检索。 | 中文首选,通用场景 |
| text-embedding-3-large | OpenAI | 方便,维度可变。但在中文特定领域微调能力不如 BGE。 | 快速验证,不想自己部署 |
| Jina-Embeddings-v3 | Jina AI | 针对长文本优化,支持 8k 长度。 | 需要处理长合同、长研报 |
4.2 常见坑点
- 切分太碎:导致上下文丢失。”他被捕了。” —— 谁被捕了?前面那块没切进来。
- 解法:增加 Overlap (重叠窗口),比如切 500 字,重叠 50 字。
- Top-K 幻觉:强行召回了不相关的文档,LLM 只能一本正经地胡说八道。
- 解法:设置 Similarity Threshold (相似度阈值),低于 0.6 的直接丢弃。
5. 总结与预告
- 本章总结:
- Embedding 将语义转化为坐标。
- HNSW 算法让我们能在亿级数据中毫秒级检索。
- BGE-M3 是目前中文开源界的必看模型。
- 下章预告:
虽然向量检索很强,但它经常”脸盲”,分不清”人咬狗”和”狗咬人”(因为词差不多)。下一章《RAG 进阶:重排序与混合检索》,我们将引入一位严厉的审核员——Rerank 模型。



