



核心观点:在大模型推理中,搬运数据的时间远多于计算的时间。推理优化的核心战役,就是打破”内存墙”(Memory Wall)。
1. 引言:你的显卡为什么在”摸鱼”?
你买了昂贵的 RTX 4090,跑大模型时却发现 GPU 利用率只有 30%?
不要怪显卡,它很委屈。
它就像一个米其林三星大厨(Tensor Core 计算核心),切菜速度极快,但他必须等服务员从几公里外的仓库(显存 VRAM)把土豆一个一个搬过来。
大模型推理的瓶颈,通常不在算力(Compute Bound),而在显存带宽(Memory Bound)。
2. 核心概念:内存墙与 KV Cache
2.1 显存:寸土寸金的仓库
大模型推理时,显存主要被两样东西占据:
- 权重 (Weights):模型本身的参数。死沉死沉的,动辄几十 GB。
- KV Cache (键值缓存):对话的历史记忆。
2.2 KV Cache:不要重复造轮子
Transformer 生成每一个 Token 时,都需要回头看前面的所有内容。如果每次都重新计算前面所有字的 Attention,速度会越来越慢($O(n^2)$ 复杂度)。
KV Cache 的策略是:算过的就存下来!
但代价是:显存爆炸。上下文越长,KV Cache 越大,甚至超过模型本身。
💡 比喻:想象你在考试。
- 不带 Cache:做第 10 题时,把第 1-9 题重新做一遍,再做第 10 题。
- 带 Cache:把 1-9 题的草稿纸(KV Cache)留着,直接引用,只算第 10 题。
- 代价:桌子(显存)很快就被草稿纸堆满了。
3. 技术解析:量化 (Quantization)
既然显存不够,带宽不够,最直接的办法就是:把数据变小。这就是量化。
3.1 精度压缩
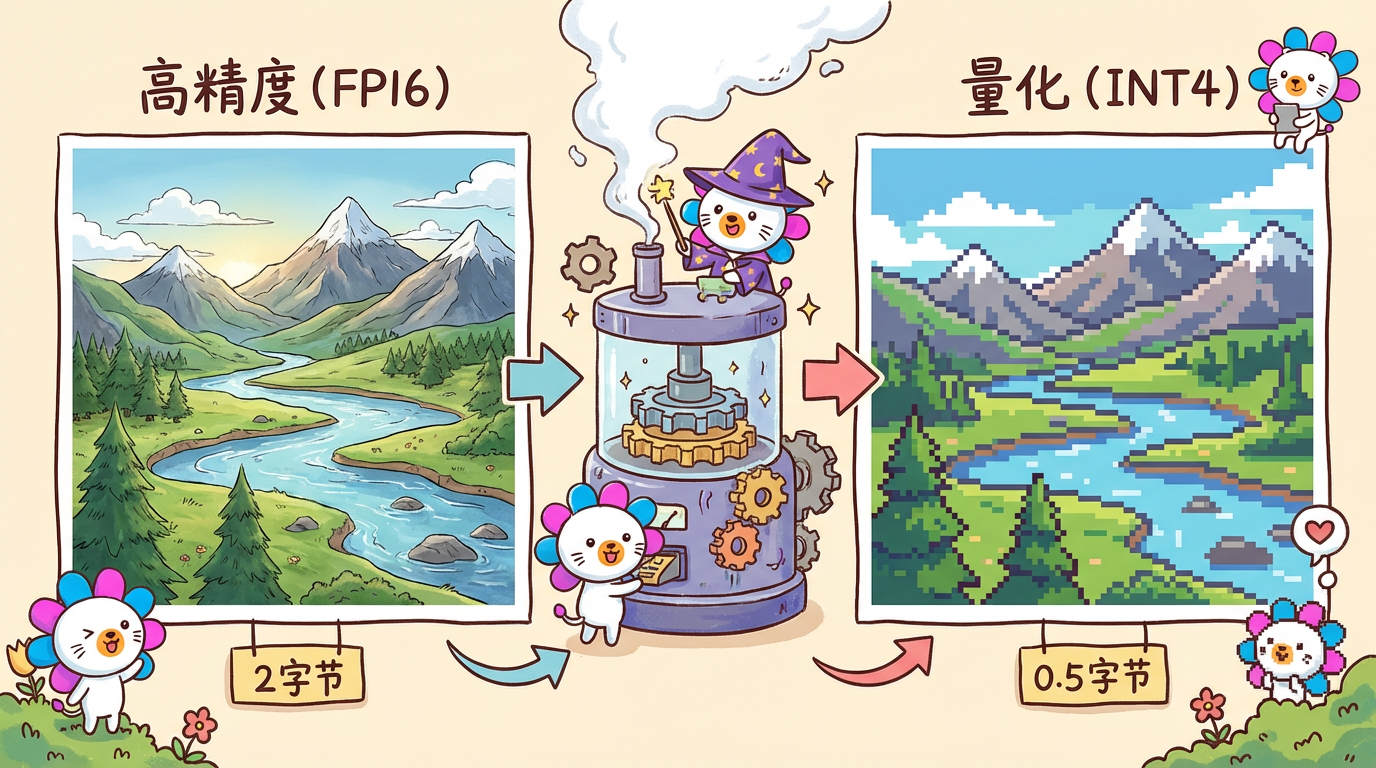
原始模型通常是 FP16(16位浮点数),就像高精度的矢量图。
量化把它变成 INT8 或 INT4(4位整数),就像像素风格的图片。
- FP16:
0.123456789(占用 2 字节) - INT4:
0.1(占用 0.5 字节) -> 显存占用直接砍到 1/4!
3.2 惊人的发现
神奇的是,大模型往往存在大量的冗余。即使把精度砍到 4-bit,模型的”智商”(PPL, Perplexity)几乎不下降!
4. 工业实战:量化格式选型
市面上有各种量化格式,怎么选?
| 格式 | 全称 | 特点 | 适用场景 | 推荐指数 |
|---|---|---|---|---|
| GGUF | GPT-Generated Unified Format | CPU/GPU 混跑神器。llama.cpp 生态,兼容性极强(Mac, 安卓, 树莓派)。 | 本地部署、Mac M系列芯片、低配机器 | ⭐⭐⭐⭐⭐ |
| AWQ | Activation-aware Weight Quantization | 保显存精度高。保护关键权重,边缘端推理速度快。 | 生产环境 GPU 推理 (vLLM 支持好) | ⭐⭐⭐⭐ |
| GPTQ | GPT Quantization | 老牌强者,但逐渐被 AWQ 取代。 | 旧版本项目维护 | ⭐⭐⭐ |
| EXL2 | ExLlamaV2 | 速度之王。专为现代 NVIDIA 卡优化,动态混合精度。 | 追求极致速度的发烧友 | ⭐⭐⭐⭐ |
工程师建议:
- 如果你用 Mac 或者想在笔记本上跑:无脑选 GGUF。
- 如果你在服务器上部署 API (使用 vLLM):首选 AWQ。
5. 总结与预告
- 本章总结:
- 推理的本质是搬运数据,带宽是最大瓶颈。
- KV Cache 用空间换时间,是长文本的关键。
- 量化(尤其是 4-bit)是目前性价比最高的优化手段。
- 下章预告:
搞定了模型和算力,如果模型还是不知道公司的内部文档怎么办?下一章《RAG 基石:Embedding 与向量检索》,我们将给模型”外挂”一个知识库。



