



@vmojs/decorator 一个帮助你更好,更快地创建前端数据模型的工具库,可以让你对数据处理过程更加简单,更加灵活。
关于前端使用数据模型这个话题我已经写过很多次相关的介绍,并且也确实在我们的业务项目里面实践过非常多的成功案例。经过一开始的 @vmojs/core 的继承数据模型到现在的 @vmojs/decorator 纯粹装饰器模式使用,期间有过很多次思考和打磨,接下来我想再次聊聊前端的数据模型应用和前端面向对象编程这个话题。
首先,面向对象的设计模式在一切复杂系统设计中都是被无数次验证过的成功经验,而在当代 Hooks 盛行的前端年代里,是否就代表着我们不再需要面向对象的设计模式了?是否代表着曾今盛行的 Class 不再有价值了?
为何弃 Class
先来看看,现在React Hooks 及 Vue 3 的 Composition API 在解决什么问题?或者说,聊聊它们为什么这么受欢迎?
写起来简单
首先不可否认的是,相比于Class写法来说,Function确实更像是无感的定义了一个函数。相对于沉余的定义 继承、渲染、生命周期、状态 来说,它确实非常轻便的就可以完成一个组件的开发。
在关于TypeScript的定义中,也能明显感觉到,如果使用Class开发过相对健全的组件的同学一定知道以下这些React定义的以供其上下文通信及校验的组件属性:
React.Component<IProps, IState>Component.defaultPropsComponent.propTypesComponent.contextTypeComponent.childContextTypesComponent.getChildContext
这些方法在TypeScript类型定义的推导中真是要折磨死人,常常要各种类型断言才能继续下去。关于类型校验,书写完ts的类型再书写propTypes的类型更像是在写食之无味的八股文,让人无奈抓狂。
而Function的写法则充分利用了ts的函数推导过程,让其类型仅需定义一次,纯粹借助ts的类型推断来进行组件入参声明,这极大程度的减轻了开发者在这类重复定义上的开发和维护工作。
用起来简单
Hooks 提供将 逻辑与状态 独立抽离的的复用能力。
之前这种能力大多以Mixin、HOC等形式被使用于各类渲染引擎或系统设计中。这种设计从使用的角度来看,确实能够达到部分逻辑复用和部分组件交互相同的效果。但是,也为调试过程带来了非常大的难度,我曾经就在一个基于HOC设计的渲染引擎中寻死觅活,因为有近 8 层HOC来处理一个组件渲染所需的不用表现逻辑,乍一看上去似乎是分层合理,逻辑清晰。但实际上在使用反面会带来以下几个问题:
- 消费黑盒,高阶函数往往会在组件渲染过程中消费一些
Props,甚至偷偷吃掉一些Props,开发者遇到一些Props下传后渲染异常,往往需要花很长时间才能找到问题是出现在哪一层 - 组合性差,一开始设计高阶函数的过程中往往会觉得其灵活性、复用性应该都会非常高,只需要让组件包裹一下就可以复用这部分逻辑能力。但是,这种迭代器模式的设计,如果多个
HOC组合使用,往往会存在前后依赖关系,这为使用过程中带来了极大的隐患 - 嵌套地域(Wrapper Hell),在 React Devtools 查看和调试某个组件的时候十分困难抓狂,感受一下
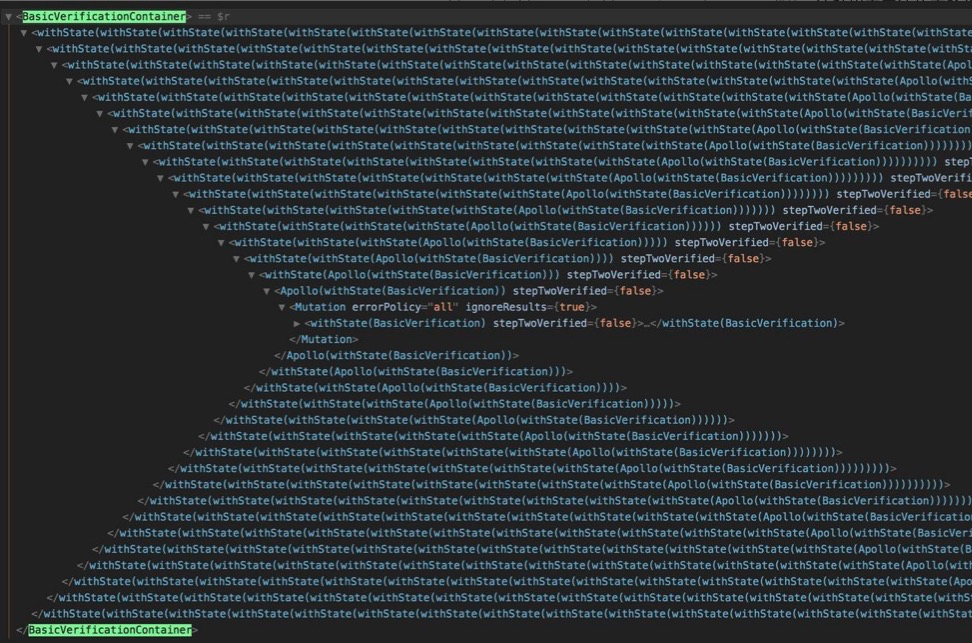
而 Hooks 则很好地解决了这些问题,借助一个状态的封装和组合,我们可以将一系列需要对状态做处理的逻辑抽象,其组合模式更加灵活,只需开发者理解 React Hooks 组件渲染周期的概念即可无副作用的进行不同状态逻辑组合。
理解起来简单
Hooks 的封装 和 组件封装 都是用Function的调用方式,开发者可以一眼看明白其入参出参,Component 与 Hooks 的区分也相对比较明确,分别以 useXXXX 和 Cxxxxx 区分。
总体来说相对与Class方式的复用逻辑抽象,Function的这种方式确实更加简洁和易理解一些。
为何留 Class
刚刚描述了为什么在前端主流的框架中逐步放弃了Class,但我这里主要想讲的内容是当前的前端项目中,为何需要留Class,主要能解决一些什么问题。
首先,我们看下为什么主流的服务端框架都是在使用Class为基础的方式展开系统设计:
数据实体化
利用Class定义,我们可以将传输过程中一个定义模糊的数据内容,转换为一个字段明确、类型明确的类,从而完成安全调用,清晰处理数据流转关系。
怎么理解上面这句话呢,我稍微举几个简单的例子:
比如我们需要渲染一张订单表格,假如拿到的数据如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
[
{
"buyerAvatar": "https://xxxxxx.cdn.com/avatar.png",
"buyerId": 1000001,
"createTime": 1637230483,
"orderNumber": "60000000000001",
"orderType": "Normal",
"preOrder": false,
"shippingFee": 1.49,
"deliveryType": "STANDARD",
"buyerName": "today",
"freeGift": false,
"skus": [
{
"createTime": 1637230483,
"createDate": "10 Sep 2021",
"image": "https://xxxxxx.cdn.com/product.png",
"itemStatus": "repacked",
"orderItemId": "60676801622031",
"orderType": 0,
"skuName": "商品名称 - black",
"productTitle": "商品名称",
"quantity": 1,
"skuId": "test0000001-black",
"skuInfo": "1:black",
"unitPrice": "200.00"
}
],
"status": "topack",
"totalQuantity": 1,
"totalRetailPrice": "0.00",
"totalUnitPrice": "200.00"
}
]这样一份数据当前端拿到的时候,会存在以下几个问题:
- 无法非常直观的看到其所描述数据内容,每个字段需要有过一遍校对理解后才能使用
- 无法清晰看到其所描述数据之间的关联关系,在获取信息过程中无法通过类型清晰理解
- 当存在多个数据的联合判断界面中某些交互时(如 tabStatus 为 unpack 时,显示某个 action),这类判断逻辑在渲染过程会显得格外臃肿,在调试排查中也很难溯源
当然对于前端数据解析和使用过程中,其实还是有非常非常多让前端开发者无奈和吐槽的点。
实际上,这些问题其实是针对数据处理的问题。而面对这些问题,常年和数据打交道的服务端同学是如何做的呢?
Class 、数据模型自然而然的呼之欲出,来看看上面这个内容在数据模型的处理方式是如何的:

首先上面较为模糊的数据经过前端实例化转换将会变成上面这样较为清晰的数据结构,建议对比数据多看两边这个图
然后在数据方面使用就会变得非常通透,比如一个订单字母表渲染所需要的数据便是:
1
2
3
4
5
6
interface List {
list: Order[];
pageSize: number;
total: number;
current: number;
}因为是一个实体类的缘故,在数据消费过程中,会变得异常清晰。
遇到需要扩展计算的数据处理时,在对应模型下进行方法扩展也变得顺理成章。
装饰器
众所周知,ES7 关于 JS 装饰器的提案通过后,@Xxxx 装饰器这个能力已经被各大主流服务端框架积极采纳利用,比较有代表性的如:Midway、Nest.js
借助装饰器及类元数据进而衍生借鉴的依赖注入等设计模式,已经将服务端数据、服务、消费灵活组合玩的淋漓尽致。
以前需要借助各种目录规定定义、甚至特殊命名规则定义来完成相互调用和组合,现在只需要按照不同装饰器进行修饰就可以在项目任意位置进行自由组合,不得不说在这服务端数据传输,服务调用具有非常划时代性的意义。
TypeScript
TypeScript 作为微软推出的编译态类型语言,在当今各大主流框架和前端社区中都非常受欢迎。
大家知道在微软的项目中是非常推崇Class模式的,诸如:Vscode、Monico Editor,如果开发过相关 vscode 插件 的同学会很明显地感受到,关于类的概念在微软内部是流淌在血液里面的。
甚至从某种意义上来说TypeScript就是微软不满足于当前JavaScript对类、类型的支持,从而扩充出来的一套语法超集。借助这套超集才能助力微软利用 JS 能力完成像Vscode这么复杂又稳定的项目。
所以,TypeScript 对于类的支持就像是自家儿子一样,不能更了解。
使用类定义的数据模型在TypeScript使用起来,会给你如沐春风一样的感觉,你要写什么编辑器就好像都知道一样。
近期结合 Github Copilot 用起来,更是感觉只要定义好数据模型,写什么函数给一行注释就够了 😂
为何做 Vmo
上面我已经讲了非常多,关于Class这个话题,当前社区发展的两个倾向,接下来我想聊聊我在项目中是如何实施结合的。
我始终认为这是两个领域上的领域优势,他们做解决的问题和处理的内容是不同的。
关于组件、对于界面渲染,有更优的、更简单的调用方式,有更加灵活的状态逻辑抽象方式,没有道理不用。所以 对于组件渲染,我用 React Hooks。
关于需要长期维护的数据处理、数据转换、数据消费,我选择用数据模型。
他们各司其职,相得益彰,在项目中可以相互印证,借助Context + Model 模式可以显著提升项目整体稳定性和维护性。
这么说来貌似是一种设计模式,一种编程习惯,为什么还需要 @vmojs/decorator 呢?
@vmojs/decorator 主要用来解决在数据初始化过程中,重复、无味地赋值过程,减少胶水代码。
比如我需要实例化一个Order类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Order {
id: string;
price: number;
status: EStatus;
skus: Sku[];
createTime: Date;
constructor(data: IRemoteOrderDTO) {
this.id = data.orderNumber;
this.price = data.totalUnitPrice;
this.status = data.status;
this.skus = data.skus.map((sku) => new Sku(sku));
this.createTime = new Date(data.createTime);
}
}
// new Order(data) => Order;利用 Vmo 就可以快速完成该赋值过程,并且在未来字段新增时,其字段赋值转换逻辑也都在一处。当模型规模增大时,也不想用上下翻找重复处理转换过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import { Vmo } from "@vmojs/decorator";
@Vmo()
class Order {
// 该定义为了 ts 代码提示
constructor(data: IRemoteOrderDTO) {}
@Vmo("orderNumber")
id: string;
@Vmo("totalUnitPrice")
price: number;
@Vmo()
status: EStatus;
@Vmo(({ skus }) => skus.map((sku) => new Sku(sku)))
skus: Sku[];
@Vmo(({ createTime }) => new Date(createTime))
createTime: Date;
}总结
从某种意义上来说,我们都是在一个江湖中,前端社区的发展也是这样,某个框架、某个设计模式、某个热度很高的开源项目都是无数个背后的思考结晶。
并不是某个框架就是权威,某种做法就是无懈可击,只是作者当时场景下的最佳实践,所以越是高明的开发者,越想要了解某项技术栈的发展史,这更有益于理解其背后所代表的思考、背后衍变所代表的趋势、背后所代表的江湖。
Anyway,本篇文章虽然是在介绍一个工具库,但大部分内容还是在说我对当前时代下,前端开发者对于数据处理的个人最佳实践分享。希望对你有帮助!😄



